python动态类型
在python中,省去了变量声明的过程,在引用变量时,往往一个简单的赋值语句就同时完成了,声明变量类型,变量定义和关联的过程,那么python的变量到底是怎样完成定义的呢?
动态类型
python使用动态类型和他提供的多态性来提供python语言的简洁灵活的基础。在python中我们是不会声明所使用对象的确切类型的。所谓的python动态类型,就是在程序运行的过程中自动决定对象的类型。
对象、变量和引用
当我们在赋值一个变量时,在python中其实自动做了很多事情。
1.创建变量:当代码第一次赋值给一个变量时就创建了这个变量,在之后的赋值过程关联值,python在代码运行之前先检验变量名,可以当成是最初的赋值创建变量。
2.变量声明:python中类型只存在于对象中,而不是变量,变量是通用的,他只是在程序的某一段时间引用了某种类型的对象而已,比如定义a =1 ,a = 'a',一开始定义了变量a为指向了整型的对象,然后变量又指向了字符串类型的变量,可见,变量是不固定的类型。
3.变量使用:变量出现在表达式中就会马上被对象所取代,无论对象是什么内类型,变量在使用前必须要先定义。
值得注意的是,变量必须在初始化名字之后才能更新他们,比如计数器初始化为0,然后才能增加他。
也就是说,当我们给变量赋值的时候,比如a=3,python执行三个不同操作去完成赋值。
1.创建一个对象代表3,
2.如果程序中没有变量a,则创建他。
3.将变量与对象3连接起来。
变量与对象是连接关系,它们存储在内存的不同位置,如果有列表嵌套这样大的对象,对象还连接到它包含的对象。这种从变量到对象的连接称为引用。
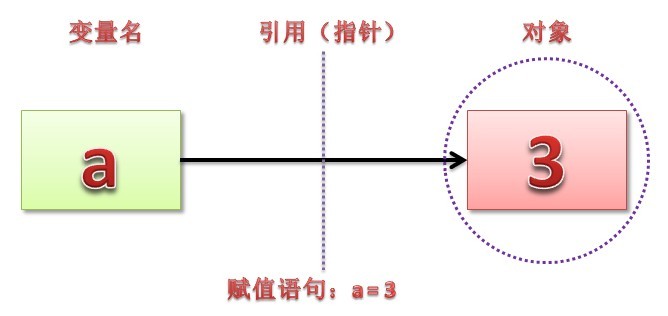
变量的引用以内存中的指针形式实现。一旦变量被使用,那么python自动跟变量的对象连接。具体来说:
1.变量是系统表的元素,他指向对象存放的地址空间。
2.对象是分配的一块内存,地址可被连接,有足够大空间代表对象的值,
3.引用的过程自动完成变量指向对象地址的过程,即从变量到对象的指针。
对象的垃圾回收
每个对象都有两个标准头部信息,一个是类型标志符,用于标记对象类型,另一个是引用计数器,用来决定是不是可回收对象。很显然,在python中只有对象才有类别区分,变量不过是引用了对象,变量并不具有类别区分,他只是在特定时间引用某个特定对象。
对于引用计数器的使用,则关联到python的垃圾回收机制,当当一个变量名赋予了一个新的对象,那么之前旧的对象占用的地址空间就会被回收。旧对象的空间自动放入内存空间池,等待后来的对象使用。
计数器在垃圾回收的过程中有事如何工作的呢?计数器记录的是当前指向对象的引用数目,如果在某时刻计数器设置为0,则表示未被引用,name这个对象的内存空间就会收回。
对象的垃圾回收有着很大的意义,这使得我们在python中任意使用对象而且不需要考虑释放空间,省去了C与C++中大量的基础代码。
共享引用(深浅拷贝的缘由)
在谈共享引用之前,我们先要对列表的数据结构有一定的了解,列表不同于数组和链表,相较于数组(只能存储单一的数据类型),列表可存取的数据类型是多样的(多态)。
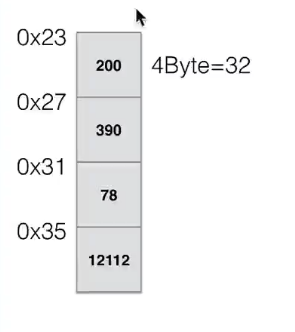
上图是数组,每个数组存了一个4个字节的数字,数组开辟了4*4个字节的连续的存储空间,所以数组要求单一数据类型,否则长度不可控,无法索引。这里对数组进行索引就直接拿到某段内存里面存取的数据。
可以通过存储区的起始地址Loc (e0)加上逻辑地址(第i个元素)与存储单元大小(c)的乘积计算而得,即:
Loc(ei) = Loc(e0) + c*i
