
关于Vearch在大模型中使用的一些实践
背景
这两年来大模型及其热门,不仅各大厂家的模型层出不穷,各类RGA、Agent应用也花样繁多。这也带火了一批基础设施,比如Langchain、向量数据库(也叫矢量数据库-Vector Database)等。现在市场上的向量库种类特别繁多,但主要还是分为两类,一类是在原有数据库基础上增加了向量相似性检索的能力,比如ES、Redis等等;还有一类就是生而为向量库,比较有名的比如Qdrant、Pinecone等等。最近我们在开发一个基于大模型的测试用例生成的应用,检索采用向量库+知识图谱的混合检索方式。在调研向量数据库时,发现公司有类似的产品,也就是Vearch。并且这款产品开源比较早,也比较成熟,目前已集成到Langchain框架中,所以我们也采用了集团部署的Vearch。这样可以免去部署的烦恼,最重要的是不需要我们去找GPU资源😩(向量计算GPU更为高效,Vearch也支持CPU计算)。
浅引
Vearch诞生之初,主要是用在深度学习上,可以进行海量数据的近似检索。后来大模型开始流行,问答机器人此类应用变得广泛。使用时,只要将问题&答案或者一段文本录入库中,通过检索问题文本向量,即可返回近似文本内容。关于Vearch的底层架构及原理,这里不再讲述(之前Vearch的元老在神灯已经写了很多文章了,感兴趣的可自行搜索)。Vearch的核心存储及检索引擎是Gamma(哎?看到这个是不是很眼熟哇,那个模型叫Gemma,不是一个东西哈),主要负责向量的存储,索引与检索。它是基于Faiss(脸书的向量聚类库)中的SIMD指令实现(这是Vearch的先驱们写的原始论文 https://arxiv.org/abs/1908.07389)。相比于Faiss,Vearch最大的能力是在于对分布式的支持,所用的算法称为分布式最邻近搜索,它在原始KNN基础上集成了更多的能力(可参考: https://towriting.com/blog/2021/10/07/vearch/ )。关于更底层使用的余弦计算、KNN(最邻近搜索)等概念,就不在本篇范围内了。
这里再简单说两句,大模型为什么要用向量检索库(一个点铺开都有很多内容😢)。最近有一种项目比较流行,就是知识库,它是基于大模型能力的一种扩展。因为目前大模型存在两个问题,其一对于专属领域的知识理解不好,容易幻觉举个栗子,你问GPT关于京东营销中心的业务,它就只能自己捏造了;其二,它的训练数据存在滞后性,做不到对最新知识的理解。当然你要是有资源,也可以用这些知识去对模型进行微调,但对于我们这种一点资源没有的用户来说,这不是最优解。所以聪明的人们就整出了一套叫RAG的技术(检索增强生成),通过预检索提前录入的向量化知识,将检索的内容嵌入到问题的提示词模板中,这样传给大模型后,以更准确的获取答案。这里又涉及到一个概念了-嵌入(Embedding),这里不细说了,因为涉及到向量化,后面会简单说明,本篇主要还是讲Vearch的使用。
项目简述
大模型火热了这么久,我们也在积极研究如何应用到测试上,并给测试提效。结合我们营销中心、策略等系统繁杂业务的特性,希望有一种可以一键输出测试用例的能力,这样可以帮助我们节省用例编写的时间。而这之前,我们先需要完成知识库(业务知识、测试经验、系统上下)的建立,包括知识文档的整理、知识的录入与检索,知识图谱的创建等等。有了RGA,我们就可以根据知识库以及给定的需求文档,进行测试用例生成。

目前我们的项目还在开发中,所以本篇的目的在于借助该项目介绍其中的一块--向量数据库Vearch的使用。
集群库创建
Vearch架构,它由三部分组成Master、Router、Ps。Master负责集群元数据的管理和资源的协调分配;Router负责请求路由转发及结果合并;Ps用于存储和检索向量。Vearch目前已经集成到泰山,在使用前需要先申请一个集群库,从集群列表中可以看到,每个部分默认有三台机器,确保高可用。
