
探索AC自动机:多关键词搜索的原理与应用案例
引言
目前,大多数自由文本搜索技术采用类似于Lucene的策略,通过解析搜索文本为各个组成部分来定位关键词。这种方法在处理少量关键词时表现良好。但当搜索的关键词数量达到10万个或更多时,这种方法的效率会显著下降,尤其是在需要与词典进行详尽对比的场景中。本文将介绍的Aho-Corasick(AC)自动机作为多模式匹配中的经典算法,不仅能够处理大规模文本数据,还能确保搜索过程的实时性和准确性。
AC自动机:文本搜索的革命性工具
AC自动机可以被形象地比喻为一个超级找词机器。想象你手头有一本内容繁多的书籍和一份包含多个词语的列表,你的任务是快速找出所有这些词语在书中出现的位置。如果采用传统方法,即逐个词进行查找,工作量将会非常巨大。而AC自动机通过构建一种特殊的树状结构——前缀树或Trie,来极大地提升搜索效率。
AC自动机构建与搜索机制
构建前缀树(Trie)
AC自动机首先会根据所有关键词构建一个前缀树。这种树状结构的每个节点代表一个字母,并且每个字母都指向下一个可能的字母,从而形成一个连续的路径,表示一个或多个关键词的前缀
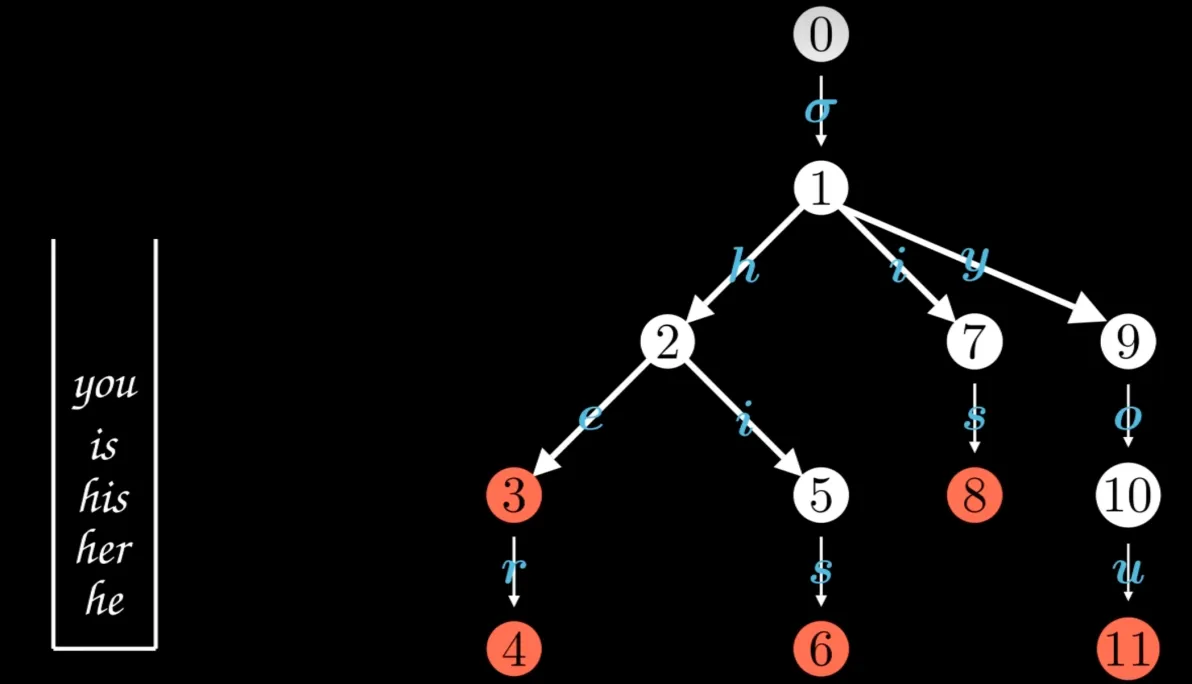
图片来源网络
失配指针(Fail指针)
在搜索过程中,如果当前路径上无法找到匹配的关键词,AC自动机会利用失配指针进行快速回溯。这些指针预先设置在树的每个节点上,指向其他可能的匹配路径,从而避免了从头开始搜索的低效性
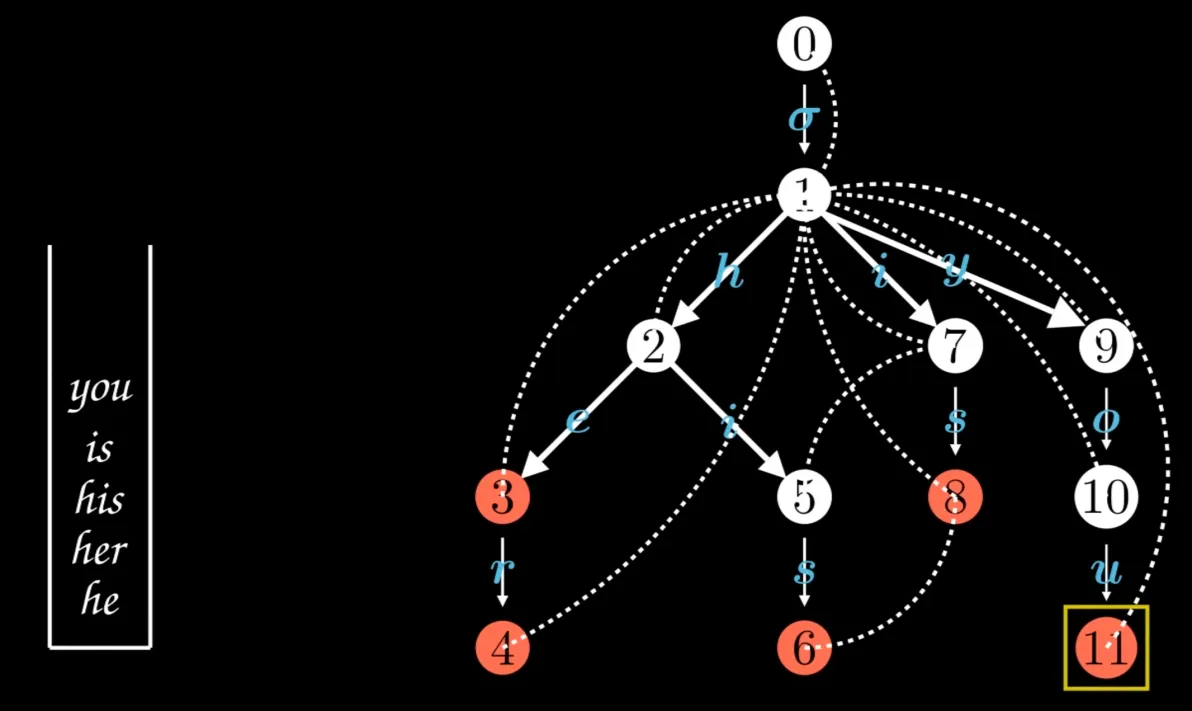
图片来源网络
实时搜索与高效报告
AC自动机在读取文本的同时,能够快速地遍历前缀树结构。一旦发现关键词出现在文本中,它能够立即报告这个词及其出现的位置。这种能力使得AC自动机能够一次性高效完成大量关键词的搜索任务
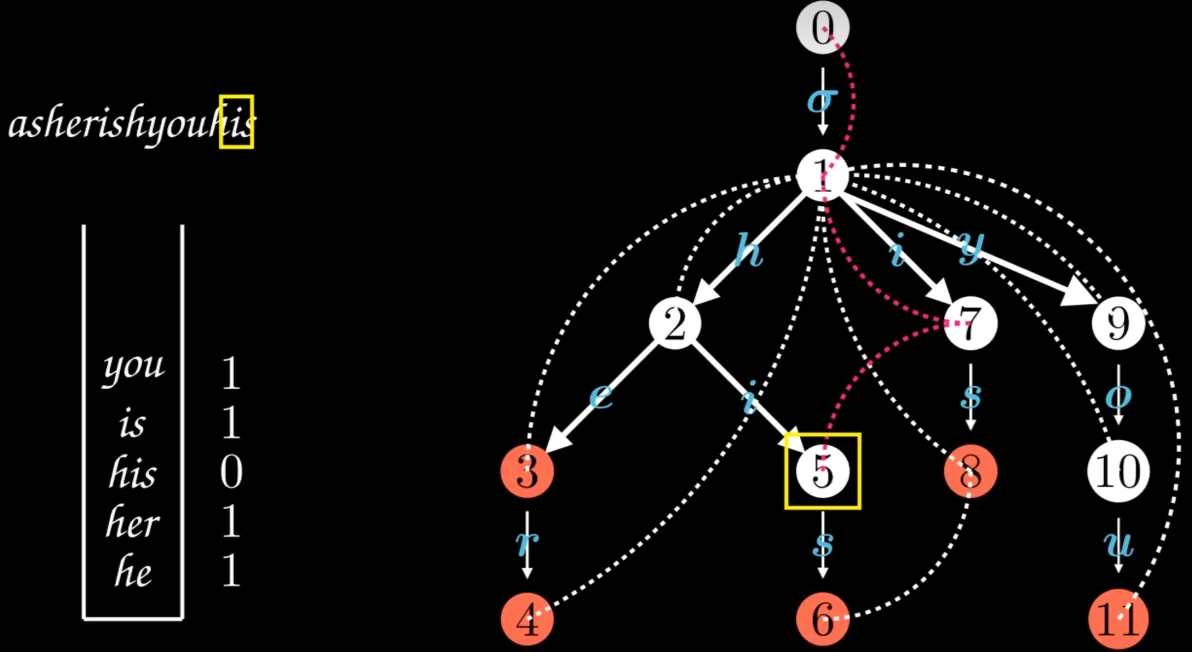
图片来源网络
算法核心组件与复杂度
核心组件:
goto(转跳):每个遇到的字符都会被提交给goto结构中的状态对象,以确定新的当前状态fail(失败转移):如果没有找到匹配状态,算法会触发fail并回溯至深度更浅的状态,从那里继续搜索output(输出):每当达到与整个关键词相匹配的状态时,该状态会被发送到输出集合中,完成扫描后即可读取这些匹配项时间复杂度:
Aho-Corasick算法的时间复杂度为O(n),其中n是文本的长度。这意味着无论提供多少关键词,搜索的性能都将呈线性下降,与关键词的数量无关。
