HBase集群数据在线迁移方案探索
一、背景
订单本地化系统目前一个月的订单的读写已经切至jimkv存储,对应的HBase集群已下线。但存储全量数据的HBase集群仍在使用,计划将这个HBase集群中的数据全部迁到jimkv,彻底下线这个HBase集群。由于这个集群目前仍在线上读写,本文从原理和实践的角度探索对HBase集群数据的在线迁移的方案,欢迎大家补充。
二、基础理论梳理
HBase整体架构
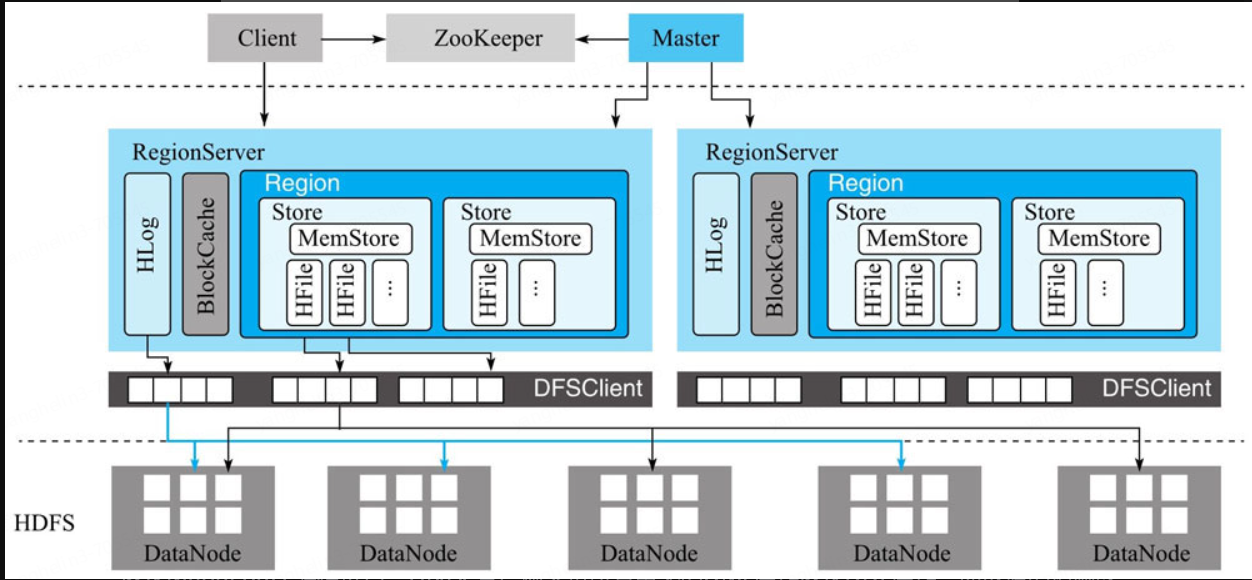
重温一下各个模块的职责
HBase客户端
HBase客户端(Client)提供了Shell命令行接口、原生Java API编程接口、Thrift/REST API编程接口以及MapReduce编程接口。HBase客户端支持所有常见的DML操作以及DDL操作,即数据的增删改查和表的日常维护等。其中Thrift/REST API主要用于支持非Java的上层业务需求,MapReduce接口主要用于批量数据导入以及批量数据读取。HBase客户端访问数据行之前,首先需要通过元数据表定位目标数据所在RegionServer,之后才会发送请求到该RegionServer。同时这些元数据会被缓存在客户端本地,以方便之后的请求访问。如果集群RegionServer发生宕机或者执行了负载均衡等,从而导致数据分片发生迁移,客户端需要重新请求最新的元数据并缓存在本地。
Master
Master主要负责HBase系统的各种管理工作:
RegionServer
RegionServer主要用来响应用户的IO请求,是HBase中最核心的模块,由WAL(HLog)、BlockCache以及多个Region构成。
对于带有大量热点读的业务请求来说,缓存机制会带来极大的性能提升。BlockCache缓存对象是一系列Block块,一个Block默认为64K,由物理上相邻的多个KV数据组成。BlockCache同时利用了空间局部性和时间局部性原理,前者表示最近将读取的KV数据很可能与当前读取到的KV数据在地址上是邻近的,缓存单位是Block(块)而不是单个KV就可以实现空间局部性;后者表示一个KV数据正在被访问,那么近期它还可能再次被访问。当前BlockCache主要有两种实现——LRUBlockCache和BucketCache,前者实现相对简单,而后者在GC优化方面有明显的提升。
一个Region由一个或者多个Store构成,Store的个数取决于表中列簇(column family)的个数,多少个列簇就有多少个Store。HBase中,每个列簇的数据都集中存放在一起形成一个存储单元Store,因此建议将具有相同IO特性的数据设置在同一个列簇中。每个Store由一个MemStore和一个或多个HFile组成。MemStore称为写缓存,用户写入数据时首先会写到MemStore,当MemStore写满之后(缓存数据超过阈值,默认128M)系统会异步地将数据f lush成一个HFile文件。显然,随着数据不断写入,HFile文件会越来越多,当HFile文件数超过一定阈值之后系统将会执行Compact操作,将这些小文件通过一定策略合并成一个或多个大文件。
HDFS
