Python-re模块
re 正则表达式
正则表达式是一种小型的,高度专业化的编程语言,在各种语言中都有涉及,在Python中,通过re模块实现。正则表达式模式被编译成一系列的字节码,然后由c编写的匹配引擎执行。
一、正则表达式的作用:
1、对字符串进行模糊匹配
2、对象就是字符串
二、字符匹配(普通字符,元字符)
1、普通字符:数字字符和英文字母和自身匹配
2、元字符: . ^ $ * + ? {} [] () | \ (11个)
调用方法:re.方法(‘规则’,‘匹配的字符串’) ## 可以匹配除了\n(换行符) 外的任意一个字符。
三、匹配规则则:
| . | 匹配任意字符,除了\n |
| \ | 转义字符 |
| [] | 匹配字符集 |
| \d | 匹配任意十进制数,相当于[0-9] |
| \D | 匹配任意非十进制数,相当于[^0-9] |
| \s | 匹配任何空白字符,它相当于[\t\n\r\f\v] |
| \S | 匹配任何非空白字符,它相当于[^\t\n\r\f\v] |
| \w | 匹配任何数字字母,相当于[a-zA-Z0-9] |
| \W | 匹配任何非数字字母,相当于[^a-zA-Z0-9] |
| * | 匹配前一个字符0或无限次 |
| + | 匹配前一个字符1次或无限次 |
| ? | 匹配前一个字符0次或1次 |
| {m}{m,n} | 匹配前一个字符m次或最少m次最多n次 |
| *? | 匹配模式变为非贪婪模式(默认都是贪婪模式) |
| ^ | 匹配字符串开头,多行模式中匹配每一行的开头 |
| $ | 匹配字符串结尾,多行模式中匹配每一行的结尾 |
| \A | 仅匹配字符串的开头 |
| \Z | 仅匹配字符串的结尾 |
| \b | 匹配一个单词的边界,也就是指单词和空格间的位置 |
| | | 或者 |
| (ab) | 括号中的表达式最为一个分组 |
| \<number> | 引用编号为num的分组匹配到的字符串 |
| (?P<key>value) | 匹配到一个字典, |
| (?P=name) | 引用别名为name的分组匹配字符串 |
四、举例:
findall()用法:找到匹配,返回所有匹配部分的列表
1 s = 'jerry22jack23tom24' 2 print(re.findall('\d+',s)) 3 4 --------->输出 5 6 ['22', '23', '24'] #列表的形式显示
1 print(re.findall('j...y',s)) # . 的作用:匹配任意一个字符 2 3 --------->输出 4 5 ['jerry']
1 print(refindall('I','I im LIst') 2 3 ------->输出 4 5 ['I','I']
1 re.findall("d*","adsxaeddddddddddddyxsk19arrx") 2 3 ----------->输出 4 5 ['', 'd', '', '', '', '', 'dddddddddddd', '', '', '', '', '', '', '', '', '', '', '']
1 re.findall("alex*","asdhfalexxx") 2 3 ----------->输出 4 5 ['alexxx']
1 re.findall("alex+","asdhfalexxx") 2 3 ----------> 输出 4 5 ['alexxx']
1 re.findall("alex*","asdhfale") 2 3 --------->输出 4 5 ['ale']
re.findall("alex?","asdhfale") --------->输出 ['ale']
re.findall("alex{1,}","asdhfalexx") ---------->输出 ['alexx']
re.findall("alex{0,}","asdhfalexx") --------->输出 ['alexx']
re.findall("alex{0,1}","asdhfalexx") ---------->输出 ['alex']
re.findall("alex{6}","asdhfalexxxxxx")
re.findall("alex{0,6}","asdhfalexx")
re.findall("x[yz]","xyuuuu") ---------->输出 ['xy']
re.findall("x[yz]","xyuuxzuu") --------->输出 ['xy', 'xz']
re.findall("x[yz]p","xypuuxzpuu") --------->输出 ['xyp','xzp']
1 re.findall("q[a-z]*","quo") 2 3 --------->输出 4 5 ['quo']
re.findall("q[a-z]*","quogjgkjjhk") --------->输出 ['quogjgkjjhk']
1 re.findall("q[0-9]*","quogjgkjjhk9") 2 3 --------->输出 4 5 ['q']
1 re.findall("q[^a-z]","q213") 2 3 ---------->输出 4 5 ['q2']