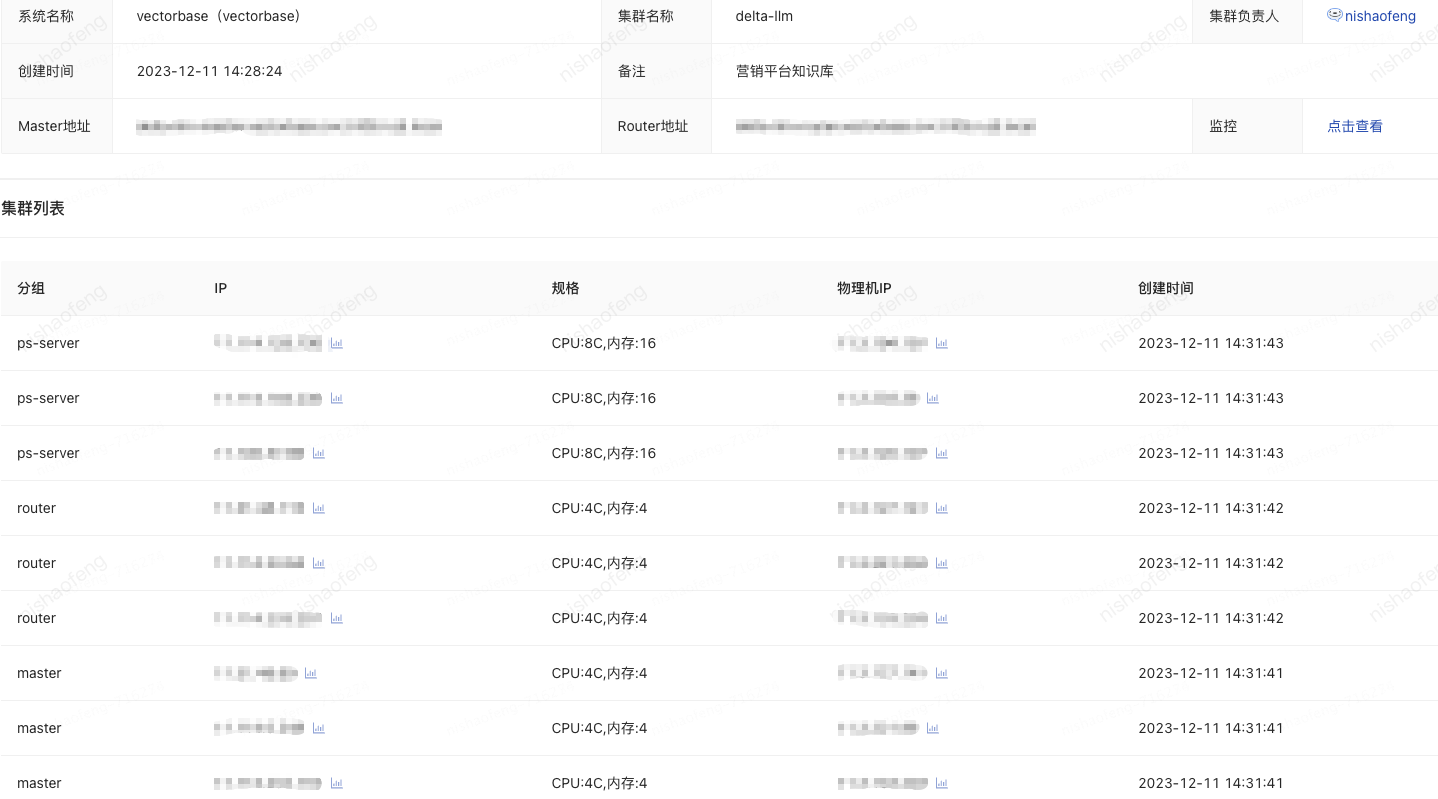
然后它有两个地址,一个Master地址,一个Router地址。
Master地址:用于库表维度的创建、删除等
Router地址:用于数据维度的插入、删除、检索等,不过现在也已兼容旧版本的Master,所以表操作直接用Router也没问题。
需要知道的是,目前Vearch暂未支持表结构修改能力,但新版本已经在支持中。
功能导入
因为我们的项目使用Langchain开发,而且Vearch以及集成进去了,所以刚开始我们使用的就是Langchain的版本
from langchain_community.vectorstores.vearch import Vearch
这个版本比最新开源的SDK版本略旧,只支持固定字段,但是最新的开源版本已经兼容多字典。跟Vearch的同学讨论后,决定还是直接导入Github上开源的最新SDK,将下面这个文件内容复制到项目工程目录下就行。
然后从本地的Vearch文件引用即可。
from ..(路径)/Vearch文件名 import Vearch表空间创建
Vearch将操作全都封装成了接口,所以并不需要写类似SQL那样的语句。我们现在要创建一个名为delta_llm_embedding的表,可以通过两种方式:
自定义建表
可以在泰山的操控台进行操作,或在你的本地dos/MACshell的中控台进行操作。这里不分别截图演示了,毕竟不是写操作手册。本地建表语句如下:
curl -XPUT -H "content-type: application/json" -d'
{
"name": "delta_llm_embedding",
"partition_num": 3,
"replica_num": 3,
"engine": {
"index_size": 1,
"metric_type": "InnerProduct",
"retrieval_type": "HNSW",
"retrieval_param": {
"nlinks": 32,
"metric_type": "InnerProduct",
"efSearch": 64,
"efConstruction": 160
}
},
"properties": {
"text": {
"type": "string",
"index": true
},
"text_embedding": {
"dimension": 1536,
"type": "vector",
"store_param": {
"cache_size": 2048,
"compress": {"rate":16}
}
}
}
}
' http://master_server(Master地址)/space/db/_create
上面的字段意思官方文档里都有(https://vearch.readthedocs.io/zh-cn/latest/),这里就不一一解释了。需要重点说的是两点,一点是字段名,我们定义了两个字段,一个是文本字段text,一个是向量字段text_embedding。至于为什么用这两个名称也是踩过的坑,才知道有多深,稍后说。另外一点就是dimension,这个是向量维度,理论上来讲维度越高,召回越精准。但这个数据完全依赖于你的嵌入模型所能输出的维数,因为我们用的Openai的Embeddings模型:text-embedding-ada-002,看下图

我们再说下为什么那两个字段名(文本字段text,向量字text_embedding)要这么取,先看下Vearch的SDK源码,在插入数据的那段是这么写的:
...
...
for text, metadata, embed inzip(texts, metadatas, embeddings):
