
高并发文章浏览量计数系统设计
文章转自“荒野七叔 ” 链接 https://juejin.im/post/5c3aa3c86fb9a04a0e2d6c9f
来源平台 掘金
最近因为个人网站的文章浏览量计数在Chrome浏览器下有BUG,所以打算重新实现这个功能。
原本的实现很简单,每次点击文章详情页的时候,前端会发送一个GET请求articles/id获取一篇文章详情。这个时候,会把这篇文章的浏览量+1,再存进数据库里。
这个实现原本可以实现这个功能,但是后来我才发现,我犯了一个很致命的错误:在GET请求的业务逻辑里进行了数据的写操作!
原则来讲,GET请求应该具有幂等性,即短时间内同时两个一模一样的GET请求,返回的结果也应该是一样的。而我原本的实现就破坏了GET请求的幂等性。
恰好,在Chrome浏览器里,我的文章详情页会发送两次GET请求。这疑似Chrome浏览器和nuxt服务端渲染之间的一个BUG,目前还没有定位到具体原因。
但无论如何,后端应该是可以避免这样的BUG,即使某用户短时间内请求两次或者多次,也应该只增加一次浏览量计数。
由于最近在学习高并发方面的知识,所以这里也考虑一下,如果一个高并发的文章浏览量计数系统,应该如何设计?
先来理一下需求。
需求
- 用户可以是匿名的,不需要登录
- 每当一个用户点击了一个文章的详情页面,这个文章的浏览量应该+1
- 用户应该能立即看到自己点击文章后浏览量+1的反馈
- 浏览量这个数据存在Mysql和ElasticSearch里面,要最终一致(不要求强一致)
- 作者可能在后台编辑文章,然后保存文章。如果在这期间有浏览量的增加,保存文章的时候不应该覆盖掉这段时间的浏览量增量。
- 应该在服务端对用户的请求去重,防止用户不断刷新或者使用爬虫不断请求某个API(建议通过IP)
- 要过滤掉百度和谷歌的爬虫请求(根据User-Agent头判断,可以先不做)
- 要高性能地实现“查看浏览最多文章列表”的功能。
- 尽可能优化性能,满足多个用户的高并发需求。
设计思路
如果要满足高并发,那首先考虑用异步和缓存。所以考虑使用多线程加Redis的解决方案。
请求流程:
- 用户点击某篇文章详情页
- 前端发送一个
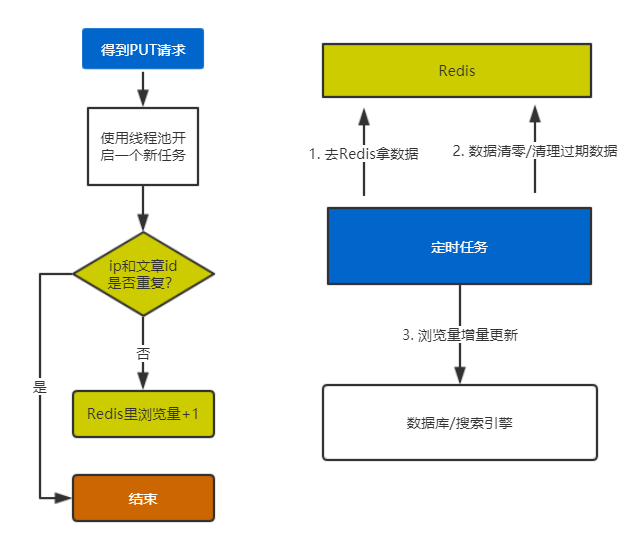
PUT请求/articles/{id:\\d+}/view。 - 后端使用线程池执行一个异步任务,立即返回给前端
200响应。 - 前端得到
200响应后,立即把当前文章的浏览量+1,满足需求3。
后端主要逻辑:
后端的主要思路是暂时把增加的浏览量(假设某篇文章为n)放进Redis里,然后每隔一段时间刷新到Mysql数据库和ElasticSearch存储里,让这篇文章的浏览量在现有的基础上加n,然后把Redis这篇文章的浏览量清零。
- 后端首先判断redis里时候有没有当前ip对这篇文章的浏览记录,这个key为:
isViewd:articleId:ip。如果有,就说明之前浏览过,就什么也不做,直接返回。如果没有,就加上这个key。时间可以设置为1小时过期,防止占用过多内存。这里使用Redis的string类型。 - 如果第5步的结果是没有,那就在Redis里给这篇文章的浏览量+1。Redis的这个支持原子操作,所以不用担心并发问题。key为
viewCount:articleId,value为缓存的浏览量。完成后当前线程任务就结束了。这里使用Redis的string类型。这些key应该没有过期时间。 - 弄一个定时任务,比如每5分钟,去Redis里拿缓存的浏览量,拿到后就更新到数据库和ElasticSearch里,并把Redis的数据清零。为了防止并发带来的问题,这里应该是拿到m,就在Redis里减去m,而不是直接设置为0。
- 为了节约内存,应该删除不必要的key,按照业务逻辑来看,如果一篇文章长时间没有人浏览,可能这篇文章比较“旧”了,我们可以考虑删除它在Redis里面的key。所以我们可以在第6步,每次在Redis里进行浏览量+1操作时,记录下一个时间戳。所以Redis可以使用hash类型,一个字段存最后操作时间,一个字段存浏览量。而在第7步里,我们可以顺便删除掉最后操作时间小于十天前的key。
- 保存更新文章的时候,应该只更新其它字段,而不更新浏览量这个字段。或者执行一遍第7步的逻辑。由于Redis加减操作的原子性,这里不用担心并发问题。如果当前线程把一篇文章的浏览量在Redis里减了m,那定时任务线程应该得到的是减了m之后的结果,所以数据会是一致的。
- 关于需求8,在并发量不算特别大的时候,我们还是去取数据库里面的数据,根据数据库里面的浏览量来排序,只是可以在应用里面给它加一个缓存,缓存时间应该与第7步定时任务一致,这里设置为5分钟。
如果并发量特别大,可以考虑不把浏览量存在数据库里,而仅存在Redis里,这样可以得到近乎实时的浏览量存储,而且需求8排序也是实时的(使用zset),但这样可能会耗费大量的内存资源。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号