HTML解析
1、简介
通过上一章节的库,都可以拿到HTML内容。
HTML 的内容 返回给浏览器,浏览器就会解析它,让文本表现力更强
HTML 超文本表示语言,设计的初衷就是为了超越普通文本,让文本表现力更强
XML 扩展标记语言,不是为了代替HTML,而是觉得HTML 的设计中包含了过多格式,承担一部分数据之外的任务,所以设计XML 只用来描述数据。
HTML 和 XML 都有数据结构,使用标记形成树型的嵌套结构,DOM来解析这种嵌套树型结构,浏览器往往都提供了对DOM操作的API,可以用面向对象的方式操作DOM
2、XPath***
http://www.w3school.com.cn/xpath/index.asp 中文教程
XPath 是一门在XML 文档中查找信息的语言,XPath 可用来在XML 文档中对元素和属性进行遍历
工具:
XMLQuire win7 + 需要.NET 框架4.0-4.5
测试XML 、XPath
1 <?xml version="1.0" encoding="utf-8"?> 2 <bookstore> 3 <book id="bk101"> 4 <author>Gambardella, Matthew</author> 5 <title>XML Developer's Guide</title> 6 <genre>Computer</genre> 7 <price>44.95</price> 8 <publish_date>2000-10-01</publish_date> 9 <description>An in-depth look at creating applications 10 with XML.</description> 11 </book> 12 <book id="bk102"> 13 <author>Ralls, Kim</author> 14 <title>Midnight Rain</title> 15 <genre>Fantasy</genre> 16 <price>5.95</price> 17 <publish_date>2000-12-16</publish_date> 18 <description>A former architect battles corporate zombies, 19 an evil sorceress, and her own childhood to become queen 20 of the world.</description> 21 </book> 22 <book id="bk103" class="bookinfo even"> 23 <author>Corets, Eva</author> 24 <title>Maeve Ascendant</title> 25 <genre>Fantasy</genre> 26 <price>5.95</price> 27 <publish_date>2000-11-17</publish_date> 28 <description>After the collapse of a nanotechnology 29 society in England, the young survivors lay the 30 foundation for a new society.</description> 31 </book> 32 <book id="bk104"> 33 <author>Corets, Eva</author> 34 <title>Oberon's Legacy</title> 35 <genre>Fantasy</genre> 36 <price>5.95</price> 37 <publish_date>2001-03-10</publish_date> 38 <description>In post-apocalypse England, the mysterious 39 agent known only as Oberon helps to create a new life 40 for the inhabitants of London. Sequel to Maeve 41 Ascendant.</description> 42 </book> 43 </bookstore>
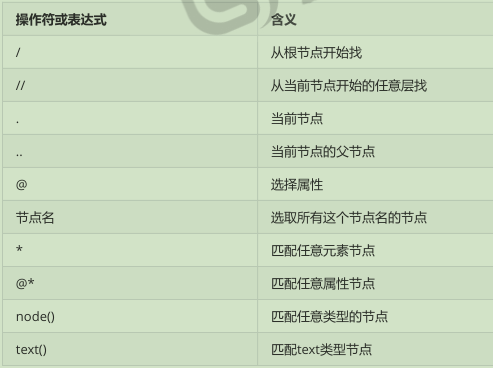
在XPath 中,有七种类型的结点:
元素,属性,文本,命名空间,处理指令,注释以及文档(根)结点
/ 根结点
元素节点
Corets,Eva 元素节点。
id=“bk104” 是属性结点,id是元素节点book的属性
结点之间的嵌套形成父子关系(parent, children)
具有同一个父节点的不同结点是兄弟(sibling)关系
谓语:
谓语用来查找某个特定结点或者包含某个指定的值的结点。
谓语被嵌套在方括号中
谓语就是查询的条件
XPath 轴 (Axes)

XPATH实例
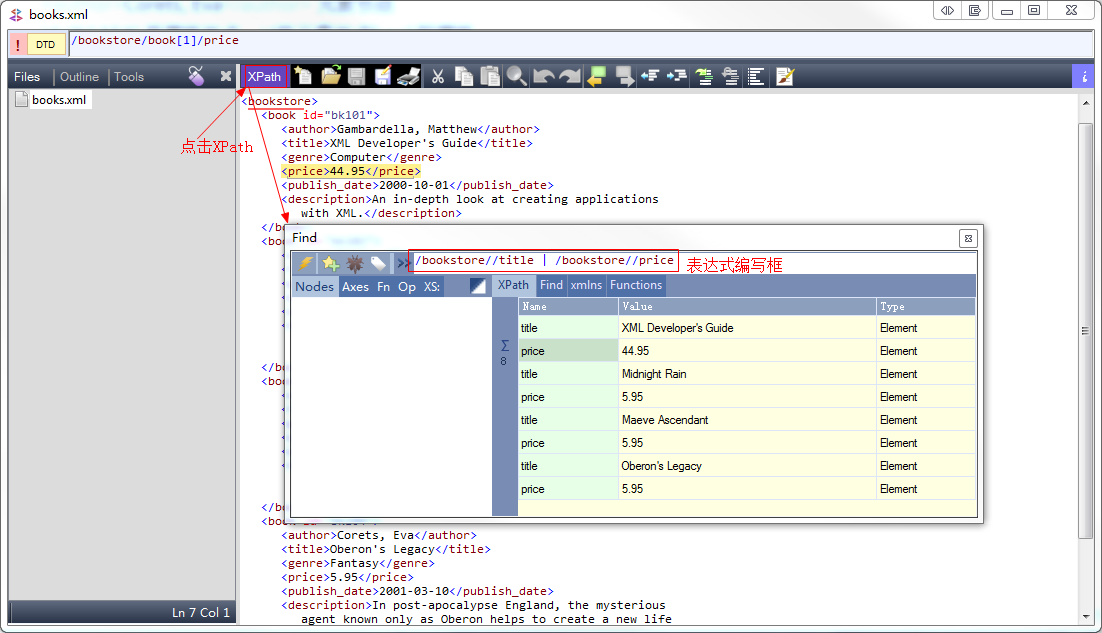
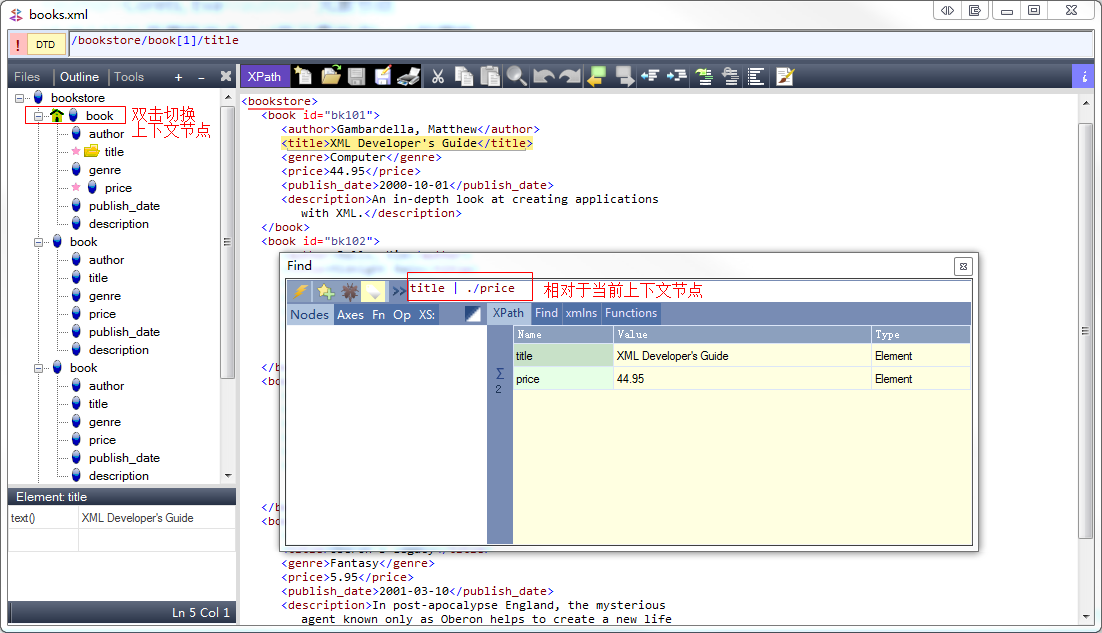
以斜杆开始的称为绝对路径,表示从根开始。
不以斜杆 开始的称为绝对路径,一般都是依照当前结点来就算。当前结点很可能已经不是根结点了
一般为了方便,往往xml 如果层次很深,都会使用 // 来查找结点。


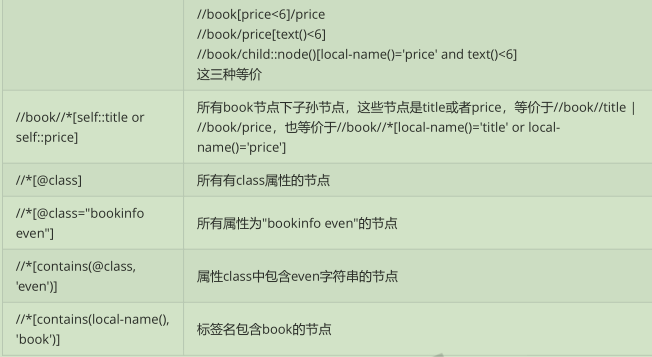
lxml
lxml是Python 下功能丰富的XML, HTML 解析库,性能非常好,是对libxml2 和 libxslt的封装。
CentOS 编译安装需要:
yum install libxml2-devel libxslt-devel
注意,不同平台不一样,参考:https://lxml.de/installation.html
1 from lxml import etree 2 3 # 使用 etree 构建HTML 4 root = etree.Element('html') 5 print(1, type(root)) 6 print(2, root.tag) 7 print(root) 8 9 body = etree.Element('body') 10 root.append(body) 11 12 print(3, etree.tostring(root)) 13 14 sub = etree.SubElement(body, 'child1') # 增加子节点 15 print(4, type(sub)) 16 17 sub = etree.SubElement(body, 'child2').append(etree.Element('child21')) 18 19 print(5, etree.tostring(root, pretty_print=True).decode())
结果:
1 D:\python3.7\python.exe E:/code_pycharm/test_in_class/tt26.py 2 1 <class 'lxml.etree._Element'> 3 2 html 4 <Element html at 0x2a5cec8> 5 3 b'<html><body/></html>' 6 4 <class 'lxml.etree._Element'> 7 5 <html> 8 <body> 9 <child1/> 10 <child2> 11 <child21/> 12 </child2> 13 </body> 14 </html> 15 16 17 Process finished with exit code 0