访问指定元素时无需从头遍历,通过计算便可获得对应地址,其时间复杂度为O(1)。
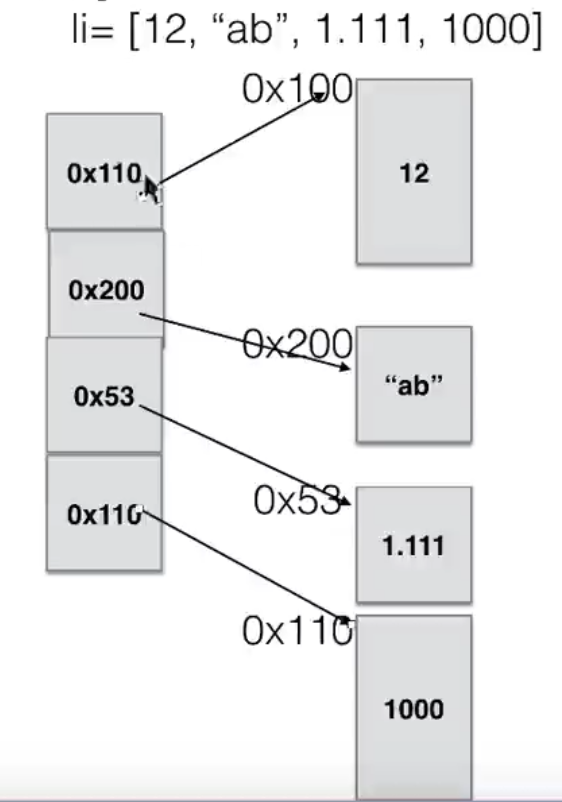
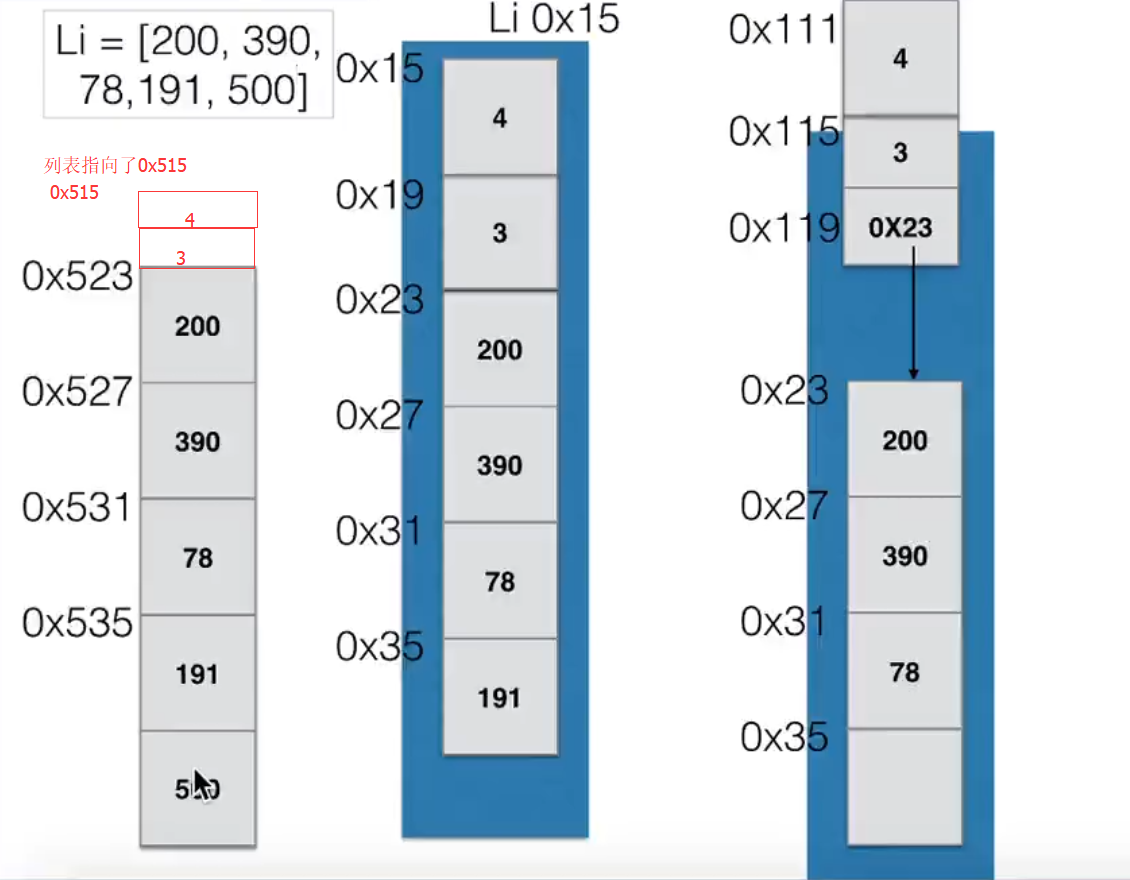
而列表作为python的数据类型,显然不能像数组一样存取数据,如果直接讲列表存储的数据放到内存空间,那么我们就无法直接索引了,python列表的做法于数组极为相似,只是他存储的时候使用的是存储数据的内存地址,这个内存地址大小是固定的,根据内存地址找到相应的地址存储的数据,所以列表不是一段连续的数据类型(如果列表中的数据类型一致,存在连续的内存空间是更好的选择)。
说了这么多其实要说明的就是,深浅拷贝就是拷贝列表的内存地址还是包括内存地址指向的数据一同拷贝的问题。
当一个变量使用多个对象时,旧的对象会被垃圾收回,那么变量共享变量的对象有事一种什么样的类型呢?
a=‘hello world’ b=a print(b) 运行结果: hello world
值得一提的是,这里b变量引用的a作为值,根据python中赋值是以对象来完成的,所以b引用的应该是a变量指向的对象地址的值,故可以判断,改变a指向的对象并不会影响b的值。
a=‘hello world’ b=a a='new hello world' print(a) print(b) 运行结果: new hello world hello world
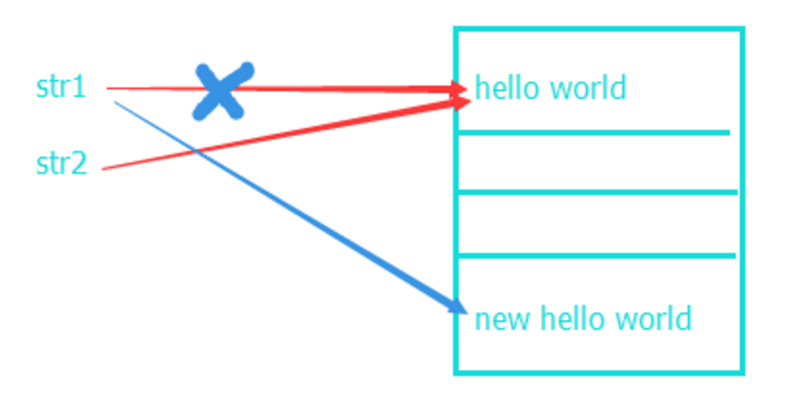
python中变量总是一个指定对象的指针,而不是能够改变内存区域的标签,即给一个变量赋新的值,不是替换一个对象原始值,而是创建一个新得对象供变量引用。
当然这条只限于对象的类型不可改变,如果引用对象是像列表一样可供修改的对象那结果如何呢?