HBase底层依赖HDFS组件存储实际数据,包括用户数据文件、HLog日志文件等最终都会写入HDFS落盘。HDFS是Hadoop生态圈内最成熟的组件之一,数据默认三副本存储策略可以有效保证数据的高可靠性。HBase内部封装了一个名为DFSClient的HDFS客户端组件,负责对HDFS的实际数据进行读写访问。
三、数据迁移方案调研
1、如何定位一条数据在哪个region
HBase一张表的数据是由多个Region构成,而这些Region是分布在整个集群的RegionServer上的。那么客户端在做任何数据操作时,都要先确定数据在哪个Region上,然后再根据Region的RegionServer信息,去对应的RegionServer上读取数据。因此,HBase系统内部设计了一张特殊的表——hbase:meta表,专门用来存放整个集群所有的Region信息。
hbase:meta表的结构如下,整个表只有一个名为info的列族。而且HBase保证hbase:meta表始终只有一个Region,这是为了确保meta表多次操作的原子性。
hbase:meta的一个rowkey就对应一个Region,rowkey主要由TableName(业务表名)、StartRow(业务表Region区间的起始rowkey)、Timestamp(Region创建的时间戳)、EncodedName(上面3个字段的MD5 Hex值)4个字段拼接而成。每一行数据又分为4列,分别是info:regioninfo、info:seqnumDuringOpen、info:server、info:serverstartcode。
为了解决如果所有的流量都先请求hbase:meta表找到Region,再请求Region所在的RegionServer,那么hbase:meta表的将承载巨大的压力,这个Region将马上成为热点Region这个问题,HBase会把hbase:meta表的Region信息缓存在HBase客户端。在HBase客户端有一个叫做MetaCache的缓存,在调用HBase API时,客户端会先去MetaCache中找到业务rowkey所在的Region。

2、HBase client Scan用法
HBase客户端提供了一系列可以批量扫描数据的api,主要有ScanAPI、TableScanMR、SnapshotScanM
HBase client scan demo
public class TestDemo {
private static final HBaseTestingUtility TEST_UTIL=new HBaseTestingUtility();
public static final TableName tableName=TableName.valueOf("testTable");
public static final byte[] ROW_KEY0=Bytes.toBytes("rowkey0");
public static final byte[] ROW_KEY1=Bytes.toBytes("rowkey1");
public static final byte[] FAMILY=Bytes.toBytes("family");
public static final byte[] QUALIFIER=Bytes.toBytes("qualifier");
public static