etree 还提供了2个有用 的函数
etree.HTML(text) 解析HTML 文档,返回根结点
anode.xpath('xpath路径') 对结点使用xpath 语法
练习:爬取:口碑榜
从豆瓣电影中提取:本周口碑榜
提前现在chrome中添加插件:XpathHelper2.0.2.zip
更多工具 ---》 扩展程序 --->添加解压后的文件夹
最后浏览器出现:
1 from lxml import etree 2 3 import requests 4 5 url = 'http://movie.douban.com/' 6 ua = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36" 7 8 9 with requests.get(url, headers={'User-agent':ua}) as response: 10 content = response.text # HTML 内容 11 html = etree.HTML(content) # 分析HTML,返回DOM 根结点 12 titles = html.xpath("//div[@class='billboard-bd']//a/text()") 13 print(1, type(titles)) 14 print(2, titles) 15 for t in titles: 16 print(t)
结果:
1 D:\python3.7\python.exe E:/code_pycharm/test_in_class/tt26.py 2 1 <class 'list'> 3 2 ['无敌破坏王2:大闹互联网', '巴斯特·斯克鲁格斯的歌谣', '无名之辈', '冰淇淋与雨声', '我们,动物', '生活万岁', '黑色1847', '银行家的抵抗', '多甫拉托夫', '白小姐'] 4 无敌破坏王2:大闹互联网 5 巴斯特·斯克鲁格斯的歌谣 6 无名之辈 7 冰淇淋与雨声 8 我们,动物 9 生活万岁 10 黑色1847 11 银行家的抵抗 12 多甫拉托夫 13 白小姐
3、BeautifulSoup4
BeautifulSoup 可以从HTML,XML中提取数据,目前BS4在持续开发
官方中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
安装:
$ pip install beautifulsoup4
导入:
from bs4 import BeautifuSoup
初始化:
BeautifulSoup(markup=" ", features=None)
markup, 被解析对象,可以是文件对象或者html 字符串
features 指定解析对象。
返回一个文档对象。
1 from bs4 import BeautifulSoup 2 3 # 文件对象 4 soup = BeautifulSoup(open("test.html")) 5 # 标记字符串 6 soup = BeautifulSoup("<html>data</html>")
可以不指定解析器,就依赖系统已经安装的解析器库了。

BeautifulSoup(markup, "html.parser") 使用Python 标准库,容错差且性能一般
BeautifulSoup(markup, "lxml") 容错能力强,速度快,需要安装系统C库
推荐使用lxml 作为解析器,效率高。
请手动指定解析器,以保证代码在所有运行环境中解析器一致
使用下面的内容构建test.html 使用bs4解析它:
1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="UTF-8"> 5 <title>首页</title> 6 </head> 7 <body> 8 <h1>马哥教育欢迎您</h1> 9 <div id="main"> 10 <h3 class="title highlight"><a href="http://www.python.org">python</a>高级班</h3> 11 <div class="content"> 12 <p id='first'>字典</p> 13 <p id='second'>列表</p> 14 <input type="hidden" name="_csrf" value="7139e401481ef2f46ce98b22af4f4bed"> 15 <!-- comment --> 16 <img id="bg1" src="http://www.magedu.com/"> 17 <img id="bg2" src="http://httpbin.org/"> 18 </div> 19 </div> 20 <p>bottom</p> 21 </body> 22 </html>
四种对象:
BeautifulSoup 将HTML 文档解析成复杂的树形结构,每个结点都是Python的对象,可分为4种:
BeautifulSoup, Tag,NavigableString, Comment
BeautifulSoup 对象:
BeautifulSoup对象代表整个文档
Tag 对象:
它对应着HTML 中标签,有两个 常用属性:
1、name:Tag对象的名称,就是标签名称
2、attrs:标签的属性字典
-
-
- 多值属性,对于class 属性可能是下面的形式,<h3 class='title highlight'>python高级班</h3> 这个属性就是多值({‘class': ['title', 'highlight'] })
- 属性可以被修改,删除
-
测试:
1 from bs4 import BeautifulSoup 2 3 with open('f:/test.html', encoding='utf-8') as f: 4 soup = BeautifulSoup(f, 'lxml') 5 print(soup.builder) 6 print(0,soup)# 输出整个解析的文档对象 7 print(1, soup.prettify())# 格式输出 8 print('================================') 9 print(2, soup.div) 10 print(2,type(soup.div)) # Tag对象 11 print('================================') 12 print(3, soup.div.name, soup.div.attrs) 13 # print(3, soup.div['class']) # KerryError div 没有class属性 14 print(3, soup.div.get('class')) # 没有返回None 15 print('================================') 16 print(4, soup.h3['class']) # 多值属性 17 print(4, soup.h3.get('class')) #多值属性 18 print(4, soup.h3.attrs.get('class')) # 多值属性 19 print('================================') 20 print(5, soup.img.get('src')) 21 soup.img['src'] = 'http://www.python.org/' # 修改属性 22 print(5, soup.img['src']) 23 print('================================') 24 print(6, soup.a) 25 del soup.h3['class'] 26 print(4, soup.h3.get('class'))
