黄金眼PAAS化数据服务DIFF测试工具的建设实践
 针对请求场景的多样性和指标服务协议的特殊性,我们实现了面向黄金眼PAAS化数据服务的专用DIFF工具,通过录制线上流量,再回放到测试和线上环境中,对比返回结果,并对请求回放效率和对比结果误报问题做了针对性的优化。这种方式能够保证线上查询场景的全覆盖,减少手动构造请求场景的人工介入,并且提供足够高效的自动化回归测试能力赋能研发自测。下面本文将介绍黄金眼PAAS化数据服务DIFF工具建设中遇到的挑战和实践经验。
针对请求场景的多样性和指标服务协议的特殊性,我们实现了面向黄金眼PAAS化数据服务的专用DIFF工具,通过录制线上流量,再回放到测试和线上环境中,对比返回结果,并对请求回放效率和对比结果误报问题做了针对性的优化。这种方式能够保证线上查询场景的全覆盖,减少手动构造请求场景的人工介入,并且提供足够高效的自动化回归测试能力赋能研发自测。下面本文将介绍黄金眼PAAS化数据服务DIFF工具建设中遇到的挑战和实践经验。
一、背景介绍
黄金眼PAAS化数据服务是一系列实现相同指标服务协议的数据服务,各个服务间按照所生产指标的主题作划分,比如交易实时服务提供实时交易指标的查询,财务离线服务提供离线财务指标的查询。黄金眼PAAS化数据服务支撑了黄金眼APP、黄金眼PC和内部各类大屏的数据查询需求。为了业务能进行正确的数据洞察和决策,需要保证PAAS化数据服务提供数据的准确性。
随着业务需求的快速迭代,数据服务经常需要对查询口径,查询维度,查询指标做调整,因此需要高效的自动化回归测试手段来保证每次需求迭代的质量。PAAS化数据服务的自动化测试面临着一些问题:
-
查询场景多:指标服务协议支持查询的指标和维度数量多,手动测试难以覆盖线上所有请求场景;
-
请求参数复杂:指标服务协议请求参数是复杂嵌套对象,已有的Python DIFF工具难以通过http的方式调用数据服务JSF接口;
-
返回参数对比难:指标服务协议返回参数通过索引来定位字段名称所对应的值,如果字段索引不一致,或者数据集合内元素无序,容易造成对比误报。
针对请求场景的多样性和指标服务协议的特殊性,我们实现了面向黄金眼PAAS化数据服务的专用DIFF工具,通过录制线上流量,再回放到测试和线上环境中,对比返回结果,并对请求回放效率和对比结果误报问题做了针对性的优化。这种方式能够保证线上查询场景的全覆盖,减少手动构造请求场景的人工介入,并且提供足够高效的自动化回归测试能力赋能研发自测。
经过一段时间的建设和迭代,黄金眼PAAS化数据服务DIFF工具已经实现对黄金眼交易实时,交易离线,财务离线三个服务的覆盖,月均DIFF执行次数超过40次。
下面本文将介绍黄金眼PAAS化数据服务DIFF工具建设中遇到的挑战和实践经验。
二、问题和思路
2.1 PAAS化协议调用难点
黄金眼PAAS化服务实现的都是相同的指标服务协议,其请求参数是一个复杂的嵌套对象,并且criterions集合中的每个过滤条件对象使用Jackson的@JsonSubTypes注解实现多态解析。根据JSF团队http调用文档的说明,调用具有复杂嵌套对象接口需要给每个嵌套对象加上"@type": “包路径+类名”,并且推荐使用 JSON.toJSONString (instance, SerializerFeature.WriteClassName) 生成具有类型特征的JSON串,如下图所示,而生成前又必须使用Jackson将请求参数反序列化成实例对象。如果执着在python脚本中使用http方式调用此类JSF接口,需要自己识别每个过滤条件的实现类。为了实现PAAS化数据服务JSF接口的便捷调用,使用java编写的DIFF工具因此诞生。

