requests模块
Requests 是⽤Python语⾔编写,基于 urllib库,采⽤Apache2 Licensed 开源协议的 HTTP 库。它⽐ urllib 更加⽅便,可以节约我们⼤量的⼯作,完全满⾜HTTP 测试需求。
⼀句话——Python实现的简单易⽤的HTTP库 (相对于urllib来说)。
可以说自从用了requests库,现在很少去使用操作繁琐的urllib库了。
一个简单的requests请求:
import requests response = requests.get('https://www.baidu.com/') print(type(response)) print(response.status_code) print(type(response.text))#直接就是str省去read() print(response.text) print(response.cookies)
<class 'requests.models.Response'> 200 <class 'str'> <!DOCTYPE html> <!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css><title>ç¾åº¦ä¸ä¸ï¼ä½ å°±ç¥é</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus=autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=ç¾åº¦ä¸ä¸ class="bg s_btn" autofocus></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>æ°é»</a> <a href=https://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>å°å¾</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>è§é¢</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>è´´å§</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>ç»å½</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">ç»å½</a>'); </script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">æ´å¤äº§å</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>å ³äºç¾åº¦</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使ç¨ç¾åº¦åå¿ è¯»</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>æè§åé¦</a> 京ICPè¯030173å· <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html> <RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
可以看出requests真的是十分的简单粗暴,操作很舒服简单好用,至于乱码问题,在头部找不到编码方式它默认自己的方式来编码,所以一般可以使用
print(response.content.decode('utf8'))
就可以正常的显示了。
默认发送的时get请求,你可以用requests发各种请求。
import requests requests.post('http://httpbin.org/post') requests.put('http://httpbin.org/put') requests.delete('http://httpbin.org/delete') requests.head('http://httpbin.org/get') requests.options('http://httpbin.org/get')
#带参数的get请求 import requests response = requests.get("http://httpbin.org/get?name=germey&age=22") print(response.text)
#这个网址会显示请求的信息 { "args": { "age": "22", "name": "germey" }, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Connection": "close", "Host": "httpbin.org", "User-Agent": "python-requests/2.18.4" }, "origin": "36.57.169.42", "url": "https://httpbin.org/get?name=germey&age=22" }
#发送一个post请求 import requests data = { 'name': 'germey', 'age': 22 } response = requests.get("http://httpbin.org/get", params=data) print(response.text)
{ "args": { "age": "22", "name": "germey" }, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Connection": "close", "Host": "httpbin.org", "User-Agent": "python-requests/2.18.4" }, "origin": "36.57.169.42", "url": "https://httpbin.org/get?name=germey&age=22" }
#响应可以直接转化成json格式 import requests import json response = requests.get("http://httpbin.org/get") print(type(response.text)) print(response.json()) print(json.loads(response.text)) print(type(response.json()))
<class 'str'> {'args': {}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Connection': 'close', 'Host': 'httpbin.org', 'User-Agent': 'python-requests/2.18.4'}, 'origin': '36.57.169.42', 'url': 'https://httpbin.org/get'} {'args': {}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Connection': 'close', 'Host': 'httpbin.org', 'User-Agent': 'python-requests/2.18.4'}, 'origin': '36.57.169.42', 'url': 'https://httpbin.org/get'} <class 'dict'>
获取bytes类型存入文件
#下载github图标 import requests response = requests.get("https://github.com/favicon.ico") with open('favicon.ico', 'wb') as f: f.write(response.content) f.close()
默认我们去爬知乎的时候,我们的User-Agent里带的信息时python的标签,你带这个去爬网站别人时拒绝的,所以知乎会告诉你:
<html><body><h1>500 Server Error</h1>
An internal server error occured.