!!!! 元字符 \ 就是让有意义的元字符变成没有意义,让无意义的变得有意义
re.findall("\d","12+(34*6+2-5*(2-1))") --------->输出 ['1', '2', '3', '4', '6', '2', '5', '2', '1']
1 re.findall("\d+","12+(34*6+2-5*(2-1))") 2 3 --------->输出 4 5 ['12', '34', '6', '2', '5', '2', '1']
1 re.findall("[\D]+","12+(34*6+2-5*(2-1))") 2 3 ---------->输出 4 5 ['+(', '*', '+', '-', '*(', '-', '))']
re.findall("\D+","hello world") ----------->输出 ['hello world']
re.findall("\S+","hello world") --------->输出 ['hello', 'world']
1 re.findall("\w","hello world_") # 注意这个下划线 2 3 --------->输出 4 5 'h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd', '_']
re.findall("www.baidu","www/baidu") ---------->输出 ['www/baidu']
re.findall("www.baidu","wwwobaidu") -----------输出 ['wwwobaidu']
1 re.findall("www.baidu","www\nbaidu") 2 3 -------->输出 4 5 []
1 re.findall("www\.baidu","www.baidu") 2 3 ---------->输出 4 ['www.baidu']
re.findall("www\*baidu","www*baidu") ------------》 ['www*baidu']
1 re.findall(r"I\b","I am LIST") # re的r =\\ ,就相当转义两次
2 3 ---------->输出
4 5 ['I']
1 re.findall("I\\b","I am LIST") 2 3 -----------> 4 5 ['I']
python解释器\\ 两个,re转义\\ 两个,所以是\\\\ 四个
1 re.findall("c\\\\l","abc\lerwt") 2 3 ---------》 4 5 ['c\\l']
1 import re 2 3 m = re.findall('\bblow', 'blow') # 'blow' 中b顶头,算是特殊边界 4 # \b在python中有特殊意义,传给re 是以它在python解释器中的特殊意义传给re的,所以 5 # re 并不是识别到\b,而是一个特殊意义 6 print(m) 7 8 9 m1 = re.findall(r'\bblow', 'blow') # r 告诉re \b是原生字符 ,re再解释就是\b具有的意思 10 print(m1) 11 12 13 m2 = re.findall('\\bblow', 'blow') 14 print(m2) 15 # 先将'\\\\bblow' 传入python解释器 ,在python解释器中一个\是有特殊意义,两个\\表示一个\ 16 # 再传入 re 中,\也是有特殊意义,所以两个\\b 17 # 因为返回应该是一个 \ ,但是一个\ 在python解释器中有特殊意义,所以返回时做了处理的
re.findall(r"ka|b","sdjkasf") --------->输出 ['ka']
re.findall(r"ka|b","sdjkbsf") # #匹配ka或b ,|将左右分开 ----------.>输出 ['b']
1 re.findall("(abc)+","abcabc" ) # 默认是显示()里的 2 3 ----------->输出 4 5 ['abc']
1 re.findall("(?:abc)+","abcabc" ) #加上?:就取消了限制 2 3 ------------》 4 5 ['abcabc']
search 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以
通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。
1 re.search("(?P<name>\w+)","abcccc") 2 3 ----------------》 4 5 <_sre.SRE_Match object; span=(0, 6), match='abcccc'> #匹配成功了,返回的就是对象 6 7 ----------------》通过group调用 8 9 print(re.search("(?P<name>\w+)","abcccc").group('name')) 10 11 -----------------》 12 13 ‘abcccc’