结果:
1 D:\python3.7\python.exe E:/code_pycharm/test_in_class/tt26.py 2 <bs4.builder._lxml.LXMLTreeBuilder object at 0x000000000297D7F0> 3 0 <!DOCTYPE html> 4 <html lang="en"> 5 <head> 6 <meta charset="utf-8"/> 7 <title>首页</title> 8 </head> 9 <body> 10 <h1>马哥教育欢迎您</h1> 11 <div id="main"> 12 <h3 class="title highlight"><a href="http://www.python.org">python</a>高级班</h3> 13 <div class="content"> 14 <p id="first">字典</p> 15 <p id="second">列表</p> 16 <input name="_csrf" type="hidden" value="7139e401481ef2f46ce98b22af4f4bed"/> 17 <!-- comment --> 18 <img id="bg1" src="http://www.magedu.com/"/> 19 <img id="bg2" src="http://httpbin.org/"/> 20 </div> 21 </div> 22 <p>bottom</p> 23 </body> 24 </html> 25 1 <!DOCTYPE html> 26 <html lang="en"> 27 <head> 28 <meta charset="utf-8"/> 29 <title> 30 首页 31 </title> 32 </head> 33 <body> 34 <h1> 35 马哥教育欢迎您 36 </h1> 37 <div id="main"> 38 <h3 class="title highlight"> 39 <a href="http://www.python.org"> 40 python 41 </a> 42 高级班 43 </h3> 44 <div class="content"> 45 <p id="first"> 46 字典 47 </p> 48 <p id="second"> 49 列表 50 </p> 51 <input name="_csrf" type="hidden" value="7139e401481ef2f46ce98b22af4f4bed"/> 52 <!-- comment --> 53 <img id="bg1" src="http://www.magedu.com/"/> 54 <img id="bg2" src="http://httpbin.org/"/> 55 </div> 56 </div> 57 <p> 58 bottom 59 </p> 60 </body> 61 </html> 62 ================================ 63 2 <div id="main"> 64 <h3 class="title highlight"><a href="http://www.python.org">python</a>高级班</h3> 65 <div class="content"> 66 <p id="first">字典</p> 67 <p id="second">列表</p> 68 <input name="_csrf" type="hidden" value="7139e401481ef2f46ce98b22af4f4bed"/> 69 <!-- comment --> 70 <img id="bg1" src="http://www.magedu.com/"/> 71 <img id="bg2" src="http://httpbin.org/"/> 72 </div> 73 </div> 74 2 <class 'bs4.element.Tag'> 75 ================================ 76 3 div {'id': 'main'} 77 3 None 78 ================================ 79 4 ['title', 'highlight'] 80 4 ['title', 'highlight'] 81 4 ['title', 'highlight'] 82 ================================ 83 5 http://www.magedu.com/ 84 5 http://www.python.org/ 85 ================================ 86 6 <a href="http://www.python.org">python</a> 87 4 None 88 89 Process finished with exit code 0
注意:我们一般不使用上面这种方式来操作HTML, 此代码是为了熟悉对象类型
NavigableString
如果只想输出标记内的文本, 而不关心标记的话,就要使用NavigableString
1 print( soup.div.p.string) # 第一个div下第一个p的字符串 2 print( soup.p.string ) 3 4 ---------------- 5 字典
注释对象 Comment:
这就是HTML 中的注释,它被BeautifulSoup解析后对应Comment对象
遍历文档树:
在文档树种找到关心的内容,才是日常的工作,也就是说如何遍历树种的结点,使用上面的test.html来测试
使用Tag
soup.div 可以找到从根结点开始查找第一个div结点
soup.div 说明从根节点开始找到第一个div后返回一个Tag对象,这个Tag对象下继续找第一个P,找到返回Tag对象
soup.p 说明遍历是深度优先,返回了文字:字典, 而不是文字bottom
遍历直接子节点:
print(soup.div.contents) 将对象的所有类型直接子节点以列表方式输出
print(soup.div.children) 返回子节点的迭代器。
print(list(soup.div.children)) 等价 soup.div.contents
结果:
