论文笔记:STD2P: RGBD Semantic Segmentation Using Spatio-Temporal Data-Driven Pooling
STD2P: RGBD Semantic Segmentation Using Spatio-Temporal Data-Driven Pooling
Yang He, Wei-Chen Chiu, Margret Keuper, Mario Fritz
Abstract:我们提出了一种新的基于超像素的多视图(multi-view)卷积神经网络用于语义图像分割。所提出的网络通过利用来自相同场景的(additional views)附加视图的信息来产生单个图像的高质量分割。特别是在室内视频中,例如由机器人平台或手持式和身体穿戴的RGBD相机拍摄的视频,(nearby video frames)相邻的视频帧提供了不同的视点、物体和场景的附加上下文(addititional context of objects and scenes)。为了利用这些信息,我们首先通过光流(optical flow)和基于图像边界(image boundary-based)的超像素计算区域对应关系(region correspondences)。给定了这些区域对应关系,我们提出了一种新颖的时空池化层(spatio-temporal pooling layer),用于在空间和时间上聚合信息。我们在NYU-Depth-V2和SUN3D数据集上评估我们的方法,并将其与各种最先进的单视图(single-view)和多视图方法进行比较。除了对现有技术的一般改进之外,我们还展示了在多视图和单视图预测的训练期间使用未标记帧的好处。
Motivation: full image sequence provides rich observation of the scene, propagating information across views has the potential to significantly improve the accuracy of semantic segmentations in more challenging views
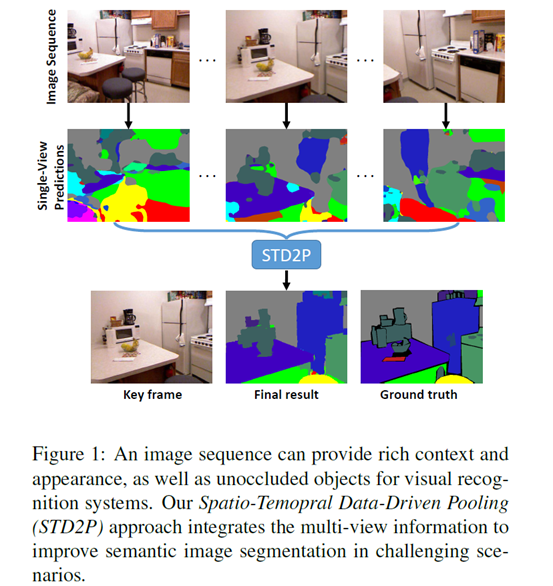
Ideas: 通过 时空数据驱动池化层 进行多视图聚合(multi-view aggregation),incorporate multiple frames//super-pixels and multi-view information in to any CNNs
multi-view single-view 多视点、单视点
Superpixels are able to not only provide precise boundaries,but also to provide adaptive receptive fields ?
FCN fully concolutional network
- introduce superpixels at the end of CNN, integrate the response from multiple views with average pooling 把多个视图的响应和平均池化相结合
- utlize optical flow and image superpixels to establish region correspondences,and design a superpixel based multi-view network
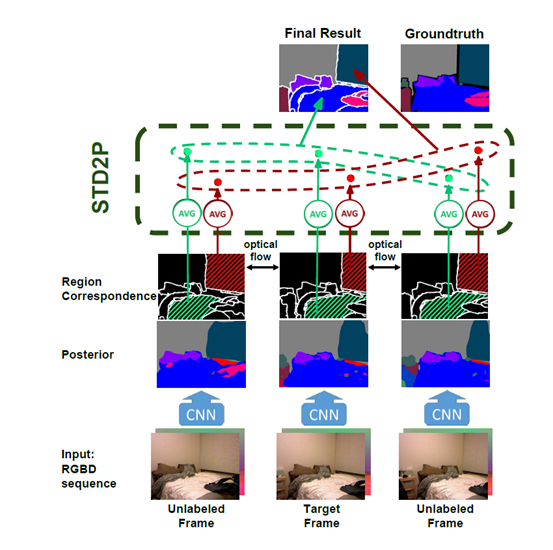
与标准全卷积(FCN)架构的不同在于 compution of region correspondences , spatio-temporal pooling layer
在 unlabeled frame帮助下进行目标帧的语义分割
input:rgbd 图像序列,target frame是我们最终要进行semantic segmantation的一个视点图
在frame-wise region level 建立需要的correspondences
rgbd version of the structured edge detection
compute RGBD superpixels in each frame to partition a RGBD image into regions, and apply Epic flow between each pair of consecutive frames to link these regions.To utilize the RGBD version of the structured edge detection to generate boundary estimates
robust spatio-temporal matching 鲁棒的时空匹配
已知了所有帧的超像素分割结果,帧之间的optical flow
matching score 以 intersection over union(IOU)度量:

statistics of region correspondences on the NYUDv2 dataset

unlike small region, bigger regions can be matched more easiy, which thus provide adequate information for multi-view network
idea: refine the output of the deconvolution layer with superpixels and aggregate the information from multiple views by 3 layers: spatial pooling layer, a temporal pooling layer and a region-to-pixel layer
使用superpixel 来改善deconvolution layer的输出,使用空间池化层、时间池化层、区域-像素池化层来聚合多视点的信息

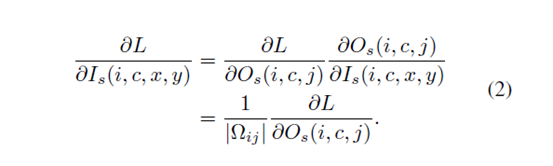

这里的match就是region correspondence 中的match?