profiles:dict[str, Any]={}
profiles["text"]= text
for f in meta_field_list:
profiles[f]= metadata[f]
embed_np = np.array(embed)
profiles["text_embedding"]={
"feature":(embed_np / np.linalg.norm(embed_np)).tolist()
}
insert_res = self.vearch.insert_one(
self.using_db_name, self.using_table_name, profiles
)
...可以看到两个字段名是写死的,这也是一开始我们建表的字段名跟这个并不一致,导致我们花了不少时间来跟Vearch的同学排查问题的原因。至于SDK里为什么会这么写,原因是基于已有Vearch SDK以及Langchain的规定,必要字段被指定,其他字段可根据用户需要自适应设置。
vearch_cluster初始化
如果你一开始不去自行建表,而是直接在工程代码中使用SDK的初始化能力,则可以采用该种方式,这种方式你并不需要关注表结构,vearch_cluster会自行初始化一个表,你只需要告诉它表名即可。
vearch_cluster = Vearch.from_documents(
texts,
OpenAIEmbeddings(
model="text-embedding-ada-002",
openai_api_key=OPENAI_API_KEY,
openai_api_base=OPENAI_API_BASE
),
path_or_url="http://router_server(Router地址)",
table_name="delta_llm_embedding",
db_name="db",
flag=1
)如果自行建表,我们可以任意建字段,想存什么就存什么,但是带来的问题就是没法使用vearch_cluster进行初始化检索,除非你的字段是一致的。如果你预建好了表,字段也正确,那么vearch_cluster在初始化时,它会跳过建表这一步,直接插入数据,或进行检索。至于vearch_cluster初始化时,建表字段为什么只有这两个,那是因为早期这个SDK是给问答机器人使用的,那时候并没有考虑到后面在其他地方的使用,当然现在新版本已经在路上了。好了,创建就说这么多吧,至于删除,可以自行查询官方文档,进行操作。
数据存储
现在我们知道建表时有两个字段,一个是文本字段,一个是Embedding字段,也就是向量数据字段。在浅引里已经说过,Vearch本身只提供存储及检索能力,所以向量化是需要依赖外部工具来完成的。过程就是:文本块>Embedding>存储>检索。当然这之前,我们需要对文档进行切割,将文档按照一定的规则切割成文本块。这部分本篇就不细说了,不然就跑题了。
我们项目使用的是Openai的Embeddings模型,从上面的vearch_cluster初始化对象中可以看出,我们使用的模型是Openai的text-embedding-ada-002。在初始化时,它会调用OpenAIEmbeddings这个类完成对texts文本的向量化,并进行建表落库。OpenAIEmbeddings是Langchain集成的Openai调用的能力。当然你也可以不使用vearch_cluster的from_documents方法,自己定义一个向量化方法,当然这会带来额外的工作量,需要自己写数据落库的方法(调Vearch的相关接口)。
#自定义向量化方法
defchunk_embeddings(chunk):
embeddings = OpenAIEmbeddings(
model="text-embedding-ada-002",
openai_api_key=OPENAI_API_KEY,
