从0到1:基于SD的AI数字模特探索之路
一、背景介绍
传统的电商平台通常依靠人工拍摄和编辑产品图片,这需要大量的时间和资源。AI数字模特可以根据需要调整模特的外貌、体型和风格。这样,电商平台可以快速、高效地生成大量的产品展示图片,同时可以根据消费者的需求和喜好进行个性化定制。
1.1 初始想法
最初我们主要聚焦到两个具体的业务场景:


1.2 市场初步调研
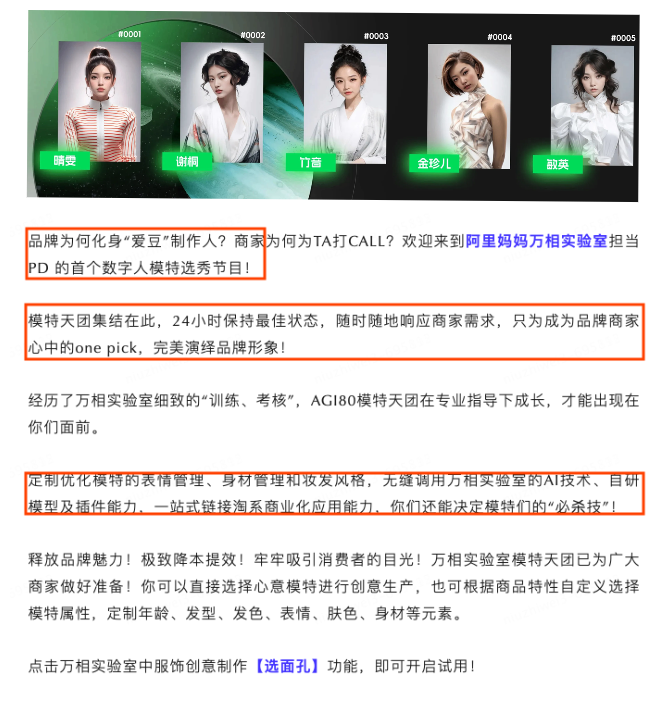
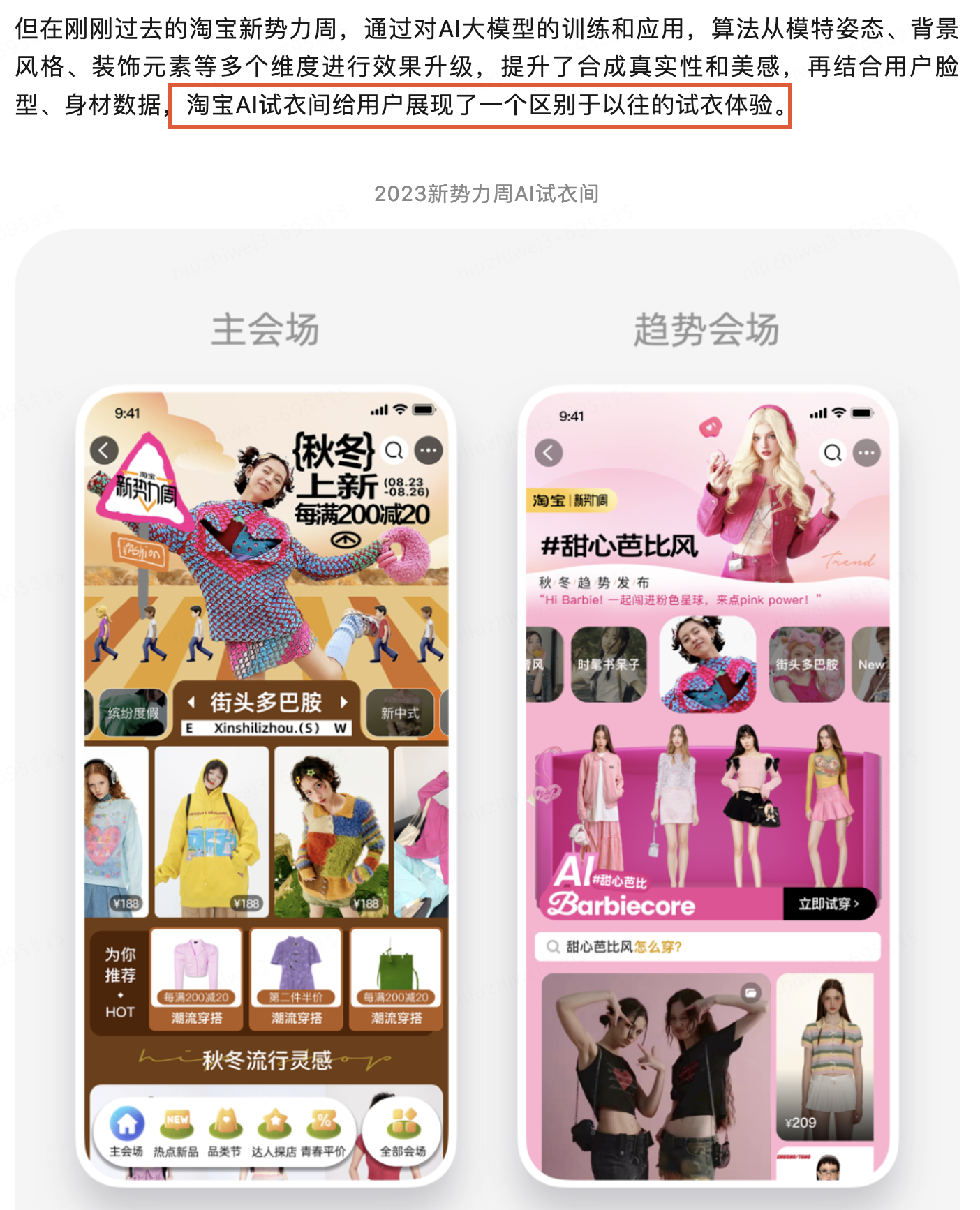
SD、MJ卷起新一轮AI绘画的浪潮之后,有很多创新型公司尤其是电商相关,都开始尝试这个赛道(在SD、MJ之前,已经有数字/虚拟/电商模特相关赛道的公司,但是由于技术限制实现效果不太理想,类比于ChatGPT之前和之后的智能聊天机器人的差别),以下是AI模特相关的一些市场案例,可见其火爆程度:

二、实现过程
2.0 关键路径探索
