2018福大软工实践第五次作业
结对作业 Round2
前言
- stay hungry, stay foolish
I 分工
- 黄sir ------------->> WordCount.exe 功能的更新和升级
- 刘sir ------------->> 编写爬虫程序,生成文件
II PSP表格
| PSP5.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 660 | 680 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 120 |
| · Design Spec | · 生成设计文档 | 90 | 90 |
| · Design Review | · 设计复审 | 60 | 60 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 40 |
| · Design | · 具体设计 | 60 | 70 |
| · Coding | · 具体编码 | 120 | 120 |
| · Code Review | · 代码复审 | 60 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 120 |
| Reporting | 报告 | 75 | 90 |
| · Test Repor | · 测试报告 | 45 | 50 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 30 |
| | 合计 | 745 | 780
III 解题思路描述与设计实现说明
-
解题思路描述
本程序在之前的personal-project项目的基础上进行修改,判断单词是整个程序的基础。由于之前的personal-project项目中的单词判断调用了一些不熟悉的函数且判断过程较复杂,所以先对单词判断过程进行优化。优化后开始在这个基础上添砖加瓦,在本题中,由于每篇论文的格式固定,并且要求一些字符不纳入考虑范围,因此对换行符个数进行判断以达到跳过无效字符、确定当前字符所在位置(Title或Abstract)的作用。至此,题目已完成统计字符总数、有效行数、单词总数和单词词频的功能。在此基础上添加词组功能,词组是由m个分隔符隔开的单词组成的,因此对词组中当前单词个数进行判断即可。
-
代码组织与内部实现设计(类图)
由于所有功能实现仅读一次文件即可,因此所有功能都可以在一个函数中实现。出于方便使用和进行单元测试的目的,我对代码进行接口封装。将代码的功能封装成一个类Core,类中含有两个核心函数kernelFunction()和sort(),kernelFunction()函数可以完成对指定文件的字符总数、单词总数、有效行数的统计以及单词或词组的存储的功能,sort()函数可以对单词或词组进行排序。此外,Core还有小函数供外部访问需要的数据,如getCrt()、getWords()和getLines()分别返回文件的字符总数、单词总数和有效行数。
类图:

-
算法的关键与关键实现部分流程图
-
单词的判断:定义一个strWords变量储存当前单词。对当前读入的字符进行判断,可能的情况有三种:读到字母、读到数字、读到分隔符。如果读到字母且仍然有可能是单词就将该字符加到strWords末尾;如果读到数字且仍然有可能是单词就判断当前strWords中字符个数,如果大于或等于4个则将该字符加到strWords末尾,否则strWords不可能是单词并且接下来直到读到下一个分隔符之前的都不用考虑;如果读到分隔符且仍然有可能是单词也是判断当前strWords中字符个数,如果大于或等于4个说明strWords中存储的是一个单词并且已经结束,否则说明strWords中存储的不是单词。
-
换行符个数的判断:每读入一个字符,首先对ignoreNum进行判断,如果ignoreNum>0,则跳过该字符。每读到一个换行符,则换行符个数linefeedNum++,此时如果是奇数个换行符,则ignoreNum=10,如果是偶数个换行符,则ignoreNum=2。并设置一个flag0区分论文标题的那个字符和Title内容的字符,当读到论文标题的那个字符时,ignoreNum=8。
