
供应链场景使用ClickHouse最佳实践
关于ClickHouse的基础概念这里就不做太多的赘述了,ClickHouse官网都有很详细说明。结合供应链数字化团队在使用ClickHouse时总结出的一些注意事项,尤其在命名方面要求研发严格遵守约定,对日常运维有很大的帮助,也希望对读者有启发。
目前供应链数字化ck集群用来存储实时数据,先通过下面这张图表了解下ClickHouse数据来源。
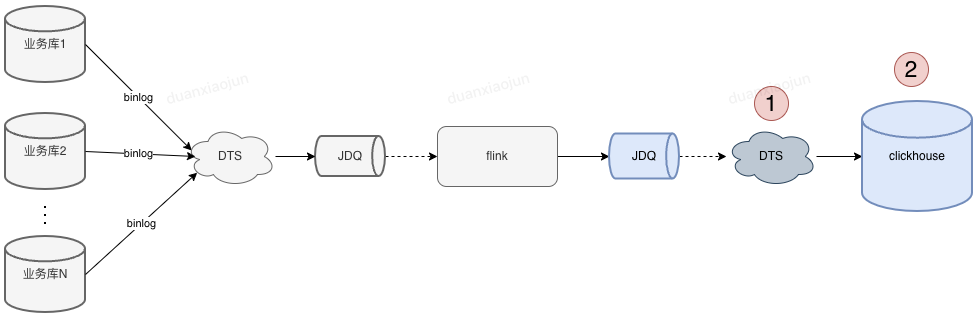
图中标注1和2的位置是供应链数字化研发在开发业务功能时改动量比较多的部分,随着需求变多,DTS任务和数据库表也越来越多。 通过定义研发使用约定,使我们的DTS任务、表、表字段看起来很整洁。
有哪些好处呢?
1、根据ck表名快速找到对应的DTS任务及消费jdq topic / 当然通过jdq也可快速找到对应的ck表(对不了解业务的人帮助很大)。
2、通过ck表字段即可知道该字段来自哪个业务表哪个字段(字段数据不对,联系业务值班先排查业务库的字段是否正确)。
3、快速统计到团队 或 某个ck集群有多少DTS任务(运维时不会遗漏,一目了然)
一 建表约定
1.1 表命名约定
表命名要求: 1、本地表命名必须_local结尾 2、分布式表命名必须以_all结尾;
--创建本地表, 使用on cluster default 在每个节点上都创建一张本地表
CREATE TABLE 本地表名 on cluster 集群名称
(
...
ts DateTime Default now() COMMENT '时间搓',
version UInt64 COMMENT '版本号'
) ENGINE = ReplicatedReplacingMergeTree('/clickhouse/tables/{shard}/test_local',
'{replica}',version)
[PARTITION BY expr] -- 数据分区规则
[ORDER BY expr] -- 排序键
[SAMPLE BY expr] -- 采样键
[SETTINGS index_granularity = 8192, ...] -- 额外参数
参数解释说明:
PARTITION BY toYYYYMM(tmsCreateTime) 按照月份分
ReplicatedReplacingMergeTree(参数1,参数2,参数3)
ORDER BY (参数1,参数2, ....);