2.2 主要挑战
Java编写的DIFF工具可以解决PAAS化数据服务接口调用的问题,但在现有DIFF脚本的实际使用中,面临着以下两个挑战:
2.2.1 请求回放效率问题
单线程回放
对所录制的请求进行接口调用和结果对比,是单线程去遍历请求List来实现,单个请求在对线上和测试两个环境的接口调用成功后,再进行返回结果的对比,只有对比结束后才去回放下一个请求。但实际上,上一个请求和下一个请求的回放之间,并不需要有调用时序。这种使用单线程进行请求回放的方式,会极大降低执行效率,导致diff执行时间过长。
同步调用接口
除此之外,对于线上和测试两个环境接口的调用,采取的是同步的方式,一个环境的接口返回结果后,才去调用下一个接口。同理,两个环境的接口调用之间,没有依赖关系,一个环境接口的返回值不会影响下一个接口的调用,只需要保证两个环境接口调用都有返回值后,再进行结果对比即可。
2.2.2 对比结果误报问题
索引不一致
PAAS化协议的返回参数结构如下所示,可以看到body.data数据集合具有最多的信息要素,是主要的对比目标,meteData.metaIndex数据索引定义了数据集合子元素中每个值代表的具体字段名称,比如[1234,12345.41,"11068"]中的三个值分别代表成交父单量、成交金额和主品牌id。如果两个环境接口的返回值字段名称索引不统一,但根据索引实际取到的字段名称所对应的值相同,这种情况下直接遍历数据集合子集合去对比,会得到对比有差异的结论,但实际上两个返回值是一致的,这就导致对比结果误报问题,如下图所示。
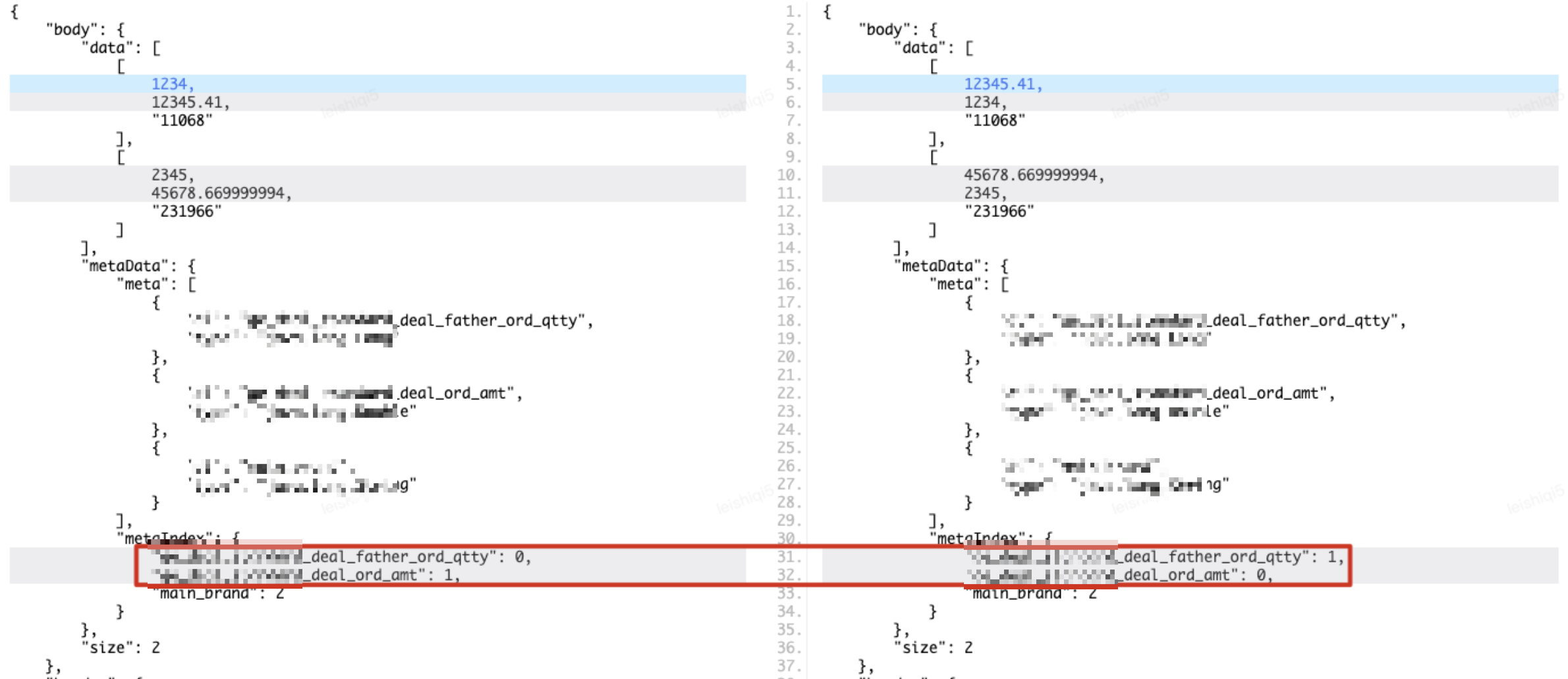
无序数组
除了字段名称索引不一致会导致对比误报以外,数据集合data的每个子集合间,可能是无序的。示例的返回参数data中,第一个子集合包含主品牌“11068”的两个指标,第二个子集合包含主品牌“231966”的两个指标,如果另一个环境接口的返回参数data中,第一个子集合主品牌为“231966”,第二个子集合主品牌为“11068”,这种情况直接遍历对比的话,会导致对比结果有差异,但实际上也是对比误报。

2.3. 解决思路
2.3.1 遍历请求时并发与流量回放时异步,解决请求回放效率问题
从主要挑战中的分析可知,一次DIFF执行的耗时=需要回放的请求数*(两个环境的接口调用耗时+对比耗时)。从耗时拆分公式可以看出,优化DIFF执行的效率,可以从请求并行回放和接口异步调用两个方向来实现。
-
请求并行回放:在遍历请求时,向线程池提交单个请求的回放和对比任务,所有请求的回放和对比任务完成后,汇总对比结果数据,生成DIFF报告;
-
接口异步调用:使用CompletableFuture异步调用两个环境的接口,得到cf1和cf2,再使用cf1.thenCombine(cf2)方法对两个异步任务的执行结果做组合处理,两个异步任务都执行完成后,才进行下一步处理。
2.3.2 字段索引统一与次级排序实现,解决对比结果误报问题
针对PAAS化协议返回参数这种结构,要想实现对比结果的零误报,需要保证两个环境返回值字段索引的统一,和数据集合内子集合间的有序,才能在返回值结果对比时,不会出现对比异常的情况。
字段索引统一的实现比较简单,以一个环境接口返回值的字段索引metaIndex为基准,重新对另一个环境接口返回值中数据子集合内的每个值排放位置,保证遍历数据子集合内每个值时,所对应的字段名称一致。
