
浅析MySQL代价模型:告别盲目使用EXPLAIN,提前预知索引优化策略| 京东零售技术团队
背景
在 MySQL 中,当我们为表创建了一个或多个索引后,通常需要在索引定义完成后,根据具体的数据情况执行 EXPLAIN 命令,才能观察到数据库实际使用哪个索引、是否使用索引。这使得我们在添加新索引之前,无法提前预知数据库是否能使用期望的索引。更为糟糕的是,有时甚至在添加新的索引后,数据库在某些查询中会使用它,而在其他查询中则不会使用,这种情况下,我们无法确定索引是否发挥了预期的作用,让人感到非常苦恼。这种情况基本上意味着 MySQL 并没有为我们选择最优的索引,而我们不得不在茫茫数据中摸索,试图找到问题的症结所在。我们可能会尝试调整索引,甚至删除索引,然后重新添加,希望 MySQL 能从中找到最优的索引选择。然而,这样的过程既耗时又费力,而且往往收效甚微。
如果在添加索引之前,我们能够预知索引的使用情况,那么对于表设计将大有裨益。我们可以在设计表结构时,更加明确地知道应该选择哪些索引,如何优化索引,以提高查询效率。我们不再需要依赖盲目尝试和猜测,而是可以基于实际的数据和查询情况,做出更加明智的决策。因此,对于 MySQL 用户来说,能够预知索引走势的需求非常迫切。我们希望能有一种方法,能够让我们在添加索引之前,就清楚地了解 MySQL 将如何使用索引,以便我们能够更好地优化表结构,提高查询效率。这将极大地减轻我们的工作负担,提高我们的工作效率,让我们能够更加专注于业务逻辑的处理,而不是在索引的海洋中挣扎。
为了解决这个问题,我们可以深入研究 MySQL 的索引选择机制。实际上,这个机制的核心就是代价模型,它通过一个公式来决定索引的选择策略。相对于 MySQL 其他复杂的概念,代价模型实现起来要简单得多。熟悉代价模型之后,我们可以预先了解 MySQL 在执行查询时会如何选择索引,从而更有效地进行索引优化。在接下来的文章中,我将结合近期进行索引优化的具体案例,来详细解释如何运用代价模型来优化索引。
MySQL代价模型浅析
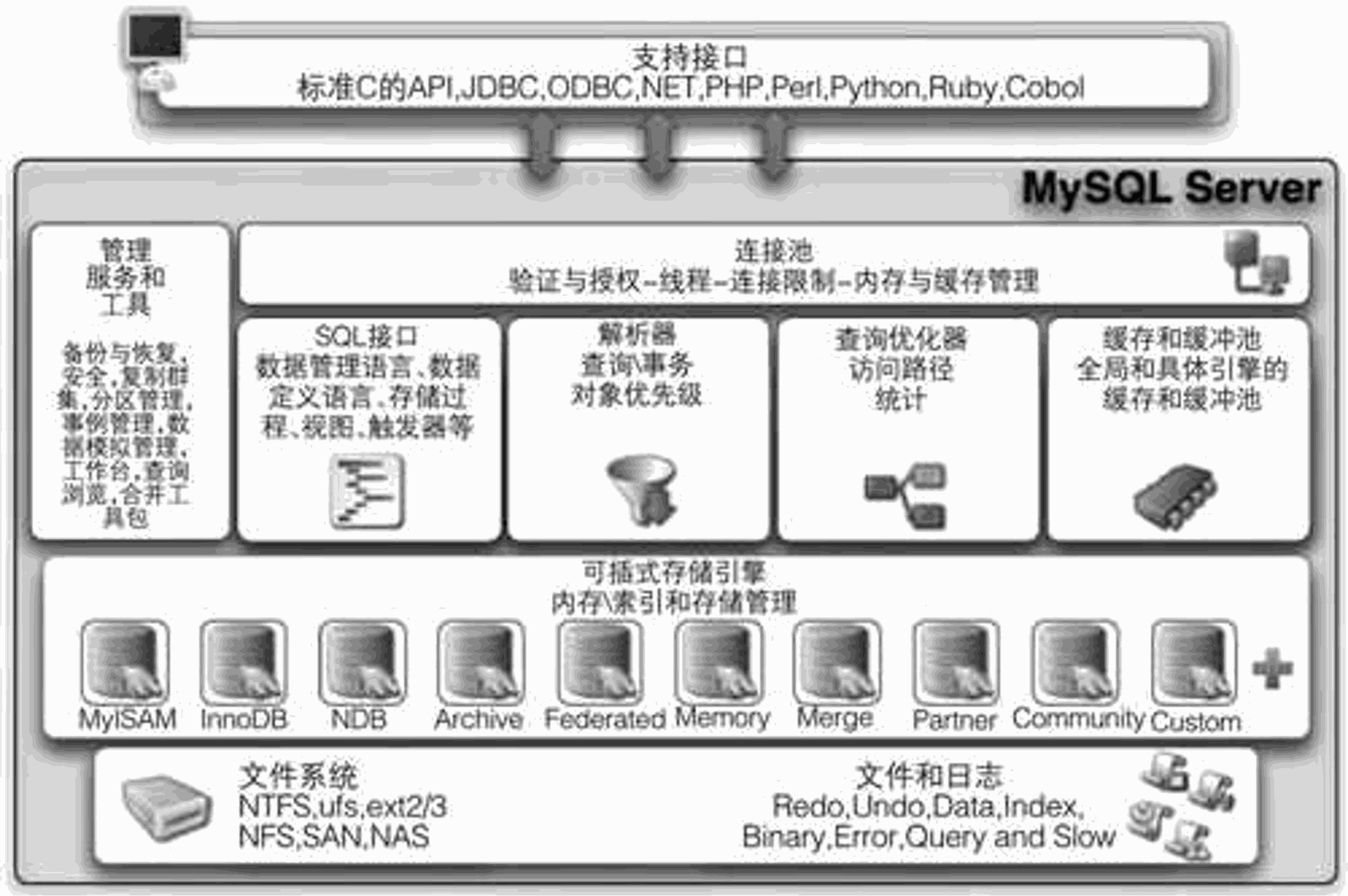
MySQL数据库主要由4层组成:
索引策略选择在SQL优化器进行的
SQL 优化器会分析所有可能的执行计划,选择成本最低的执行,这种优化器称之为:CBO(Cost-based Optimizer,基于成本的优化器)。
Cost = Server Cost + Engine Cost = CPU Cost + IO Cost
其中,CPU Cost 表示计算的开销,比如索引键值的比较、记录值的比较、结果集的排序 ...... 这些操作都在 Server 层完成;
IO Cost 表示引擎层 IO 的开销,MySQL 可以通过区分一张表的数据是否在内存中,分别计算读取内存 IO 开销以及读取磁盘 IO 的开销。
源码简读
MySQL的数据源代码采用了5.7.22版本,后续的代价计算公式将基于此版本进行参考。
opt_costconstants.cc【代价模型——计算所需代价计算系数】
/*
在Server_cost_constants类中定义为静态常量变量的成本常量的值。如果服务器管理员没有在server_cost表中添加新值,则将使用这些默认成本常数值。
5.7版本开始可用从数据库加载常量值,该版本前使用代码中写的常量值
*/
// 计算符合条件的⾏的代价,⾏数越多,此项代价越⼤