-
单词的判断流程图:
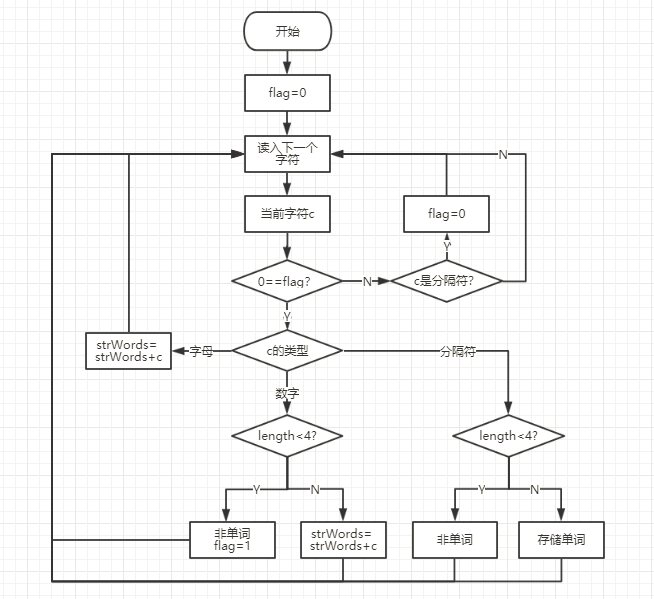
换行符个数的判断流程图:

IV 附加题设计与展示
-
设计的创意独到之处
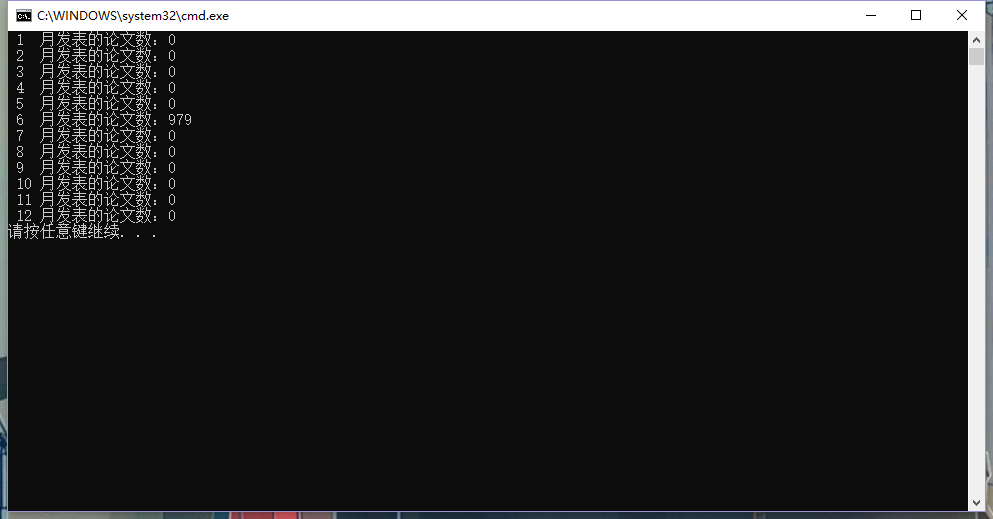
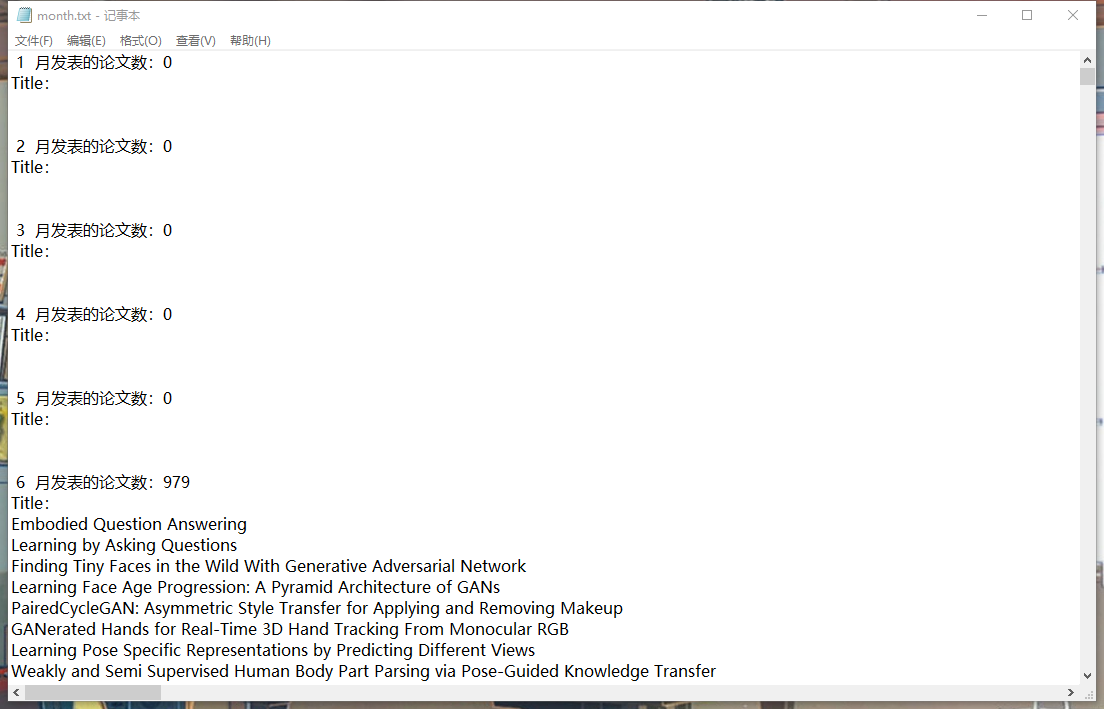
可以输出每个月发表的论文的数量并且输出每个月对应的论文题目
-
实现思路
新建一个名为 month 的类,对输出文件进行遍历,如果找到某月的论文,就将对应月份论文的数量加一,在将论文题目输出到对应月份下面。
-
实现成果展示
V 关键代码解释
if (flag == 0) { //有可能是单词
if (isLett(c)) { //读到字母
//大写字母改为小写
if (c >= 'A' && c <= 'Z') {
c += 32;
}
strWords = strWords + c;
length++; //length记录strWords实时长度
}
else if (isNum(c)) { //读到数字
if (length < 4) { //非单词,strWords清空,wordGroup清空
strWords.clear();
wordGroup.clear();
wordGroupNum = 0;
length = 0;
flag = 1;
}
else {
strWords = strWords + c;
length++;
}
}
else if (!isAlph(c)) { //读到分隔符
if (0 == length && wordGroupNum != 0) { //词组中单词间的分隔符
wordGroup = wordGroup + c;
}
else if (length < 4) { //非单词,strWords清空,wordGroup清空
strWords.clear();
wordGroup.clear();
wordGroupNum = 0;
length = 0;
}
else { //单词
wordGroupNum++;
wordGroup = wordGroup + strWords;
if (mNum == wordGroupNum) { //词组
if (linefeedNum % 2 == 1 || (linefeedNum % 2 == 0 && "0" == Weight)) {
k = 1; //Abstract内容或者Weight为0时的Title内容
}
else { //Weight为1时的Title内容
k = 10;
}
it = strMap.find(wordGroup);
if (it == strMap.end()) { //没有该词组记录
strMap[wordGroup] = k;
}
else {
strMap[wordGroup] += k;
}
//词组取后m-1个单词
for (int l = 0; l<wordGroup.length(); l++) {
if (!isAlph(wordGroup[l])) { //找到分隔符,即第一个单词末尾
findFirstSeparator = true;
}
if (findFirstSeparator) {
if (isLett(wordGroup[l])) {
pos = l;
findFirstSeparator = false;
break;
}
}
}
wordGroup = wordGroup.substr(pos, wordGroup.length() - pos);
wordGroupNum--;
}
wordGroup = wordGroup + c;
twords++;
strWords.clear();
length = 0;
}
}
}
else { //不可能是单词
if (!isAlph(c)) {
flag = 0;
}
}
- strWords记录单词,wordGroup记录词组,wordGroupNum记录词组内单词个数,在判断是否是单词的基础上判断是否是词组。如果是单词则wordGroupNum++,把当前单词接在wordGroup后面,然后判断单词个数是否已经满足条件,如果满足则储存词组,wordGroup取后m-1个单词,不满足则继续判断单词。如果不是单词则wordGroup清空,继续判断单词。