前期我们主要使用Stable Diffusion Web UI,分别调研了
经过上千次的尝试,主要路径走通后,我们分别通过三方面来落地实现:
2.1 前端设计与实现
2.1.1 原型设计
原型设计通过一个形象的界面展示,可以在项目初期,帮助团队成员更好地理解和验证设计概念,让团队成员之间的目标快速达成一致。
初期我们使用了Webflow进行高保真的原型设计。Webflow可以像写样式一样配置相关的属性比如Flex布局、盒子模型等;可以自定义样式名和组件;同时也可以一键部署到外网。
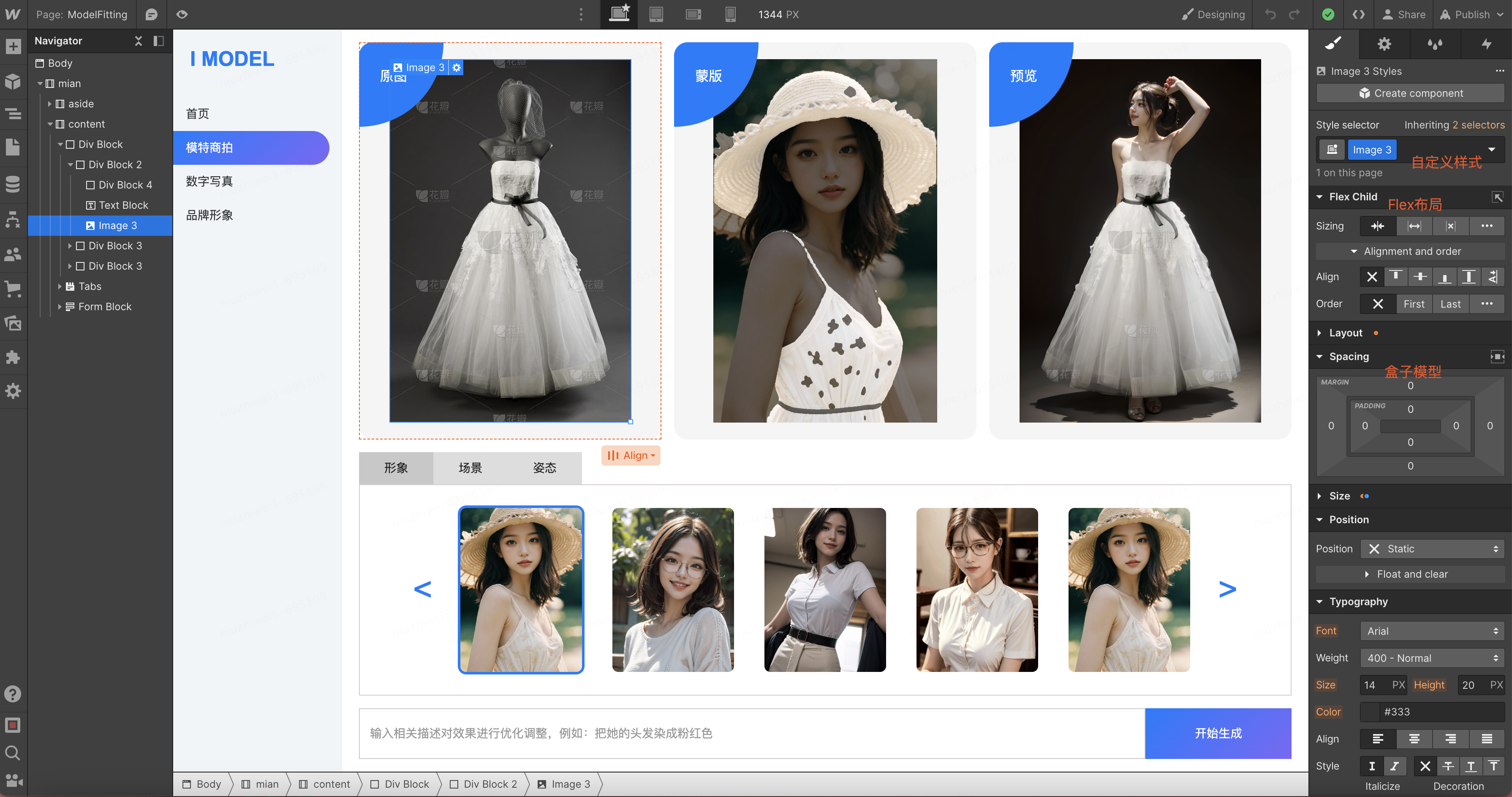
一键部署后自动生成外网可访问的域名:https://imodel.webflow.io/
2.1.2 项目架构思路
前端主要基于Astro岛屿架构,Astro是一个现代化的前端岛屿架构框架,具有很高的灵活性和可扩展性。在Astro中,你可以使用任何被支持的UI框架(比如 React, Svelte, Vue)来在浏览器中呈现群岛。