const double Server_cost_constants::ROW_EVALUATE_COST= 0.2;
// 键⽐较的代价,例如排序
const double Server_cost_constants::KEY_COMPARE_COST= 0.1;
/*
内存临时表的创建代价
通过基准测试,创建Memory临时表的成本与向表中写入10行的成本一样高。
*/
const double Server_cost_constants::MEMORY_TEMPTABLE_CREATE_COST= 2.0;
// 内存临时表的⾏代价
const double Server_cost_constants::MEMORY_TEMPTABLE_ROW_COST= 0.2;
/*
内部myisam或innodb临时表的创建代价
创建MyISAM表的速度是创建Memory表的20倍。
*/
const double Server_cost_constants::DISK_TEMPTABLE_CREATE_COST= 40.0;
/*
内部myisam或innodb临时表的⾏代价
当行数大于1000时,按顺序生成MyISAM行比生成Memory行慢2倍。然而,没有非常大的表的基准,因此保守地将此系数设置为慢5倍(即成本为1.0)。
*/
const double Server_cost_constants::DISK_TEMPTABLE_ROW_COST= 1.0;
/*
在SE_cost_constants类中定义为静态常量变量的成本常量的值。如果服务器管理员没有在engine_cost表中添加新值,则将使用这些默认成本常数值。
*/
// 从主内存缓冲池读取块的成本
const double SE_cost_constants::MEMORY_BLOCK_READ_COST= 1.0;
// 从IO设备(磁盘)读取块的成本
const double SE_cost_constants::IO_BLOCK_READ_COST= 1.0;
opt_costmodel.cc【代价模型——部分涉及方法】
double Cost_model_table::page_read_cost(double pages) const
{
DBUG_ASSERT(m_initialized);
DBUG_ASSERT(pages >= 0.0);
// 估算聚集索引内存中页面数占其所有页面数的比率
const double in_mem= m_table->file->table_in_memory_estimate();
const double pages_in_mem= pages * in_mem;
const double pages_on_disk= pages - pages_in_mem;
DBUG_ASSERT(pages_on_disk >= 0.0);
const double cost= buffer_block_read_cost(pages_in_mem) +
io_block_read_cost(pages_on_disk);
return cost;
}
double Cost_model_table::page_read_cost_index(uint index, double pages) const
{
DBUG_ASSERT(m_initialized);
DBUG_ASSERT