VI 性能分析与改进
- 一开始在基本功能(字符总数统计、单词总数统计、有效行统计)的实现过程中我打算对换行符的个数进行多种判断,后来在设计过程中进行改进,最终对换行符进个数进行奇偶两种判断,保证跳过不纳入考虑范围的字符,仅对有效字符进行操作。

VII 单元测试
TEST_METHOD(TestMethod6)
{
string InputName = "E:\\软件工程实践\\WordCount2\\WordCount\\Test\\test6.txt";
string OutputName = "std6.txt";
string Weight = "0";
int mNum = -1;
int nNum = -1;
Core core(InputName, OutputName, Weight, mNum, nNum);
int crt = 817;
int words = 80;
int lines = 2;
Assert::AreEqual(core.getCrt(), crt);
Assert::AreEqual(core.getWords(), words);
Assert::AreEqual(core.getLines(), lines);
}
TEST_METHOD(TestMethod7)
{
string InputName = "E:\\软件工程实践\\WordCount2\\WordCount\\Test\\test7.txt";
string OutputName = "std7.txt";
string Weight = "1";
int mNum = -1;
int nNum = 3;
Core core(InputName, OutputName, Weight, mNum, nNum);
int crt = 1756;
int words = 173;
int lines = 4;
Assert::AreEqual(core.getCrt(), crt);
Assert::AreEqual(core.getWords(), words);
Assert::AreEqual(core.getLines(), lines);
}
- 上面两个单元测试主要是对字符统计、单词总数统计、有效行统计函数进行测试,使用Assert的AreEqual测试字符数、单词总数和有效行数是否是正确的。
VIII 贴出Github的代码签入记录

IX 遇到的代码模块异常或结对困难及解决方法
-
问题描述
在调试过程中,我遇到过一个报错 "abort() has been called"。
-
做过哪些尝试
首先,我上百度搜索这种错误的发生原因,然后对照自己的代码寻找原因,发现自己的问题与百度上搜索到的不一样。因此我根据一个简单的样例对自己的代码进行调试,确认报错的具体位置,输出相关的数据,然后发现自己在换行符判断的位置有一处没有清空字符串wordGroup,所以导致报错。
-
是否解决
找到了bug,解决就很简单,只要在没有清空字符串的位置加上一行清空字符串wordGroup的代码即可。
-
有何收获
虽然思路很清楚,并且也打好了草稿,对自己的代码流程很了解,但是还是有可能会出现漏写或忘写某些代码的情况,因此对代码进行调试和样例测试是很重要的。
X 评价你的队友
-
值得学习的地方
刘一好同学在时间规划方面做的很好,在这方面我做的比较差一点,在最后几天开始写这个代码,如果有突发情况发生就需要熬夜肝一下了,不然会来不及。
-
需要改进的地方
刘一好同学在一些细节方面需要做的更好一点。
XI 学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 300 | 300 | 25 | 25 | C++熟悉,对文件读取分析方法 |
| 2 | 0 | 300 | 7 | 32 | Axure rp 8使用 熟悉NABCD模型 |
| 3 | 300 | 600 | 20 | 42 | WordCount优化,Android获取手机短信权限算法 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号