D:\python3.7\python.exe E:/code_pycharm/test_in_class/tt26.py ['\n', <h3 class="title highlight"><a href="http://www.python.org">python</a>高级班</h3>, '\n', <div class="content"> <p id="first">字典</p> <p id="second">列表</p> <input name="_csrf" type="hidden" value="7139e401481ef2f46ce98b22af4f4bed"/> <!-- comment --> <img id="bg1" src="http://www.magedu.com/"/> <img id="bg2" src="http://httpbin.org/"/> </div>, '\n'] ============================================ <list_iterator object at 0x0000000003604A90> ============================================ ['\n', <h3 class="title highlight"><a href="http://www.python.org">python</a>高级班</h3>, '\n', <div class="content"> <p id="first">字典</p> <p id="second">列表</p> <input name="_csrf" type="hidden" value="7139e401481ef2f46ce98b22af4f4bed"/> <!-- comment --> <img id="bg1" src="http://www.magedu.com/"/> <img id="bg2" src="http://httpbin.org/"/> </div>, '\n'] Process finished with exit code 0
遍历所有子孙结点;
print(list ( soup.div.descendants)) # 返回第一个div 结点的所有类型子孙结点,可以看到迭代次序是深度优先
1 from bs4 import BeautifulSoup 2 from bs4.element import Tag 3 4 with open('f:/test.html', encoding='utf-8') as f: 5 soup = BeautifulSoup(f, 'lxml') 6 print(soup.p.string) 7 print(soup.div.contents)# 直接子标签列表 8 print('==================') 9 for c in soup.div.children: # 直接子标签列表可迭代对象 10 print(c.name) 11 print('==================') 12 for d in soup.div.descendants: # 所有子孙,且深度优先 13 print(d.name)
结果:


1 D:\python3.7\python.exe E:/code_pycharm/test_in_class/tt26.py 2 字典 3 ['\n', <h3 class="title highlight"><a href="http://www.python.org">python</a>高级班</h3>, '\n', <div class="content"> 4 <p id="first">字典</p> 5 <p id="second">列表</p> 6 <input name="_csrf" type="hidden" value="7139e401481ef2f46ce98b22af4f4bed"/> 7 <!-- comment --> 8 <img id="bg1" src="http://www.magedu.com/"/> 9 <img id="bg2" src="http://httpbin.org/"/> 10 </div>, '\n'] 11 ================== 12 None 13 h3 14 None 15 div 16 None 17 ================== 18 None 19 h3 20 a 21 None 22 None 23 None 24 div 25 None 26 p 27 None 28 None 29 p 30 None 31 None 32 input 33 None 34 None 35 None 36 img 37 None 38 img 39 None 40 None 41 42 Process finished with exit code 0
遍历字符串
在前面的例子中 soup.div.string 返回时None,是因为string要求soup.div 只能有一个NavigableString类型子节点
也就是如这样:<div>only string</div>
如果 div 有很多 子孙结点,如何提取字符串:
1 from bs4 import BeautifulSoup 2 from bs4.element import Tag 3 4 with open('f:/test.html', encoding='utf-8') as f: 5 soup = BeautifulSoup(f, 'lxml') 6 print(soup.div.strings) 7 print('===========================') 8 print("".join(soup.div.strings)) #返回爹地阿奇,带多余空白字符 9 print('===========================') 10 print("".join(soup.div.stripped_strings)) # 返回迭代器,去掉空白字符
结果:
1 D:\python3.7\python.exe E:/code_pycharm/test_in_class/tt26.py 2 <generator object Tag._all_strings at 0x00000000035CFC00> 3 =========================== 4 5 python高级班 6 7 字典 8 列表 9 10 11 12 13 14 15 =========================== 16 python高级班字典列表 17 18 19 Process finished with exit code 0
遍历祖先结点:
1 from bs4 import BeautifulSoup 2 from bs4.element import Tag 3 4 with open('f:/test.html', encoding='utf-8') as f: 5 soup = BeautifulSoup(f, 'lxml') 6 print(soup.parent)# 根节点 没有父节点 7 print('===========================') 8 print(soup.div.parent.name) # 第一个div的父节点 9 print('===========================') 10 11 print(soup.p.parent.parent.get('id')) #main 12 print('===========================') 13 14 print(list(map(lambda x :x.name, soup.p.parents))) # 父迭代器,由近道远
遍历兄弟结点:
1 from bs4 import BeautifulSoup 2 from bs4.element import Tag 3 4 with open('f:/test.html', encoding='utf-8') as f: 5 soup = BeautifulSoup(f, 'lxml') 6 print("{} [{}]".format(1, soup.p.next_sibling)) #第一个p 元素的下一个兄弟结点,可能是一个文本结点,即\n 7 print('-------------------------------------') 8 print('{} [{}]'.format(2, soup.p.previous_sibling)) 9 print('-------------------------------------') 10 print(list(soup.p.next_sibling))
结果:
1 D:\python3.7\python.exe E:/code_pycharm/test_in_class/tt26.py 2 1 [ 3 ] 4 ------------------------------------- 5 2 [ 6 ] 7 ------------------------------------- 8 ['\n'] 9 10 Process finished with exit code 0
遍历其他元素:
next_element 是下一个可被解析的对象(字符串,或tag), 和下一个兄弟界定啊 next_sibing不一样
1 from bs4 import BeautifulSoup 2 from bs4.element import Tag 3 4 with open('f:/test.html', encoding='utf-8') as f: 5 soup = BeautifulSoup(f, 'lxml') 6 print(soup.p.next_element) 7 print(soup.p.next_element.next_element.next_element) # 有一个文本结点,即\n 8 print(list(soup.p.next_element)) 9
结果:
1 D:\python3.7\python.exe E:/code_pycharm/test_in_class/tt26.py 2 字典 3 <p id="second">列表</p> 4 ['字', '典'] 5 6 Process finished with exit code 0
测试:
1 from bs4 import BeautifulSoup 2 from bs4.element import Tag 3 4 with open('f:/test.html', encoding='utf-8') as f: 5 soup = BeautifulSoup(f, 'lxml') 6 print(soup.p.next_element.next_element.next_element) 7 print('==============================') 8 print(soup.p.next_sibling) # \n 9 print(soup.p.next_sibling.next_sibling) # p 10 print(soup.p.next_sibling.next_sibling.next_sibling) 11 print('==============================') 12 13 print(list(soup.p.next_element)) 14 print('==============================') 15 16 print(list(soup.p.next_sibling)) 17 print('==============================')
结果:
1 D:\python3.7\python.exe E:/code_pycharm/test_in_class/tt26.py 2 <p id="second">列表</p> 3 ============================== 4 5 6 <p id="second">列表</p> 7 8 9 ============================== 10 ['字', '典'] 11 ============================== 12 ['\n'] 13 ============================== 14 15 Process finished with exit code 0
搜索文档树:
find 系有很多方法。
find_all(name=None, attr={}, recursive=True,text=None, limit=None, **kwargs)
find_all 方法,立即返回一个列表
name
官方称为filter 过滤器:这个参数可以是以下 类型:
1、字符串
一个标签名称的字符串,会按照这个字符串全长匹配标签名。
print( soup.find_all('p') )# 返回文档中所有P 标签
2、正则表达式对象
按照正则表达式对象的模式匹配 标签名
import re
print(soup.find_all(re.compile('^h\d'))) # 标签名以h 开头接 数字
3、列表
print(soup.find_all([ 'p', 'h1' ,'h3' ])# 或关系,找出列表所有的标签
print( soup.find_all( re.compile(r'^(p|h\d)$'))) # 使用正则表达式
4、True 或 None
True 或None, 则find_all 返回全部非字符串结点,注注释跌点,即Tag 标签类型
print(list( map(lambda x:x.name, soup.find_all(True))))
print(list( map(lambda x:x.name, soup.find_all(None))))
print(list( map(lambda x:x.name, soup.find_all())))
1 ['html', 'head', 'meta', 'title', 'body', 'h1', 'div', 'h3', 'a', 'div', 'p', 'p', 'input', 'img', 'img', 'p'] 2 ['html', 'head', 'meta', 'title', 'body', 'h1', 'div', 'h3', 'a', 'div', 'p', 'p', 'input', 'img', 'img', 'p'] 3 ['html', 'head', 'meta', 'title', 'body', 'h1', 'div', 'h3', 'a', 'div', 'p', 'p', 'input', 'img', 'img', 'p']
测试:
1 from bs4 import BeautifulSoup 2 from bs4.element import Tag 3 4 with open('f:/test.html', encoding='utf-8') as f: 5 soup = BeautifulSoup(f, 'lxml') 6 values = [True, None, False] 7 for value in values: 8 all = soup.find_all(value) 9 print(len(all)) 10 11 print('--------------------') 12 count = 0 13 for i, t in enumerate(soup.descendants): 14 print(i, type(t), t.name) 15 if isinstance(t, Tag): 16 count += 1 17 print(count)
结果:
1 D:\python3.7\python.exe E:/code_pycharm/test_in_class/tt26.py 2 16 3 -------------------- 4 0 <class 'bs4.element.Doctype'> None 5 1 <class 'bs4.element.Tag'> html 6 2 <class 'bs4.element.NavigableString'> None 7 3 <class 'bs4.element.Tag'> head 8 4 <class 'bs4.element.NavigableString'> None 9 5 <class 'bs4.element.Tag'> meta 10 6 <class 'bs4.element.NavigableString'> None 11 7 <class 'bs4.element.Tag'> title 12 8 <class 'bs4.element.NavigableString'> None 13 9 <class 'bs4.element.NavigableString'> None 14 10 <class 'bs4.element.NavigableString'> None 15 11 <class 'bs4.element.Tag'> body 16 12 <class 'bs4.element.NavigableString'> None 17 13 <class 'bs4.element.Tag'> h1 18 14 <class 'bs4.element.NavigableString'> None 19 15 <class 'bs4.element.NavigableString'> None 20 16 <class 'bs4.element.Tag'> div 21 17 <class 'bs4.element.NavigableString'> None 22 18 <class 'bs4.element.Tag'> h3 23 19 <class 'bs4.element.Tag'> a 24 20 <class 'bs4.element.NavigableString'> None 25 21 <class 'bs4.element.NavigableString'> None 26 22 <class 'bs4.element.NavigableString'> None 27 23 <class 'bs4.element.Tag'> div 28 24 <class 'bs4.element.NavigableString'> None 29 25 <class 'bs4.element.Tag'> p 30 26 <class 'bs4.element.NavigableString'> None 31 27 <class 'bs4.element.NavigableString'> None 32 28 <class 'bs4.element.Tag'> p 33 29 <class 'bs4.element.NavigableString'> None 34 30 <class 'bs4.element.NavigableString'> None 35 31 <class 'bs4.element.Tag'> input 36 32 <class 'bs4.element.NavigableString'> None 37 33 <class 'bs4.element.Comment'> None 38 34 <class 'bs4.element.NavigableString'> None 39 35 <class 'bs4.element.Tag'> img 40 36 <class 'bs4.element.NavigableString'> None 41 37 <class 'bs4.element.Tag'> img 42 38 <class 'bs4.element.NavigableString'> None 43 39 <class 'bs4.element.NavigableString'> None 44 40 <class 'bs4.element.NavigableString'> None 45 41 <class 'bs4.element.Tag'> p 46 42 <class 'bs4.element.NavigableString'> None 47 43 <class 'bs4.element.NavigableString'> None 48 44 <class 'bs4.element.NavigableString'> None 49 16 50 16 51 -------------------- 52 0 <class 'bs4.element.Doctype'> None 53 1 <class 'bs4.element.Tag'> html 54 2 <class 'bs4.element.NavigableString'> None 55 3 <class 'bs4.element.Tag'> head 56 4 <class 'bs4.element.NavigableString'> None 57 5 <class 'bs4.element.Tag'> meta 58 6 <class 'bs4.element.NavigableString'> None 59 7 <class 'bs4.element.Tag'> title 60 8 <class 'bs4.element.NavigableString'> None 61 9 <class 'bs4.element.NavigableString'> None 62 10 <class 'bs4.element.NavigableString'> None 63 11 <class 'bs4.element.Tag'> body 64 12 <class 'bs4.element.NavigableString'> None 65 13 <class 'bs4.element.Tag'> h1 66 14 <class 'bs4.element.NavigableString'> None 67 15 <class 'bs4.element.NavigableString'> None 68 16 <class 'bs4.element.Tag'> div 69 17 <class 'bs4.element.NavigableString'> None 70 18 <class 'bs4.element.Tag'> h3 71 19 <class 'bs4.element.Tag'> a 72 20 <class 'bs4.element.NavigableString'> None 73 21 <class 