论文笔记 Locality-Sensitive Deconvolution Networks with Gated Fusion for RGB-D Indoor Semantic Segmentation

用于RGB-D室内语义分割的具有门控融合的局部敏感反卷积网络
problem: indoor semantic segmentation using RGB-D data
motivation: there is still room for improvements in two aspects:
- boundary segmentation (边界分割)---DeconvNet aggregates large context to predict the label of each pixel, inherently limiting the segmentation precision of object boundaries

- RGB-D fusion (RGB-D 融合)---Recent state-of-the-art methods generally fuse RGB and depth networks with equal-weight score fusion, regardless of the varying contributions of the two modalities on delineating different categories in different scenes

method to adress problems above: Locality-sensitive DeconvNet; gated fusion layer
kinect-- capture high-quality synchronized visual (RGB data) and geometrical (depth data)
DeconvNet-- learn to upsample the low-resolution label map of FCN into full resolution with more details
上图(a)(b)是使用的two-stream DeconvNet followed by score fusion with equal-weight sum like FCN model[19] 体现的两个有待改进那的两个方面的例子
This paper aims to augment DeconvNet for indoor semantic segmentation with RGB-D data
Refine Boundaries for Semantic Segmentation
- apply the superpixels generated by graph cuts to smooth the predictions[5,9]
- adopt fully connected condition random fields (CRF) to optimize the holistic segmentation map[3,4]
designing particular deep learning models for dense prediction
- CRF is incorporated into FCN by [29, 17] to encourage spatial and appearance consistency in the labelling outputs
- Affinity CNNs [2, 20] embed additional pixel-wise similarity loss into FCN for dense prediction 相似性CNN?
add one data driven pooling layer on top of DeconvNet to smooth the predictions in every superpixel[12]
Combine RGB and Depth Data for Semantic Segmentation
- [23, 22, 10] simply concatenate the handcrafted RGB and depth features to represent each pixel or superpixel
- [7, 15] incorporate both the RGB and depth cues into graphical models like MRFs or CRFs for semantic segm
- entation
- RNN[16]
three levels of fusion: early middle late
- [5] concatenate the RGB and depth image as four-channel input
- [11] use two CNN to extract features from RGB and Depth images independently,then concatenate them
- Long [19] also learn two independent CNN models but directly predict the score map of each modality, followed by score fusion with equal-weight sum
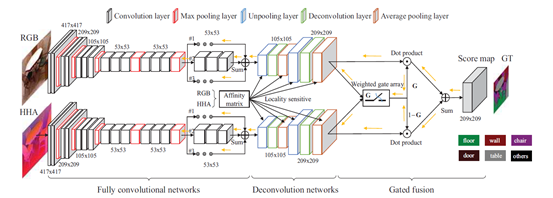
FCN is to learn robust feature representation for each pixel by aggregating multi-scale contextual cues.
LS-DeconvNet is used to restore high-resolution and precise scene details based on the coarse FCN map
a gated fusion layer is introduced to fuse the RGB and depth cues effectively for accurate scene semantic segmentation
concatenate the prediction maps of RGB and depth to learn a weighted gate array
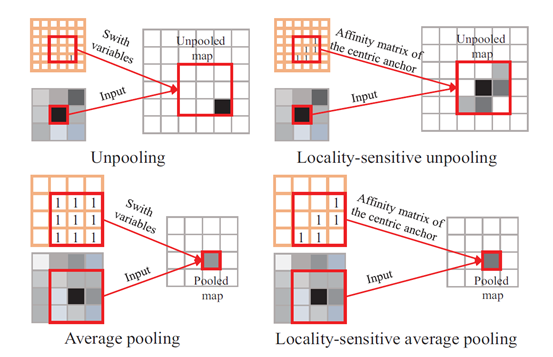
Locality-Sensitive Unpooling 局部敏感去池化
conventional unpooling 最大池化的逆过程,unpooling is helpful to reconstruct detailed
object boundaries, its capability can be limited a lot due to the excessive dependence on the input responding map with large context.
affinity matrix的来源是 RGB-D pixels

discontinuous boundary responses , to make up the missing detais
Locality-Sensitive Average Pooling 局部敏感平均池化
传统平均池化有缺点 to blur object boundaries and result in imprecise semantic segmentation map.
根据affinity matrix 只有相似的像素才会计入平均池化操作