</body></html>
这种时候我们需要带上浏览器的请求去欺骗它,所以requests加请求头也十分的简单。
import requests headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36' } response = requests.get("https://www.zhihu.com/explore", headers=headers) print(response.text)
然后我们就正确的获得了知乎的响应页面。
#发送post请求 import requests data = {'name': 'germey', 'age': '22'} headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36' } response = requests.post("http://httpbin.org/post", data=data, headers=headers) print(response.json())
{'args': {}, 'data': '', 'files': {}, 'form': {'age': '22', 'name': 'germey'}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Connection': 'close', 'Content-Length': '18', 'Content-Type': 'application/x-www-form-urlencoded', 'Host': 'httpbin.org', 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36', 'X-Lantern-Version': '4.4.2'}, 'json': None, 'origin': '36.57.169.42', 'url': 'http://httpbin.org/post'}
requests返回的响应的属性
import requests response = requests.get('http://www.jianshu.com') print(type(response.status_code), response.status_code) print(type(response.headers), response.headers) print(type(response.cookies), response.cookies) print(type(response.url), response.url) print(type(response.history), response.history)
<class 'int'> 200 <class 'requests.structures.CaseInsensitiveDict'> {'Date': 'Wed, 31 Jan 2018 14:57:25 GMT', 'Server': 'Tengine', 'Content-Type': 'text/html; charset=utf-8', 'Transfer-Encoding': 'chunked', 'X-Frame-Options': 'DENY', 'X-XSS-Protection': '1; mode=block', 'X-Content-Type-Options': 'nosniff', 'ETag': 'W/"6c6a2e8f5a9e808beba02bd0136e9a08"', 'Cache-Control': 'max-age=0, private, must-revalidate', 'Set-Cookie': 'locale=zh-CN; path=/', 'X-Request-Id': '4b2c3211-8071-409f-8830-ab853ffc5fe6', 'X-Runtime': '0.008368', 'Content-Encoding': 'gzip', 'X-Via': '1.1 dianxun108:6 (Cdn Cache Server V2.0), 1.1 PSrbdjKDDIbq100:5 (Cdn Cache Server V2.0)', 'Connection': 'keep-alive'} <class 'requests.cookies.RequestsCookieJar'> <RequestsCookieJar[<Cookie locale=zh-CN for www.jianshu.com/>]> <class 'str'> https://www.jianshu.com/ <class 'list'> [<Response [301]>]
#判断响应码 import requests response = requests.get('http://www.jianshu.com') exit() if not response.status_code == 200 else print('Request Successfully')
import requests headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36' } files = {'file': open('favicon.ico', 'rb')} response = requests.post("https://httpbin.org/post", files=files, headers=headers) print(response.text)
文件上传成功:

requests获取cookie import requests response = requests.get("https://www.baidu.com") print(response.cookies) for key, value in response.cookies.items(): print(key + '=' + value)
<RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]> BDORZ=27315
用requests模拟保持会话
import requests #如果没有session那么访问的这个setcookie即使设置了cookie但是每个request都是独立依然无法获取cookie s = requests.Session() s.get('http://httpbin.org/cookies/set/number/123456789') response = s.get('http://httpbin.org/cookies') print(response.text)
在请求https页面时,需要进一步验证ssl证书,这里你有两种选择,一种是信任不验证。
import requests from requests.packages import urllib3 urllib3.disable_warnings() response = requests.get('https://www.12306.cn', verify=False) print(response.status_code)
另一种方式是,把证书的地址放上来。
import requests response = requests.get('https://www.12306.cn', cert=('/path/server.crt', '/path/key')) print(response.status_code)
requests设置代理
import requests #代理可以是多个ip proxies = { "http": "http://user:password@127.0.0.1:9743/", } response = requests.get("https://www.taobao.com", proxies=proxies) print(response.status_code)
#设置超时时间
import requests from requests.exceptions import ReadTimeout try: response = requests.get("http://httpbin.org/get", timeout = 0.5) print(response.status_code) except ReadTimeout: print('Timeout')
认证设置的两种方式(一般不会用这个吧)
import requests
from requests.auth import HTTPBasicAuth
r = requests.get('http://120.27.34.24:9001', auth=HTTPBasicAuth('user', '123'))
print(r.status_code)
import requests
r = requests.get('http://120.27.34.24:9001', auth=('user', '123'))
print(r.status_code)
#异常处理
import requests
from requests.exceptions import ReadTimeout, ConnectionError, RequestException
try:
response = requests.get("http://httpbin.org/get", timeout = 0.5)
print(response.status_code)
except ReadTimeout:
print('Timeout')
except ConnectionError:
print('Connection error')
except RequestException:
print('Error')
practice:使用正则表达式抓取豆瓣图书的书名与作者
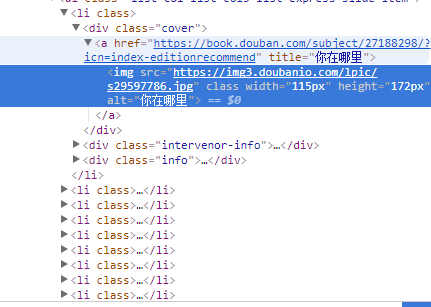
用正则匹配每个li标签:
import requests import re headers = {"User-Agent" : "User-Agent:Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"} response = requests.get('https://book.douban.com/', headers=headers).text pattern = re.compile('<li.*?title="(.*?)".*?author">(.*?)</div>.*?</li>',re.S) results = re.findall(pattern, response) for result in results: name, author= result author = re.sub('\s', '', author) print(name, author)



 浙公网安备 33010602011771号
浙公网安备 33010602011771号