a=[1,2,3] b=a a.append(4) print(a) print(b) 运行结果: [1, 2, 3, 4] [1, 2, 3, 4]
结果很显然,对于可变类型对象,变量不会创建一个显得对象,而是沿用之前的对象,即使对象已经被改变了。可以简单的理解为,两个对象同时指向了一个列表的内存地址,而列表又映射了里面各元素的内存地址,变量的共享并不关注列表的改变,他们只关心列表的内存空间是否改变,所以,可变对象在引用时自身可以改变,所以不需要创建新的对象,所以共享对象会随之前对象的变化而变化。
这其实是我们不希望看到的。我们可以使用拷贝对象创建引用:
a=[1,2,3] b=a[:] a.append(4) print(a) print(b) 运行结果: [1, 2, 3, 4] [1, 2, 3]
这种方法并不适用于不可索引但是可变的字典与集合,所以python的copy模块用于变量引用:
import copy a=[1,2,3,[1,2]] b=copy.copy(a)#这种拷贝方式与[:]是同样的效果 c=copy.deepcopy(a) d=a a.append(4) a[3][0]=5 print(a) print(b) print(c) print(d) 运行结果: [1, 2, 3, [5, 2], 4] [1, 2, 3, [5, 2]] [1, 2, 3, [1, 2]] [1, 2, 3, [5, 2], 4]
共享引用的补充
其实是关于垃圾回收的一点补充,对于一些小的整数或字符串,并不像我们说的那样计数器标记为0就被收回。这和python的缓存机制有关。对于一般的对象,python适用于垃圾收回。
a=[1,2,3] b=[1,2,3] c=a print(a == c) print(a == b) print(a is c) print(a is b) 运行结果: True True True False