openai_api_base=OPENAI_API_BASE
)
query_result = embeddings.embed_query(chunk)
return query_result比如,现在有一小段文本:营销中心,将它嵌入后Openai的Embeddings模型会返回一个长度是1536的数组:
[-0.0056166304,-0.019372676,0.0055335015,-0.018635359,-0.013734359,0.019025704,-0.026355514,-0.012151293,-0.0065816496,-0.008652647,0.0049299123,0.023261668,-0.0033992538,-0.015599342,-0.014319877,0.0019336534,...,-0.0068238084]
然后调用Vearch的数据写入接口(这里如果使用SDK的初始化,就不用自己写存储了,vearch_cluster都帮你做了)。落库时「营销中心」写入text字段,数组写入text_embedding。这里需要注意的是,数组的长度要跟建表时的维度一致,否则数据写入失败。如果写入成功,我们会收到这样的返回:
{
"_index": "db",
"_type": "delta_llm_embedding",
"_id": "-3705827531945023546",
"status": 200
}
这里的_id,就是记录的唯一id了,我们可以通过它检索到这条详细的数据。在中控台里执行这个接口:
get http://router_server/db/delta_llm_embedding/-3705827531945023546
#返回数据
{
"_index": "db",
"_type": "delta_llm_embedding",
"_id": "-3705827531945023546",
"found": true,
"_source": {
"_id": "-3705827531945023546",
"text_embedding": {
"feature": [-0.0056166304,-0.019372676,0.0055335015,-0.018635359,-0.013734359,0.019025704,-0.026355514,-0.012151293,-0.0065816496,-0.008652647,0.0049299123,0.023261668,-0.0033992538,-0.015599342,-0.014319877,0.0019336534,...,-0.0068238084]
"source": ""
},
"text": "营销中心"
}
}
这里简单拓展下Embedding,翻译过来是嵌入,或者词嵌入。这是个有点让人头秃的名词。之前有人说过“没有思考过 Embedding,不足以谈 AI”,可见它在AI领域的重要性。当然如果不理解,也不影响我们的使用。
关于这个词,维基的解释是指把一个维数为所有词的数量的高维空间嵌入到一个维数低得多的连续向量空间中,每个单词或词组被映射为实数域上的向量。
好吧,更不好理解了。这句话的核心是将高维的对象映射到低维的空间,Embedding就是将一个离散的词映射成一个N维的数组向量,这组向量表示的是一个连续的数值空间中的点,也就是空间位置。说白点,就是将自然词通过向量化,嵌入到计算机的语言模型中,这个模型是它对人类语言对象的理解。鄙人能力有限,就不做继续深入了。
人工智能的奥义是「万物皆可Embedding」,不管是图片、文本、对象还是什么,都可以嵌入。这个技术它主要用在机器学习以及自然语言处理中,因为自然语言语意复杂多变,要想让计算机理解人类语言却不是一件简单的事。词与词之间的相关性通过距离进行量化,我们可以想象一堆词语,计算机在空间维度上对其进行聚类,词义相近的放一起,不相近的远离,所有词语之间都有一个方向和距离。最后检索时,通过这些向量进行余弦计算,得出排序分数。