1 re.search("(?P<name>[a-z]+)","alex36wusir34xialv33") #<>的作用就是把内容进行分组 2 3 ------------------》
re.search("[a-z]+","alex36wusir34xialv33").group() #匹配包含a-z的内容,+号的作用就是重复 -------------------------》 'alex'
1 re.search("(?P<name>[a-z]+)\d+","alex36wusir34xialv33").group("name") #通过分组,可以给group传叁数,找出你想要的信息 2 3 4 ----------------------------》 5 6 ‘alex'
1 re.search("(?P<name>[a-z]+)\d+","alex36wusir34xialv33").group() ------------> alex36 2 3 4 re.search("(?P<name>[a-z]+)\d+","alex36wusir34xialv33").group('name')-------------> alex
re.search("(?P<name>[a-z]+)(?P<age>\d+)","alex36wusir34xialv33").group("age") ------------------------> '36'
re模块下常用的方法:
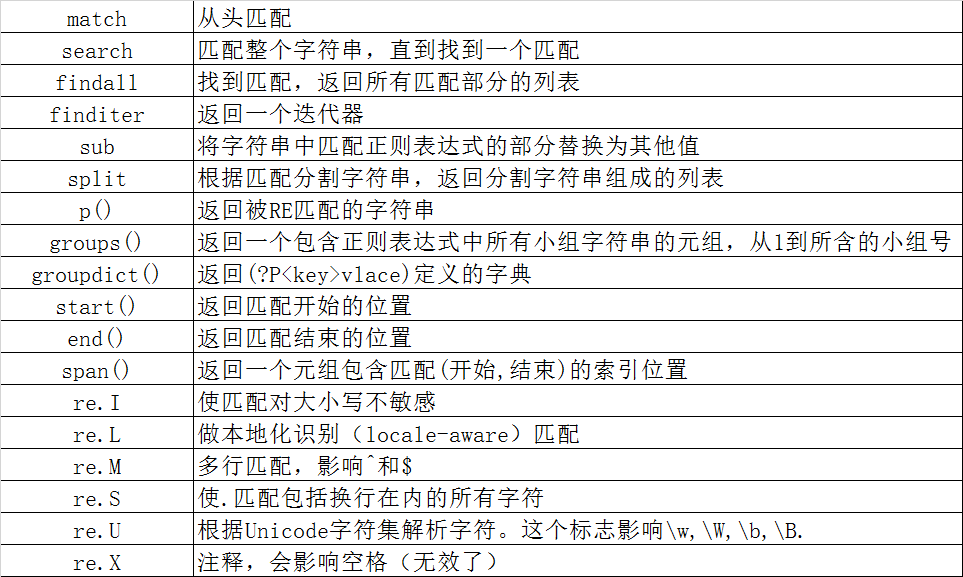
match与search区别:
---- re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
split:
ret=re.split('[ab]','abcd') #以a或者b分隔 --------》 ['','','cd']
re.split(" ","hello abc def") #匹配中间带有空格的 -------------> ['hello', 'abc', 'def']
re.split("[ l]","hello abcldef") # 以空格或 l 区分 ---------》 ['he','','o',abc','def']
re.split("[ab]","asdabcd") -------------》 ['', 'sd', '', 'cd']
sub 替换
re.sub("\d+","A","jaskd4234ashdjf5423") #把所有数字替换为A(4234替换为A) ----------> 'jaskdAashdjfA' ### 并不是改变原字符串,而是生新的字符串
re.sub("\d","A","jaskd4234ashdjf5423",4) #指定替换次数 4,只替换前面4个数字 --------------------------> 'jaskdAAAAashdjf5423'
subn
ret=re.subn('\d','abc','alvin5yuan6') #第一个匹配元组,第二个匹配次数 print(ret) ------------------ ('alvinabcyuanabc', 2)
compile 编译
com=re.compile("\d+") #编译好了一次,下次再用,直接就调用他,不用再编译,提高匹配速度 com.findall("fjlksad234hfjksd3421") #可以匹配多次
finditer(迭代器)当数据非常多的时候,他会把数据存在迭代器中,不会放在内存中,用一条处理一条。
ret=re.finditer("\d","sdfgs6345dkflfdg534jd") next(ret).group() #拿到结果 '6' next(ret).group() '3' next(ret).group() '4' next(ret).group() '5' next(ret).group() '5' next(ret).group() '3' next(ret).group() '4'
匹配手机号:
1 phone_num = '13001000000' 2 a = re.compile(r"^1[\d+]{10}") 3 b = a.match(phone_num) 4 print(b.group())
匹配IPv4
1 # 匹配IP地址 2 ip = '192.168.1.1' 3 a = re.compile(r"(((1?[0-9]?[0-9])|(2[0-4][0-9])|(25[0-5]))\.){3}((1?[0-9]?[0-9])|(2[0-4][0-9])|(25[0-5]))$") 4 b = a.search(ip) 5 print(b)
匹配E-mail
1 email = '630571017@qq.com' 2 a = re.compile(r"(.*){0,26}@(\w+){0,20}.(\w+){0,8}") 3 b = a.search(email) 4 print(b.group())
为什么要坚持,想一想当初!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号