次级排序是为了解决数据子集合间的顺序问题,之所以突出“次级”这一重点,是因为子集合所包含的值可能有多个,如果仅针对一个值排序,无法完全保证子集合间的有序性,因此需要实现次级排序器,选取子集合中的多个值作为排序的依据,使得子集合间的顺序稳定,进而保证对比结果的可靠。
三、整体架构

四、核心设计点
4.1 请求回放效率优化
4.1.1 请求回放前去重
在建设数据服务DIFF工具前,就有一个目标是“让每一次请求回放都有意义”。对于只读的数据查询服务,每天都会有大量重复的请求,如果不对请求做去重处理,那么会有很大一部分回放的请求都是重复的,这种请求去做回放和DIFF,不仅浪费资源,干扰最终对比结果汇总,还没有任何意义。因此请求回放前的去重处理很有必要。
最初DIFF工具所采取的请求参数去重方式是HashSet的方式,在调用接口回放流量前,将请求去重保存至一个HashSet中,去重结束后再遍历HashSet进行流量回放和DIFF执行。这种方式虽然可以有效的去重,但在实际使用过程,如果需要diff的请求数量过多或请求参数过大(比如查询指定2000个sku的财务指标),那么HashSet去重效率比较低,遍历去重5万条大请求耗时超过10分钟,并且占用内存也较多,如果执行DIFF的流水线容器内存较小,那么DIFF执行会直接失败。
为了改进请求的去重效率,使用了布隆过滤器的方式实现去重,所占用的内存会比HashSet的方式要小,判断是否重复的效率也比较高,适合大量数据的去重操作。
for (int i = 0; i < maxLogSize; i++) {
String reqParam = fileAccess.readLine();
if (bloomFilter.mightContain(reqParam)){
//请求重复,跳过此请求
countDownLatch.countDown();
continue;
}else {
bloomFilter.put(reqParam);
}
//请求不重复,执行接口调用和DIFF
}
4.1.2 遍历请求时并发
遍历请求时,使用execute()方法向线程池提交请求回放和DIFF执行任务,每个请求都会生成一个独立的任务,任务和任务之间并行执行,提高整个DIFF过程的执行效率。由于DIFF需要在每个请求回放和结果对比结束后,再执行对比差异的汇总和展示,因此需要主线程阻塞,等待所有回放对比任务子线程结束后,再启动主线程做差异结果汇总分析。
为了满足主子线程间的调用时序要求,使用CountDownLatch计数器,初始化时设置最大请求数量n,每当一个子线程结束,计数器减一,当计数器变为0,一直在await的主线程唤醒,汇总差异结果。
这里又涉及到线程池拒绝策略的问题,如果使用线程池默认的AbortPolicy策略,但不捕获异常和在异常处理中使计数器减一,那么当线程池无法接受新任务时,CountDownLatch计数器永远不会为0,主线程一直处于阻塞中,此次DIFF过程永远不会结束。为了使DIFF在异常情况下都能顺利执行并输出对比结果,并保证每一条请求都能进行回放和对比,这里采用CallerRunsPolicy,将被拒绝的任务返回给调用者自己执行。
//初始化计数器
CountDownLatch countDownLatch = new CountDownLatch(maxLogSize);
log.info("开始读取日志");