AC自动机的应用
AC自动机在多种场景下都能发挥重要作用,包括:
应用案例:使用Aho-Corasick算法来识别和高亮HTML文本中的关键词
本Java程序将演示如何使用Aho-Corasick自动机库来搜索和高亮HTML文本中的关键词。程序首先构建一个自动状态机,该状态机被训练识别一系列中文关键词。然后,程序将处理HTML文档,查找这些关键词的出现,并用<b>标签将它们包裹起来,以实现加粗显示的效果。
第一步:Maven依赖配置,引入Aho-Corasick自动机库
<dependency>
<groupId>org.ahocorasick</groupId>
<artifactId>ahocorasick</artifactId>
<version>0.6.3</version>
</dependency>第二步:代码实现
public class HighlightKeywordsInHtml {
public static void main(String[] args) {
// 定义HTML内容的字符串,包含了南京大学的介绍
String htmlContent = createHtmlContentForNanjingUniversity();
// 创建Aho-Corasick Trie的构建器实例
Trie trie = buildAhoCorasickTrie();
// 使用Trie实例处理HTML文本,获取匹配的Token集合
Collection<Token> tokens = trie.tokenize(htmlContent);
// 使用StringBuilder构建最终的HTML字符串,用于输出高亮的关键词
StringBuilder html = new StringBuilder();
html.append("<html><body><p>");
// 遍历Token集合
for (Token token : tokens) {
// 如果Token匹配关键词,则添加<b>标签以实现加粗效果
if (token.isMatch()) {
html.append("<b>");
}
// 添加Token对应的文本片段
html.append(token.getFragment());
// 如果Token匹配关键词,结束<b>标签
if (token.isMatch()) {