时间池化层的输出是C*P,作为区域-像素池化层的输入,需要target frame的superpixel map S 大小是H*W,输出O_r(c,x,y)是C*H*W
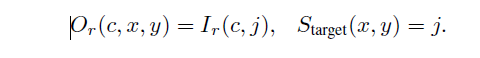
输入帧的获取, 11 frames together with their correspondence maps 输入到std2p?
datasets: NYU-Depth-V2(NYUDv2) 具体地,4-class、13-class、40-class tasks of it
results on NYUDv2 40-class task 使用3种本文模型的变体实验
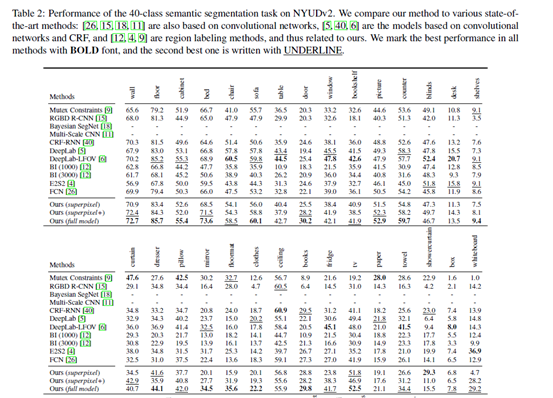
1)superpixel model over baseline FCN、latest methods based on superpixels and CNN
trained on single labeled frames tested on single target frame
2) superpixel+ model over superpixel model
trained with additional unlabeled data tested on single target frame
3) full model over superpixel+ model
trained and tested both with unlabeled data
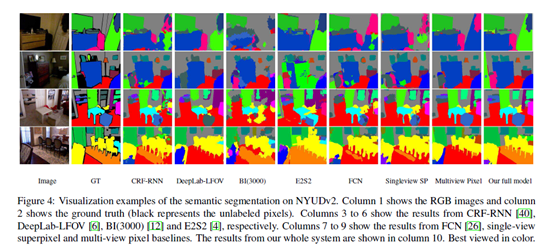
region vs pixel correspondences
pixel correspondence是怎么做的 据说就是光流法的操作
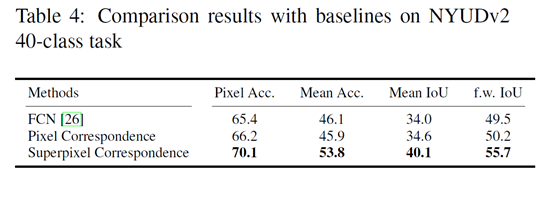
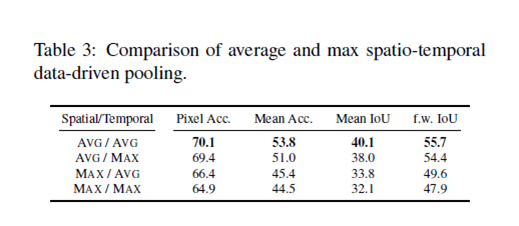
analysis of multi-view prediction

这里的past future 指的是target frames 前 后?
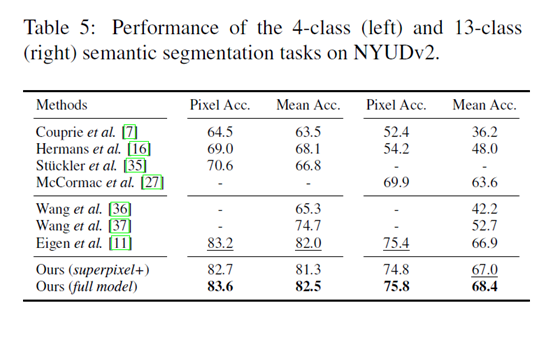
results on NYUDv2 4-class/13-class
over multi-view methods、single-view methods
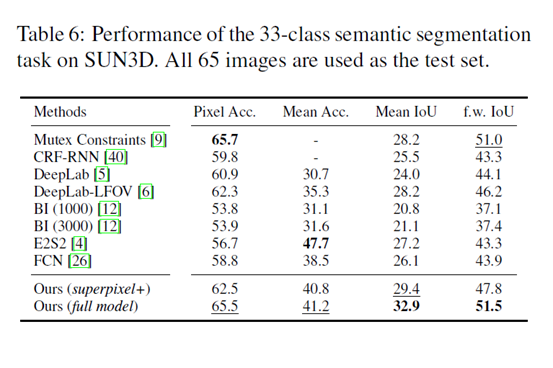
results on SUN3D 33-class task
trained on NYUDv2 tested on SuN3D over baseline FCN、 DeepLab-LFOV
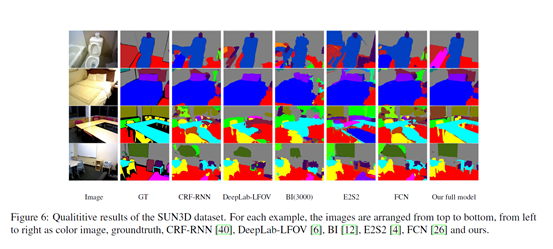
superpixel-based muti-view semantic segmentation network with spatio-temporal data-driven pooling which receive multi images and their correspondence,这在模型具体方法里怎么体现了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号