for (int i = 0; i < maxLogSize; i++) {
String reqParam = asciiFileAccess.readLine();
if (bloomFilter.mightContain(reqParam)){
//有重复请求,跳出本次循环,计数器减一
countDownLatch.countDown();
continue;
}else {
bloomFilter.put(reqParam);
}
//向线程池提交回放和对比任务
threadPoolTaskExecutor.execute(() -> {
try {
//执行接口调用和返回结果对比
}
} catch (Exception e) {
} finally {
//子线程一次执行完成,计数器减一
countDownLatch.countDown();
}
});
}
//阻塞主线程
countDownLatch.await();
//等待计数器为0后,开始汇总对比结果
4.1.3 请求回放时异步
JSF提供了接口异步调用的方式,返回CompletableFuture
//测试环境接口异步请求
CompletableFuture<UResData> futureTest = RpcContext.getContext().asyncCall(
() -> geTradeDataServiceTest.fetchBizData(param)
);
//线上环境接口异步请求
CompletableFuture<UResData> future = RpcContext.getContext().asyncCall(
() -> geTradeDataServiceOnline.fetchBizData(param)
);
//使用thenCombine对futureTest和future执行结果合并处理
CompletableFuture<ResCompareData> resultFuture = futureTest.thenCombine(future, (res1, res2) -> {
//执行对比,返回对比结果
return resCompareData;
});
//获取对比结果的值
return resultFuture.join();
4.2 误报率优化
4.2.1 字段索引统一
字段索引统一的核心,就是找到两个返回值间相同字段名称索引的映射关系,比如返回值A中字段名称a的索引index1对应返回值B中字段名称a的索引index2。当把所有映射关系找到之后,再对返回值B数组中字段顺序重新排放。
List<List<Object>> tmp = new ArrayList<>();
int elementNum = metaIndex1.size();
HashMap<Integer, Integer> indexToIndex = new HashMap<>(elementNum);
//获取索引映射关系
for (int i = 0; i < elementNum; i++) {
String indicator = getIndicatorFromIndex(i, metaIndex2);
Integer index = metaIndex1.get(indicator);
indexToIndex.put(i, index);
}
//根据映射关系重新排放字段,生成新的数据集合
for (List<Object> dataElement : data2) {