对于小的整数与字符串则不同:
a=111 b=111 c=a print(a == c) print(a == b) print(a is c) print(a is b) 运行结果: True True True True
在python中,任何东西都是在赋值与引用中工作的,对于理解python动态类型,在以后的工作与学习时是有很大帮助的,这是python唯一的赋值模型,所以准确的理解与应用十分有必要。不对类型作约束,这使得python代码极为灵活,高效,并且省去了大量的代码,极为简洁,所以python是这样一门有艺术的编程。
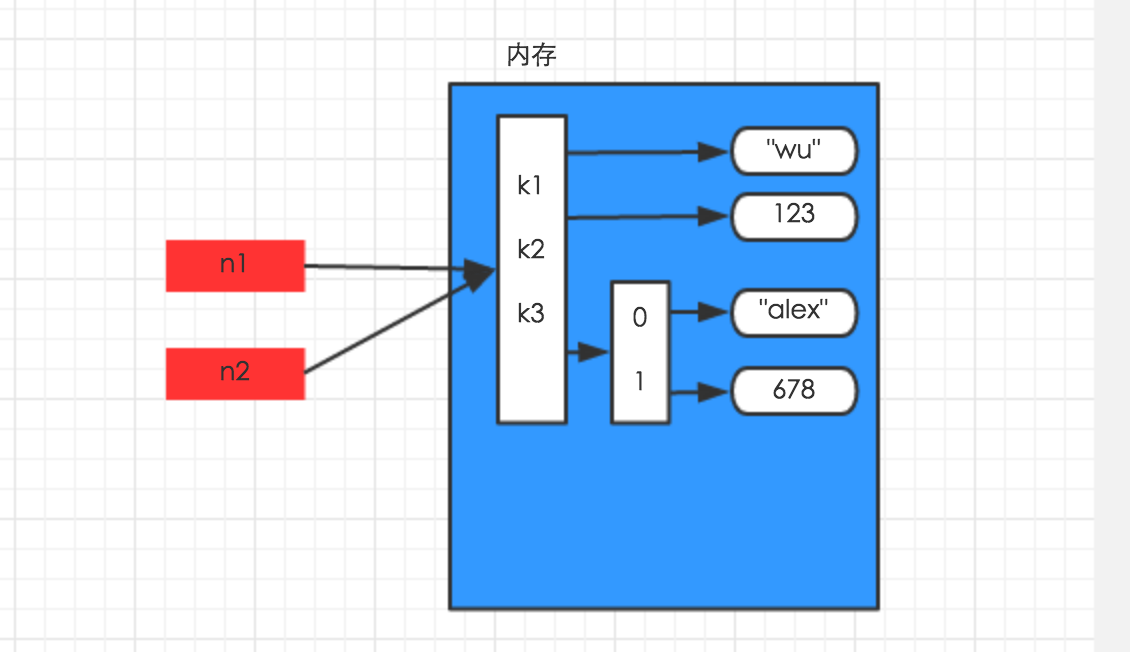
等于赋值的情况:
n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 678]}
n2 = n1
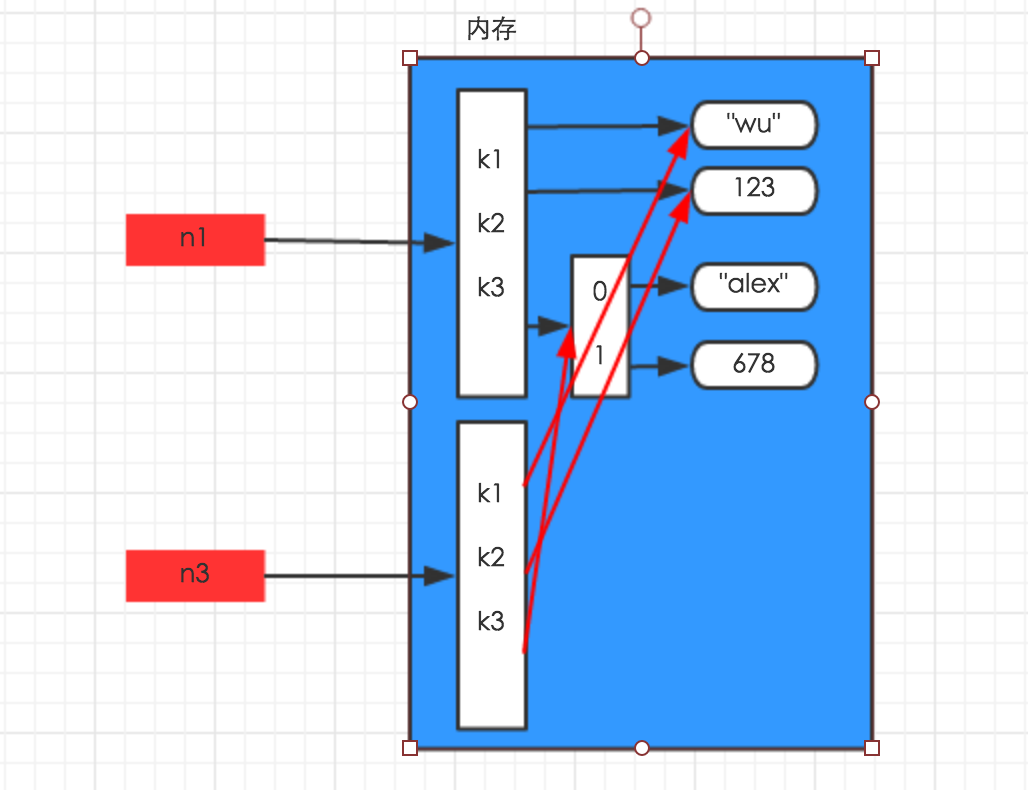
浅拷贝赋值:
import copy n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 678]} n3 = copy.copy(n1)
深拷贝:
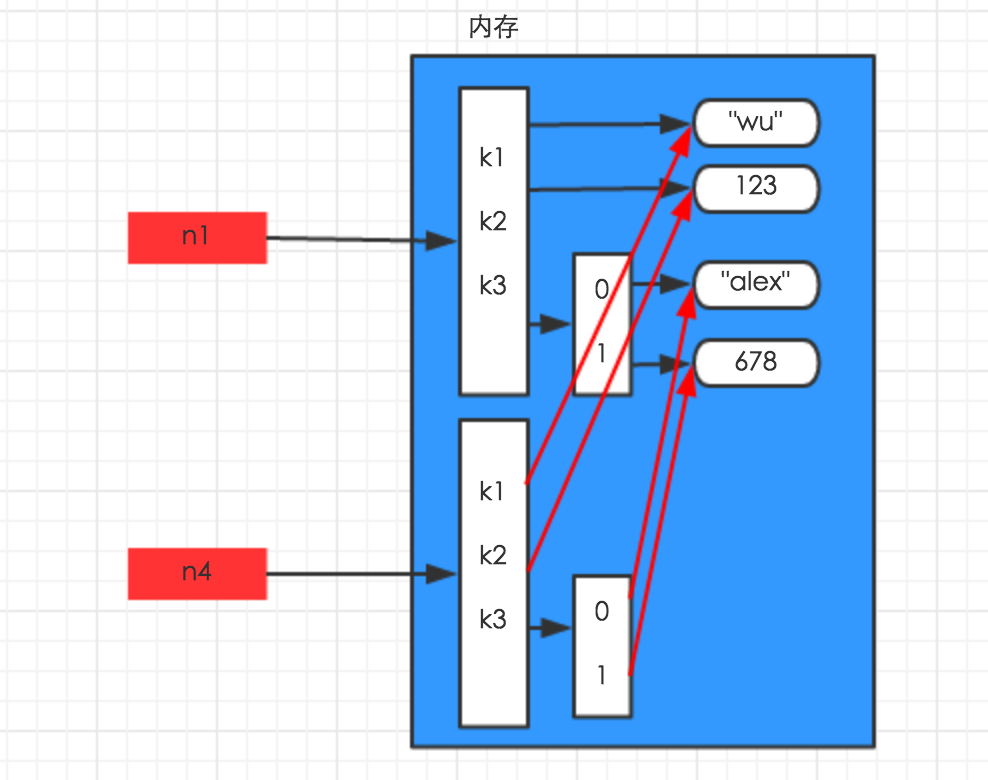
在http://www.cnblogs.com/adc8868/p/5647501.html博客中看到的,觉得解释的比文字好用,借鉴学习。
顺序表
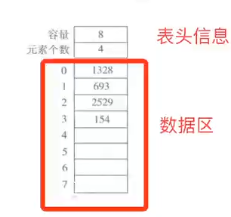
声明数组的时候就开辟了一块固定大小的内存空间,空间的头部空间写有数组容量及当前存放数。