html.append("</b>");
}
}
// 完成HTML字符串的构建
html.append("</p></body></html>");
// 打印最终的HTML字符串,其中包含高亮显示的关键词
System.out.println(html);
}
private static String createHtmlContentForNanjingUniversity() {
// 此处添加创建南京大学HTML内容的方法实现
String speech = """
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>南京大学简介</title>
<style>
body {
font-family: "微软雅黑", "宋体", Arial, sans-serif;
line-height: 1.6;
color: #333;
}
.university-intro {
text-align: justify;
margin-bottom: 2em;
padding: 1rem;
background-color: #f5f5f5;
border-radius: 5px;
}
</style>
</head>
<body>
<section class="university-intro">
<h1>南京大学:百年名校,学术卓越</h1>
<p>南京大学,简称“南大”,位于中国江苏省南京市,是中国最顶尖的高等学府之一,拥有百年的办学历史和深厚的文化底蕴。作为中国教育部直属的全国重点大学,南大以其卓越的学术成就和教育质量闻名于世。</p>
<p>南京大学以其强大的师资力量和学术研究而著称,提供多元化的学科教育,包括自然科学、人文社会科学、工程技术等多个领域。学校注重培养学生的创新能力和国际视野,为国家和社会培养了大量杰出人才。</p>
<p>南大校园环境优美,历史与现代交融,是学术研究和知识探索的理想场所。学校在计算机科学、地球科学、化学等学科领域具有国际领先水平,并在推动科学技术进步和文化传承方面发挥着重要作用。</p>
</section>
</body>
</html>
""";
return speech;
}
private static Trie buildAhoCorasickTrie() {
return Trie.builder()
.ignoreOverlaps() // 设置不捕获重叠的关键词