数据检索
现在我们将文档「营销运营策略业务全景介绍」录入知识库中,我们需要根据问题进行内容检索。Vearch目前支持两种检索方式,文本检索、向量检索。
文本检索
这里我们使用了官方提供的similarity_search方法进行检索
question ="营销运营策略业务包括哪些?"#检索问题内容
cluster_res = vearch_cluster.similarity_search(query=question, k=1)我们看下这个方法,通过传入需要检索的问题内容,先对其进行向量化,然后再调了向量化的检索方法similarity_search_by_vector,通过计算向量的余弦值,对文本块做一个整体的排序,然后召回前k个文本。
def similarity_search(
self,
query:str,
k:int= DEFAULT_TOPN,
**kwargs: Any,
)-> List[Document]:
"""
Return docs most similar to query.
"""
if self.embedding_func isNone:
raise ValueError("embedding_func is None!!!")
embeddings = self.embedding_func.embed_query(query)
docs = self.similarity_search_by_vector(embeddings, k)
return docs因为每次检索时,都是一次余弦计算,而维度越多,则计算消耗越大。
检索后,获得了如下内容:
营销运营策略是基于商品、券、内容等多维度的调控策略平台,支持各种营销活动。目前主要包含商品调控策略、权益调控策略、百补风控策略和内容调控策略...
注意这里检索的内容只是从Vearch中检索到的内容,并非大模型返回的内容。我们拿到这个检索的文本后,还需要将它嵌到提示词模板中,进行模板格式化后传给大模型,达到对大模型进行知识补充的目的。
向量检索
向量检索调用,跟上面的文本检索就类似了,只是使用的方法是similarity_search_by_vector,这也是上面文本检索中所调用的方法,当然参数也就变成了向量化的文本。
question_embedding =[0.04036456,-0.0073514967,0.026557915,-0.0005227189...]
cluster_res = vearch_cluster.similarity_search_by_vector(query=question_embedding, k=1)关于这个方法,这边就不细说了,属于Vearch的核心能力,想研究的可以看源代码,自行查询(https://github.com/vearch/vearch/blob/master/sdk/integrations/langchain/vearch.py)。
总结
以上主要就是我们在该项目中所使用的Vearch主要能力,即存储跟检索。从整体使用感受来讲,功能基本满足要求,性能也不差,上手难度也不高,关键还开源。但是相比于外面已经完全实现平台化的商业产品来说,因为Vearch所有的能力都是接口封装的,写数查询这些日常操作略有麻烦,对于咱们用惯了关系数据库的新手来说稍有不适。
另外在调研Vearch时,发现已有不少业务团队将Vearch用于业务能力上,比如推荐、查重等。虽然目前营销中心的业务模块并未用到该产品,但对于我们来说是一种知识与技能拓展,并对后续的测试给出新的视野和思路。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号