'bs4.element.NavigableString'> None 74 22 <class 'bs4.element.NavigableString'> None 75 23 <class 'bs4.element.Tag'> div 76 24 <class 'bs4.element.NavigableString'> None 77 25 <class 'bs4.element.Tag'> p 78 26 <class 'bs4.element.NavigableString'> None 79 27 <class 'bs4.element.NavigableString'> None 80 28 <class 'bs4.element.Tag'> p 81 29 <class 'bs4.element.NavigableString'> None 82 30 <class 'bs4.element.NavigableString'> None 83 31 <class 'bs4.element.Tag'> input 84 32 <class 'bs4.element.NavigableString'> None 85 33 <class 'bs4.element.Comment'> None 86 34 <class 'bs4.element.NavigableString'> None 87 35 <class 'bs4.element.Tag'> img 88 36 <class 'bs4.element.NavigableString'> None 89 37 <class 'bs4.element.Tag'> img 90 38 <class 'bs4.element.NavigableString'> None 91 39 <class 'bs4.element.NavigableString'> None 92 40 <class 'bs4.element.NavigableString'> None 93 41 <class 'bs4.element.Tag'> p 94 42 <class 'bs4.element.NavigableString'> None 95 43 <class 'bs4.element.NavigableString'> None 96 44 <class 'bs4.element.NavigableString'> None 97 16 98 16 99 -------------------- 100 0 <class 'bs4.element.Doctype'> None 101 1 <class 'bs4.element.Tag'> html 102 2 <class 'bs4.element.NavigableString'> None 103 3 <class 'bs4.element.Tag'> head 104 4 <class 'bs4.element.NavigableString'> None 105 5 <class 'bs4.element.Tag'> meta 106 6 <class 'bs4.element.NavigableString'> None 107 7 <class 'bs4.element.Tag'> title 108 8 <class 'bs4.element.NavigableString'> None 109 9 <class 'bs4.element.NavigableString'> None 110 10 <class 'bs4.element.NavigableString'> None 111 11 <class 'bs4.element.Tag'> body 112 12 <class 'bs4.element.NavigableString'> None 113 13 <class 'bs4.element.Tag'> h1 114 14 <class 'bs4.element.NavigableString'> None 115 15 <class 'bs4.element.NavigableString'> None 116 16 <class 'bs4.element.Tag'> div 117 17 <class 'bs4.element.NavigableString'> None 118 18 <class 'bs4.element.Tag'> h3 119 19 <class 'bs4.element.Tag'> a 120 20 <class 'bs4.element.NavigableString'> None 121 21 <class 'bs4.element.NavigableString'> None 122 22 <class 'bs4.element.NavigableString'> None 123 23 <class 'bs4.element.Tag'> div 124 24 <class 'bs4.element.NavigableString'> None 125 25 <class 'bs4.element.Tag'> p 126 26 <class 'bs4.element.NavigableString'> None 127 27 <class 'bs4.element.NavigableString'> None 128 28 <class 'bs4.element.Tag'> p 129 29 <class 'bs4.element.NavigableString'> None 130 30 <class 'bs4.element.NavigableString'> None 131 31 <class 'bs4.element.Tag'> input 132 32 <class 'bs4.element.NavigableString'> None 133 33 <class 'bs4.element.Comment'> None 134 34 <class 'bs4.element.NavigableString'> None 135 35 <class 'bs4.element.Tag'> img 136 36 <class 'bs4.element.NavigableString'> None 137 37 <class 'bs4.element.Tag'> img 138 38 <class 'bs4.element.NavigableString'> None 139 39 <class 'bs4.element.NavigableString'> None 140 40 <class 'bs4.element.NavigableString'> None 141 41 <class 'bs4.element.Tag'> p 142 42 <class 'bs4.element.NavigableString'> None 143 43 <class 'bs4.element.NavigableString'> None 144 44 <class 'bs4.element.NavigableString'> None 145 16 146 147 Process finished with exit code 0
5、函数
如果使用以上过滤器还不能提取出想要的结点,可以使用函数,次函数仅只能接受一个采纳数
如果这个函数返回True, 表示当前结点匹配,返回Ffalse, 则不匹配
测试:找出所有class 属相且有多个值的结点:
1 from bs4 import BeautifulSoup 2 from bs4.element import Tag 3 4 def many_class(tag): 5 print(type(tag)) 6 print('============ =================') 7 print(tag.attrs) 8 return len(tag.attrs.get('class', [])) > 1 # 只能返回 True 或者False 9 10 with open('f:/test.html', encoding='utf-8') as f: 11 soup = BeautifulSoup(f, 'lxml') 12 print('=============================') 13 14 print('==', soup.find_all(many_class))
结果:
1 D:\python3.7\python.exe E:/code_pycharm/test_in_class/tt26.py 2 ============================= 3 <class 'bs4.element.Tag'> 4 ============ ================= 5 {'lang': 'en'} 6 <class 'bs4.element.Tag'> 7 ============ ================= 8 {} 9 <class 'bs4.element.Tag'> 10 ============ ================= 11 {'charset': 'UTF-8'} 12 <class 'bs4.element.Tag'> 13 ============ ================= 14 {} 15 <class 'bs4.element.Tag'> 16 ============ ================= 17 {} 18 <class 'bs4.element.Tag'> 19 ============ ================= 20 {} 21 <class 'bs4.element.Tag'> 22 ============ ================= 23 {'id': 'main'} 24 <class 'bs4.element.Tag'> 25 ============ ================= 26 {'class': ['title', 'highlight']} 27 <class 'bs4.element.Tag'> 28 ============ ================= 29 {'href': 'http://www.python.org'} 30 <class 'bs4.element.Tag'> 31 ============ ================= 32 {'class': ['content']} 33 <class 'bs4.element.Tag'> 34 ============ ================= 35 {'id': 'first'} 36 <class 'bs4.element.Tag'> 37 ============ ================= 38 {'id': 'second'} 39 <class 'bs4.element.Tag'> 40 ============ ================= 41 {'type': 'hidden', 'name': '_csrf', 'value': '7139e401481ef2f46ce98b22af4f4bed'} 42 <class 'bs4.element.Tag'> 43 ============ ================= 44 {'id': 'bg1', 'src': 'http://www.magedu.com/'} 45 <class 'bs4.element.Tag'> 46 ============ ================= 47 {'id': 'bg2', 'src': 'http://httpbin.org/'} 48 <class 'bs4.element.Tag'> 49 ============ ================= 50 {} 51 == [<h3 class="title highlight"><a href="http://www.python.org">python</a>高级班</h3>] 52 53 Process finished with exit code 0
keyword 传参:
使用关键字传参,如果参数名不是find 系后汉书已定义的位置参数名,参数会被kwargs收集并被
当作标签的属性来搜索
属性的传参可以是字符串,正则表达式对象,True, 列表

css 的class的特殊处理
class是python的关键字,所以使用class_ 来代替class , class是多值属性,可以匹配其中任意一个,,也可以完全匹配

attrs 参数
attrs 接受一个字典,字典的key 为属性名,value可以是字符串,正则表达式对象,True,列表
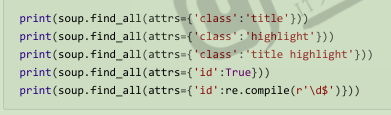
text参数:
可以通过text 参数搜索文档中的字符串内容,接受字符串,正则表达式独享, True,列表

limit 参数
限制返回的结果数量

recursive 参数
默认是递归搜索所有子孙结点 ,如果 不需要请设置为Flase
简化写法:
find_all() 是非常常用的方法,可以简化省略掉

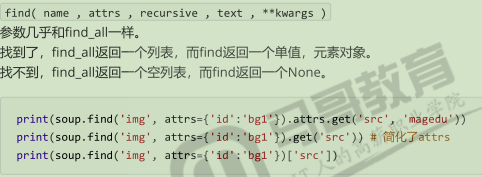
find方法:
4、CSS选择器
和jQuery 一样,可以使用css选择器来查找结点
使用 soup.select() 方法,select 方法支持大部分CSS 选择器,返回列表
CSS 中标签名 直接使用,类名前加 点 号, id名 前加 # 号


获取文本内容
搜索结点的母的往往是为了提取该节点的文本内容,一般不需要HTML 标记,只需要文字

JSON 解析
拿到一个JSON字符串,如果想提取其中的部分内容,就需要遍历,在遍历过程中进行判断
还有一种方式,类似XPath, 叫做jsonPath
安装 :pip install jsonpath
官网:https://goessner.net/articles/JsonPath/

依然用豆瓣电影的热门电影的JSON
https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&page_limit=10&page_start=0
找到得分高于8 分的
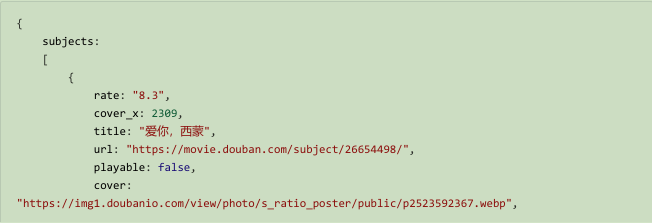
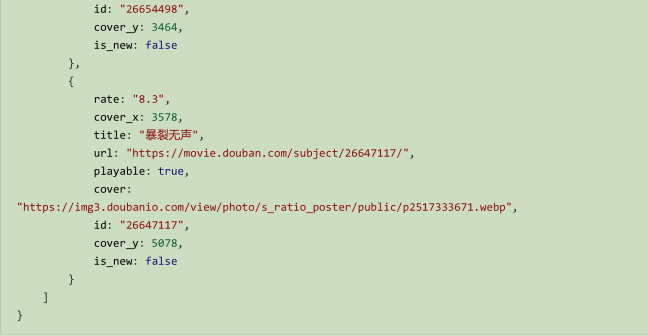
思路:
找到title 非常容易,但是要用其兄弟结点rate 判断是否大于8 分,就不要做了
能够从父节点 下手,subjects 的多个子节点中,要用 [ ] ,某一个结点rate和字符串8 比较来过滤的得到符合要求的subjects的子节点,取这个子节点的title



 浙公网安备 33010602011771号
浙公网安备 33010602011771号