.onlyWholeWords() // 仅匹配完整的单词
.ignoreCase() // 忽略关键词的大小写
.addKeywords(Arrays.asList("南京大学", "南大", "地球科学"))
.build(); // 构建Trie实例
}
}第三步:运行程序,符合预期
<html><body><p><!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>南京大学简介</title>
<style>
body {
font-family: "微软雅黑", "宋体", Arial, sans-serif;
line-height: 1.6;
color: #333;
}
.university-intro {
text-align: justify;
margin-bottom: 2em;
padding: 1rem;
background-color: #f5f5f5;
border-radius: 5px;
}
</style>
</head>
<body>
<section class="university-intro">
<h1><b>南京大学</b>:百年名校,学术卓越</h1>
<p><b>南京大学</b>,简称“<b>南大</b>”,位于中国江苏省南京市,是中国最顶尖的高等学府之一,拥有百年的办学历史和深厚的文化底蕴。作为中国教育部直属的全国重点大学,南大以其卓越的学术成就和教育质量闻名于世。</p>
<p>南京大学以其强大的师资力量和学术研究而著称,提供多元化的学科教育,包括自然科学、人文社会科学、工程技术等多个领域。学校注重培养学生的创新能力和国际视野,为国家和社会培养了大量杰出人才。</p>
<p>南大校园环境优美,历史与现代交融,是学术研究和知识探索的理想场所。学校在计算机科学、<b>地球科学</b>、化学等学科领域具有国际领先水平,并在推动科学技术进步和文化传承方面发挥着重要作用。</p>
</section>
</body>
</html>
</p></body></html>本文对Aho-Corasick(AC)自动机算法进行了抛砖引玉,揭示了其在处理大规模文本数据方面的卓越性能和应用潜力。若你渴望深入挖掘AC算法的精髓,进一步探索其高级应用和实现细节,建议参考以下的参考资料进行进一步的学习与挖掘。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号