两者的根本差异在于,如果数组数量增加,那么一体式将包括头部一同搬迁到新的物理空间,数组指向的起始内存位置改变了,但分离式只是将内存空间指向不同的位置,数组的起始位置未发生改变。
python列表的本质
Python中的list和tuple两种类型采用了顺序表的实现技术,具有前面讨论的顺序表的所有性质。
tuple是不可变类型,即不变的顺序表,因此不支持改变其内部状态的任何操作,而其他方面,则与list的性质类似。
Python标准类型list就是一种元素个数可变的线性表,可以加入和删除元素,并在各种操作中维持已有元素的顺序(即保序),而且还具有以下行为特征:
基于下标(位置)的高效元素访问和更新,时间复杂度应该是O(1);
为满足该特征,应该采用顺序表技术,表中元素保存在一块连续的存储区中。
允许任意加入元素,而且在不断加入元素的过程中,表对象的标识(函数id得到的值)不变。
为满足该特征,就必须能更换元素存储区,并且为保证更换存储区时list对象的标识id不变,只能采用分离式实现技术。
在Python的官方实现中,list就是一种采用分离式技术实现的动态顺序表。这就是为什么用list.append(x) (或 list.insert(len(list), x),即尾部插入)比在指定位置插入元素效率高的原因。
在Python的官方实现中,list实现采用了如下的策略:在建立空表(或者很小的表)时,系统分配一块能容纳8个元素的存储区;在执行插入操作(insert或append)时,如果元素存储区满就换一块4倍大的存储区。但如果此时的表已经很大(目前的阀值为50000),则改变策略,采用加一倍的方法。引入这种改变策略的方式,是为了避免出现过多空闲的存储位置。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号