List<Object> tmpList = new ArrayList<>();
Object[] objects = new Object[elementNum];
for (int i = 0; i < dataElement.size(); i++) {
objects[indexToIndex.get(i)] = dataElement.get(i);
}
Collections.addAll(tmpList, objects);
tmp.add(tmpList);
}
4.2.2 数据集合次级排序
数据集合data中包含多个子集合,每个子集合是属性值和指标的组合。为了实现子集合之间的有序,就需要找到所有属性字段的索引,实现一个使用所有属性字段值作为排序标准的次级排序器。
一般而言,属性字段的数据类型是String类型,但也存在特殊情况,比如使用sku_id作为属性值,那么sku_id返回的数据类型就是Long类型。为了实现次级排序器的通用和可靠,首先使用所有的String类型字段排序,再使用Long类型字段排序,如果不存在String类型字段,那么对所有Long类型字段排序。
List<Integer> strIndexList = new ArrayList<>();
List<Integer> longIndexList = new ArrayList<>();
// 保存所有String和Long类型字段的索引
for (int i = 0; i < size; i++) {
if (data.get(0).get(i) instanceof String) {
strIndexList.add(i);
}
if (data.get(0).get(i) instanceof Long || data.get(0).get(i) instanceof Integer) {
longIndexList.add(i);
}
}
//首选依据String类型字段排序
if (!strIndexList.isEmpty()) {
//初始化排序器
Comparator<List<Object>> comparing = Comparator.comparing(o -> ((String) o.get(strIndexList.get(0))));
for (int i = 1; i < strIndexList.size(); i++) {
int finalI = i;
//遍历剩余String字段,实现任意长度次级排序器
comparing = comparing.thenComparing(n -> ((String) n.get(strIndexList.get(finalI))));
}
for (int i = 0; i < longIndexList.size(); i++) {
int finalI = i;
comparing = comparing.thenComparingLong(n -> Long.parseLong(n.get(longIndexList.get(finalI)).toString()));
}
sortedList = data.stream().sorted(comparing).collect(Collectors.toList());
}
4.3 PAAS化数据服务DIFF效果