你可以在一个页面中混合或拼接许多不同的框架,或者仅仅使用自己最喜欢的。同时支持SSG(静态站点生成)、SSR(服务端渲染)、CSR(客户端渲染)等不同类型的混合渲染方式;
主要设计思路如下:

此外,我们还引入了UnoCSS,UnoCSS是一个基于CSS的轻量级框架,它旨在简化和加速前端开发过程。UnoCSS使用简单的CSS类来定义样式和布局,无需编写大量的CSS代码。只需将所需的类应用于HTML元素即可实现相应的效果。
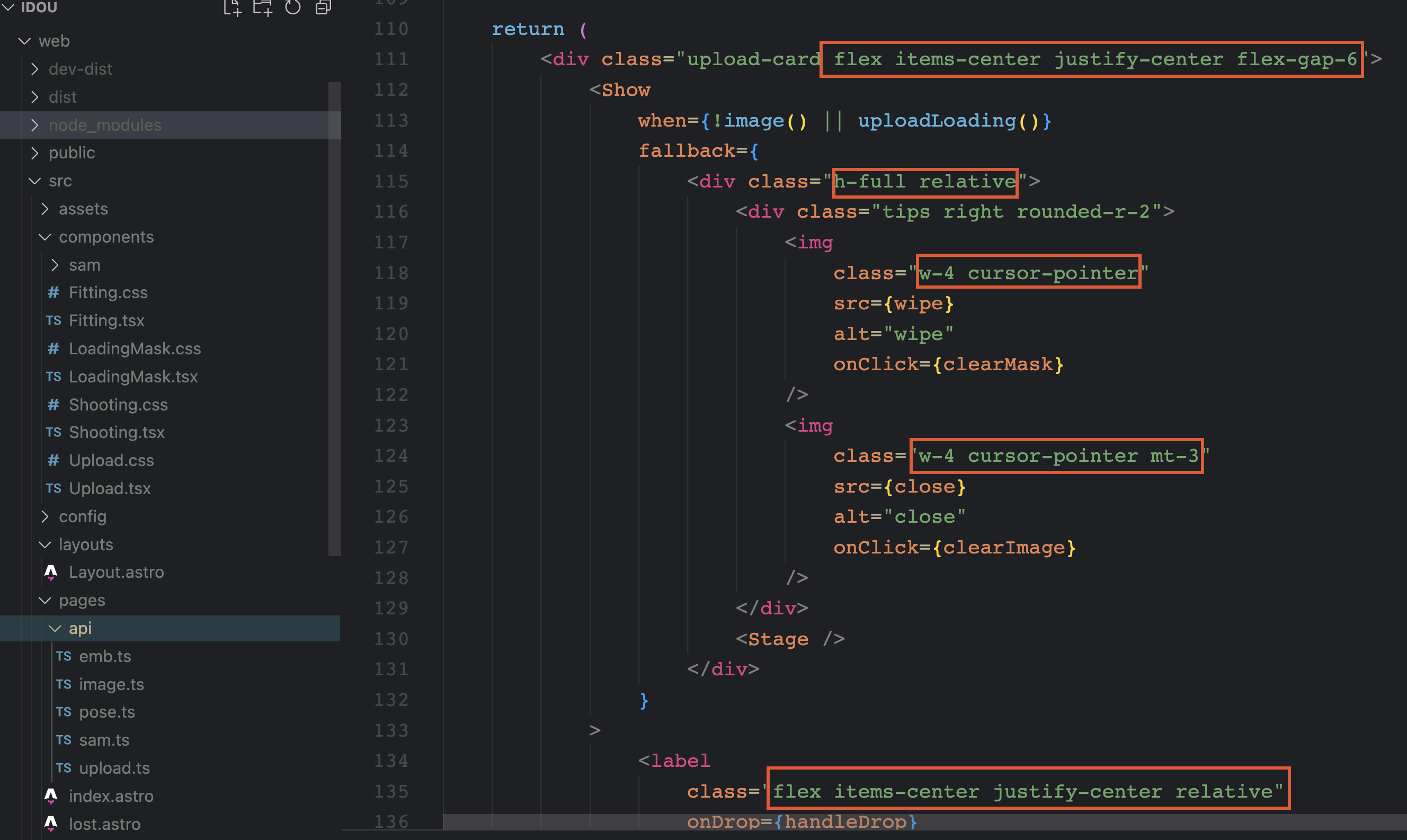
2.1.3 状态共享方案
Astro推荐使用 Nano Stores 共享组件之间的状态,主要原因有:
但是本项目中,只有在SolidJS组件中有状态交互,因此使用了Solid内置的状态方案Solid signals,如果后期涉及到跨框架交互,会引入Nano Stores方案。
2.1.4 服务器端点(API 路由)
我们开启了服务端渲染模式,API端点请求时将在Node或Deno层构建,因此不需要设置proxy代理,也不会产生跨域问题。自定义API端点需要遵守Astro的约定,在page目录下添加.js或.ts文件(与Next类似)
定义upload接口:page/api/upload.ts
import type { APIRoute } from 'astro';
import { BASE_URL } from '~/config';
export const post: APIRoute = async (context) => {
try {
const body = await context.request.json();
const { input_image } = body as {
input_image: string;
};
if (!BASE_URL) {
throw new Error('请设置API_BASE_URL');
}
const res = await fetch(`https://${BASE_URL}/sam/upload`, {
headers: {