
一招MAX降低10倍,现在它是我的了
一.背景
性能优化是一场永无止境的旅程。
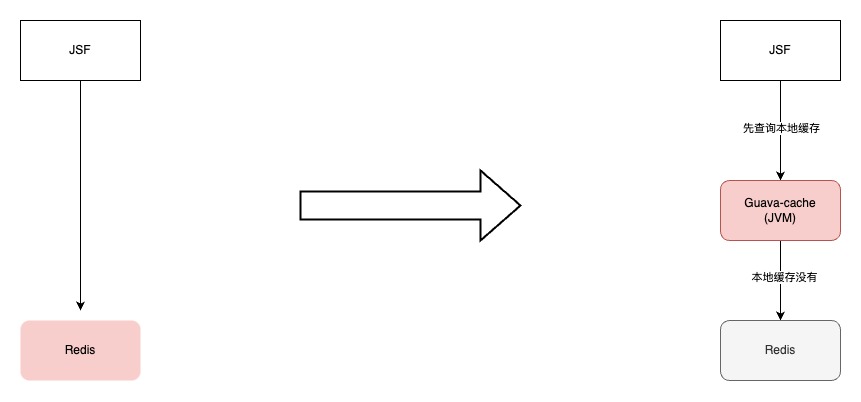
到家门店系统,作为到家核心基础服务之一,门店C端接口有着调用量高,性能要求高的特点。
C端服务经过演进,核心接口先查询本地缓存,如果本地缓存没有命中,再查询Redis。本地缓存命中率99%,服务性能比较平稳。
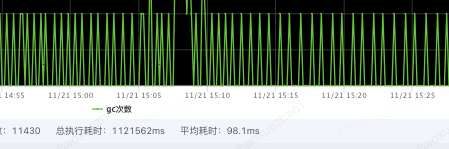
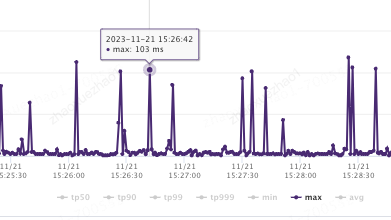
随着门店数据越来越多,本地缓存容量逐渐增大到3G左右。虽然对垃圾回收器和JVM参数都进行调整,由于本地缓存数据量越来越大,本地缓存数据对于应用GC的影响越来越明显,YGC平均耗时100ms,特别是大促期间调用方接口毛刺感知也越来越明显。
由于本地缓存在每台机器上容量是固定的,即便是将机器扩容,对与GC毛刺也没有明显效果。
二.初识此物心已惊-OHC初识
本地缓存位于应用程序的内存中,读取和写入速度非常快,可以快速响应请求,无需额外的网络通信,但是一般本地缓存存在JVM内,数据量过多会影响GC,造成GC频率、耗时增加;如果用Redis的话有网络通信的开销。
| 简介 | 特点 | 堆外缓存 | 性能(一般情况) | |
| Guava Cache | Guava Cache是Google的本地缓存库,提供了基本的缓存功能。它简单易用、轻量级,并支持基本的缓存操作。 | ·支持最大容量限制 ·支持两种过期删除策略(插入时间和访问时间) ·支持简单的统计功能 ·基于LRU算法实现 | 不支持 | 性能中等 |
| Caffeine | Caffeine是一个高性能的本地缓存库,提供了丰富的功能和配置选项。它支持高并发性能、低延迟和一些高级功能,如缓存过期、异步刷新和缓存统计等。 | ·提供了丰富的功能和配置选项;高并发性能和低延迟;支持缓存过期、异步刷新和缓存统计等功能; ·基于java8实现的新一代缓存工具,缓存性能接近理论最优。 ·可以看作是Guava Cache的增强版,功能上两者类似,不同的是Caffeine采用了一种结合LRU、LFU优点的算法:W-TinyLFU,在性能上有明显的优越性 | 不支持 | 性能出色 |
| Ehcache | Encache是一个纯Java的进程内缓存框架,具有快速、精干等特点,是Hibernate中默认的CacheProvider。同Caffeine和Guava Cache相比,Encache的功能更加丰富,扩展性更强 | ·支持多种缓存淘汰算法,包括LRU、LFU和FIFO ·缓存支持堆内存储、堆外存储、磁盘存储(支持持久化)三种 ·支持多种集群方案,解决数据共享问题 | 支持 | 性能一般 |
| OHC | OHC(Off-Heap Cache)是一个高性能的堆外缓存库,专为高并发和低延迟而设计。它使用堆外内存和自定义的数据结构来提供出色的性能 | ·针对高并发和低延迟进行了优化;使用自定义数据结构和无锁并发控制;较低的GC开销; ·在高并发和低延迟的缓存访问场景下表现出色 | 支持 | 性能最佳 |
通过对本地缓存的调研,堆外缓存可以很好兼顾上面的问题。堆外缓存把数据放在JVM堆外的,缓存数据对GC影响较小,同时它是在机器内存中的,相对与Redis也没有网络开销,最终选择OHC。
三.习得技能心自安-OHC使用
talk is cheap, show me the code! OCH是骡子是马我们遛一遛。
1.引入POM
OHC 存储的是二进制数组,需要实现OHC序列化接口,将缓存数据与二进制数组之间序列化和反序列化。
这里使用的是Protostuff,当然也可以使用kryo、Hession等,通过压测验证选择适合的序列化框架。
<!--OHC相关-->
<dependency>
<groupId>org.caffinitas.ohc</groupId>
<artifactId>ohc-core</artifactId>
<version>0.7.4</version>
</dependency>
<!--OHC 存储的是二进制数组,所以需要实现OHC序列化接口,将缓存数据与二进制数组之间序列化和反序列化-->
<!--这里使用的是protostuff,当然也可以使用kryo、Hession等,通过压测验证选择适合的-->
<dependency>
<groupId>io.protostuff</groupId>
<artifactId>protostuff-core</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>io.protostuff</groupId>
<artifactId>protostuff-runtime</artifactId>
<version>1.6.0</version>
</dependency>2.创建OHC缓存
OHC缓存创建
OHCache<String, XxxxInfo> basicStoreInfoCache = OHCacheBuilder.<String, XxxxInfo>newBuilder()
.keySerializer(new OhcStringSerializer()) //key的序列化器
.valueSerializer(new OhcProtostuffXxxxInfoSerializer()) //value的序列化器
.segmentCount(512) // 分段数量 默认=2*CPU核数
.hashTableSize(100000)// 哈希表大小 默认=8192
.capacity(1024 * 1024 * 1024) //缓存容量 单位B 默认64MB
.eviction(Eviction.LRU) // 淘汰策略 可选LRU\W_TINY_LFU\NONE
.timeouts(false) //不使用过期时间,根据业务自己选择
.build();自定义序列化器,这里key-String 序列化器,这里直接复用OCH源码中测试用例的String序列化器;
value-自定义对象序列化器,这里用Protostuff实现,也可以自己选择使用kryo、Hession等实现;
//key-String 序列化器,这里直接复用OCH源码中测试用例的String序列化器
public class OhcStringSerializer implements CacheSerializer<String> {
@Override
public int serializedSize(String value) {
return writeUTFLen(value);
}
@Override
public void serialize(String value, ByteBuffer buf) {
// 得到字符串对象UTF-8编码的字节数组
byte[] bytes = value.getBytes(Charsets.UTF_8);
buf.put((byte) ((bytes.length >>> 8) & 0xFF));
buf.put((byte) ((bytes.length >>> 0) & 0xFF));