经过对请求回放效率和误报率的优化,数据服务一次DIFF执行的耗时和对比结果都能满足现有研发自测和上线前回归的需求。下图展示了黄金眼交易实时服务的一次DIFF报告,在四个工作线程的配置下,四万条请求去重后,请求回放耗时570秒,对比结果中也能清晰地展示数据差异。为了方便对数据差异的排查,在展示差异对比结果时,将字段名称拼接在数值前,避免人工根据索引去查找差异值对应的字段名称。

五、落地应用
5.1 数据服务提测准入流水线
流水线提供了下载代码原子、编译原子和Shell自定义脚本原子,这三种原子就能触发DIFF任务的执行。借助于流水线的这种能力,目前已经将DIFF工具的能力引入到黄金眼黄金眼交易实时和交易离线数据服务的提测准入流水线中。提测准入流水线具备了提测分支代码的编译和JDOS部署,流量的回放和执行结果对比,以及DIFF过程中的接口测试覆盖率统计。通过线上流量回放进行DIFF测试,交易离线服务和实时服务代码的行覆盖率分别达到51%和65%。

交易离线服务提测准入流水线
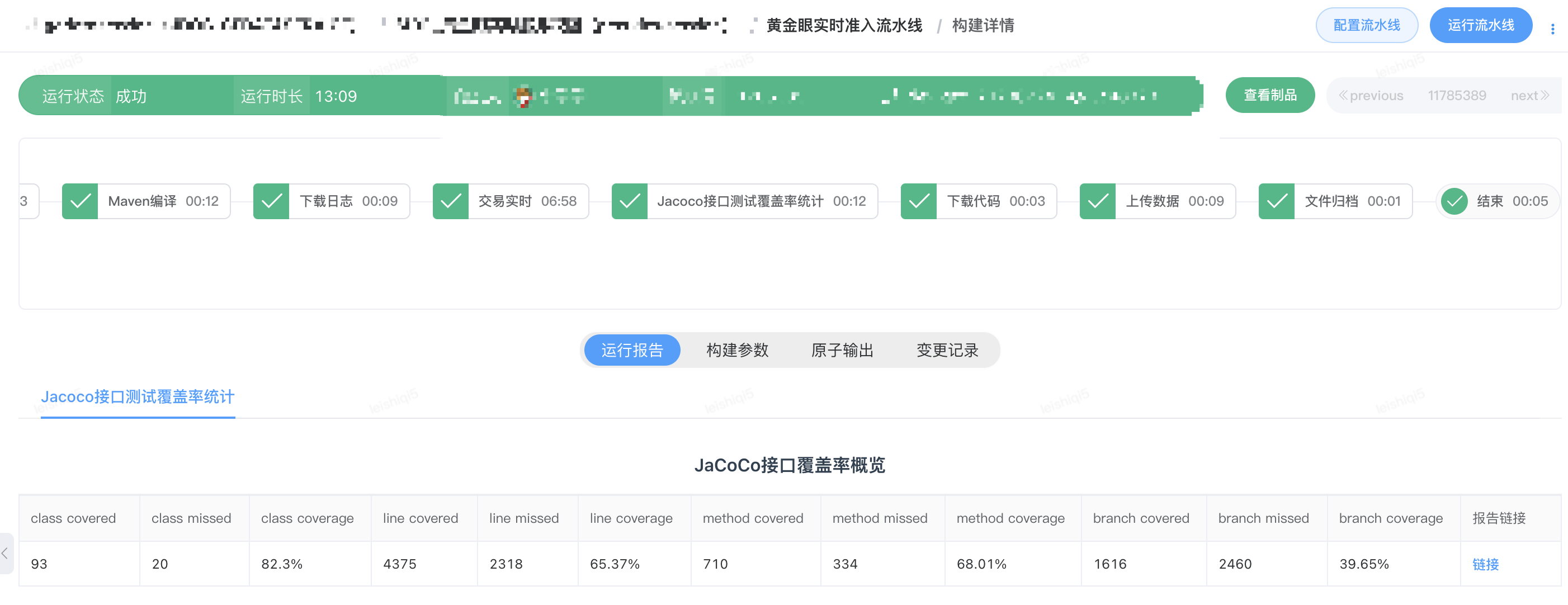
交易实时服务提测准入流水线
5.2 服务研发自测提效
DIFF工具除了能在提测准入流水线中发挥作用,我们还设置了可以手动触发DIFF的流水线,赋能研发自测提效。目前DIFF流水线已在黄金眼PAAS化多个数据服务落地应用,包括交易离线服务,交易实时服务和财务离线服务,下图展示了这三个数据服务DIFF流水线每月的执行次数,9月份已累计执行66次DIFF。

*数据来源:流水线执行趋势统计
目前DIFF工具已经具备自定义差异率阈值、筛选和排除关键字、自定义指标服务PAAS化请求的过滤条件和请求指标等能力。这种针对于指标服务PAAS化请求的自定义能力,在日常需求迭代和技术改造中,都发挥出一定的作用。
比如黄金眼交易实时服务查询引擎从Elasticsearch切换到Doris,这一改造涉及到大量的DIFF回归测试工作。在这一过程中,研发发现由于Elasticsearch和Doris对于去重指标(比如子单量)的计算方式有一些差异,导致使用两种引擎查询出来的去重指标,差异率会高于其他非去重指标(比如金额),这样会干扰最终对比结果的展现,不利于发现真正有差异的请求。为了解决这一问题,我们提供了自定义指标服务PAAS化请求指标的能力,可以设置回放的请求只查询非去重指标,避免去重指标的干扰,推动了回归测试工作的进行。
六、总结
本文介绍了黄金眼数据质量团队在数据服务DIFF工具建设过程中面临的DIFF效率和对比结果可靠性两大问题,并分别针对上述两类问题和对应的挑战,阐述了解决方案和落地的实践经验。
6.1 定制化DIFF工具优势
与京东内部专业的录制回放平台R2相比,我们的DIFF工具在流量录制、链路追踪、通用性等等能力上都是远远不足或者缺失的。但如果从PAAS化数据服务DIFF定制化的角度来看,我们的DIFF工具在请求自定义和对比过程中的所做的优化,又是这种通用化平台暂时无法支持的。
6.2 未来展望
目前通过DIFF工具做自动化回归测试,黄金眼交易离线服务和实时服务的接口测试代码行覆盖率在50%左右,说明日常线上查询场景不能覆盖所有的代码分支。为了提高DIFF测试的代码行覆盖率,后续考虑分析覆盖率报告,找出线上查询未覆盖的场景,形成固定的请求用例集,在DIFF测试时,既回放线上流量,又回放固定请求用例集,使DIFF测试的行覆盖率达到提升。
作者:京东零售 雷诗棋
来源:京东云开发者社区 转载请注明来源

 浙公网安备 33010602011771号
浙公网安备 33010602011771号