QPS提升10倍的sql优化
本次慢sql优化是大促准备时的一个优化,优化4c16g单实例mysql支持QPS从437到4610,今天发文时618大促已经顺利结束,该mysql库和应用在整个大促期间运行也非常稳定。本文复盘一下当时的sql优化过程
1. 问题背景
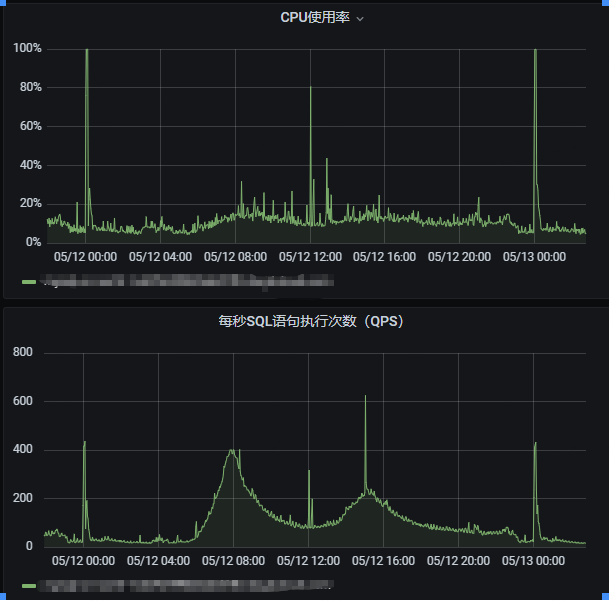
大促准备期间发现4c16G的单实例mysql数据库,每逢流量高峰都会有cpu 100%的问题,集中在0点和12点。
但也存在相近大小的流量cpu利用率相差很大的情况:从图中可见在5.12日0点查询437QPS时cpu利用率达到100%,而5.12日15:02分时 625QPS时CPU利用率不到20%
可见应该是查询语句有差异造成CPU利用率高,而此时并没有慢sql出现。
2. 问题分析
2.1 分析应用请求及日志
通过应用监控看到0点时流量大,很多路由排班表的本地缓存没有命中,导致查询较多。所以想到是否可以通过提高缓存命中率,减少sql查询,以降低CPU利用率。调整缓存大小,和缓存的有效期。经过测试验证仍然没有解决问题
2.2 分析sql
虽然没有慢sql出现,但还是分析了下sql。经分析sql 查询是不是用了索引,发现查询字段也是“走了idx_road_site索引”的(注意这里是引号,其实索引并未完全生效)
表结构及索引如下
CREATE TABLE `road_schedule` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`courier_id` VARCHAR(240) DEFAULT NULL COMMENT 'courier_id',
`courier_name` VARCHAR(240) DEFAULT NULL COMMENT 'courier_name',
`road_id` VARCHAR(240) DEFAULT NULL COMMENT 'road_id',
`site_id` VARCHAR(240) DEFAULT NULL COMMENT 'site_id',
`create_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',