can achieve consistent and robust feature representation for the consecutive object structures.
3 layers concatenation layer/ convolution layer/ sigmoid layer
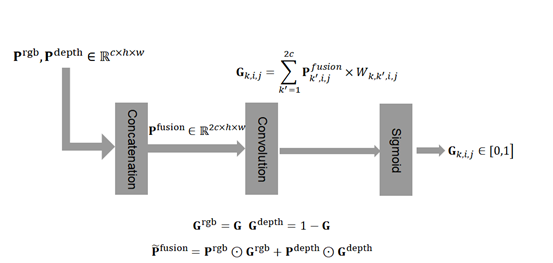
method[10] extract low-level RGB-D features(gradients over visual and geometrical cues) for each pixel, employ gPb-ucm[1] to generate over-segments. These over-segments can be used to calculate A by verifying that pairwise pixels belong to the same over-segment (similarity is 1) or not (similarity is 0). Note that we will scale A to match the resolution of the corresponding feature maps.
- train two independent locality-sensitive DeconvNets on RGB and depth for semantic segmentation without the gated fusion layer 先是分别训练RGB和深度图的两个网络,没有融合层
- In the second stage, we add the gated fusion layer, and then finetune the whole networks on the synchronized RGB and depth data.在第二阶段,我们添加门控融合层,然后在同步RGB和深度数据上微调整个网络
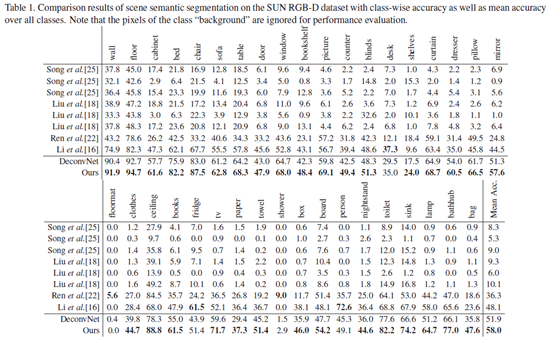
datasets: 2 benchmark RGB-D dataset SUN RGB-D dataset [25] and the popular NYU-Depth v2 dataset
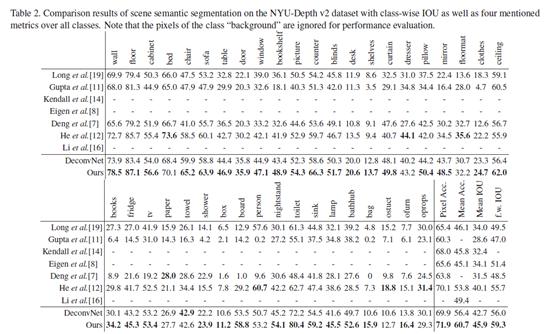
Metrics:pixel accuracy, mean accuracy, mean IOU and frequency weighted IOU
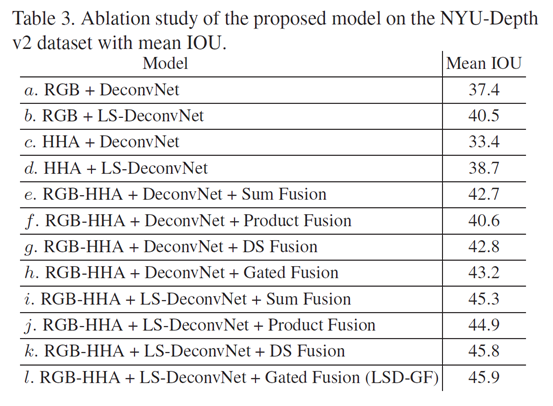
removing or replacing each component independently or both together for semantic segmentation on the NYU-Depth v2 dataset
We owe the improvement to the accurate recognition of some hard objects in the scene by gated fusion, such as box on the sofa and chair in the weak lights.

1) the localitysensitive deconvolution networks, which are designed for simultaneously upsamping the coarse fully convolutional maps and refining object boundaries; 2) gated fusion, which can adapt to the varying contributions of RGB and depth for better fusion of the two modalities for object recognition.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号