
探析ElasticSearch Kibana在测试工作中的实践应用
 离线数据测试中最重要的就是数据验证,一部分需要测试es存储数据的正确性,另一部分就需要验证接口从es取值逻辑的正确性。而为了验证es取值逻辑的正确性,就需要用到Kibana, 它能帮助测试同学更加快速高效的执行es数据的查询,大大提高测试效率。
离线数据测试中最重要的就是数据验证,一部分需要测试es存储数据的正确性,另一部分就需要验证接口从es取值逻辑的正确性。而为了验证es取值逻辑的正确性,就需要用到Kibana, 它能帮助测试同学更加快速高效的执行es数据的查询,大大提高测试效率。
一. 为什么使用ES Kibana
离线数据测试中最重要的就是数据验证,一部分需要测试es存储数据的正确性,另一部分就需要验证接口从es取值逻辑的正确性。而为了验证es取值逻辑的正确性,就需要用到Kibana, 它能帮助测试同学更加快速高效的执行es数据的查询,大大提高测试效率。
二. 什么是ES和Kibana
我们平常所说的ELK指的就是Elasticsearch、Logstash和Kibana,这三个技术的组合是大数据领域中一个很巧妙的设计,是一种很典型的MVC思想,模型持久层,视图层和控制层。
Logstash担任控制层的角色,负责搜集和过滤数据。
Elasticsearch担任数据持久层的角色,负责储存数据,是一个实时的分布式存储、搜索、分析的引擎,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据,相较于Mysql来说更善于百万数据量的检索。
而我们这次讲的Kibana担任视图层角色,它是一个为Logstash和ElasticSearch提供的日志分析的Web接口。可使用它对日志进行高效的搜索、可视化、分析等各种操作,是一个开源的数据分析与可视化平台,与Elasticsearch搜索引擎一起使用。您可以用Kibana搜索、查看、交互存放在Elasticsearch索引中的数据,也可以使用Kibana以图表、表格、地图等方式展示数据,从而达到高级的数据分析与可视化的目的。
本次将介绍Kibana中的Dev Tools中sql查询 , Visualize(可视化数据) 两个功能的使用。
三. Dev Tools 中的sql查询
ES和MYSQL的区别:
| Mysql | ElasticSearch |
|---|---|
| Database | index |
| Table | Type |
| Row | Document |
| Column | Field |
| Schema | Mapping |
| Index | Everything is indexed |
| SQL | Query DSL |
| SELECT * FROM ... | GET http://... |
| UPDATE table SET... | PUT http://... |
在数据库中的增insert、删delete、改update、查select操作等价于ES中的增PUT/POST、删Delete、改_update、查GET。对于这些复杂的查询,es使用Query DSL都可以实现。
POST /index111/_search
{
"query": {
"bool":
{
"must":
[
{"term":{"user": "张三"}},
{"term":{"timeStamp": "2022-08-04 00:00:00"}}
]
}
}
}
但是相比较来说,我们更加熟悉sql语句,所以es也提供了sql语句的开发,让我们通过sql语句即可实现ES的查询。在es版本6.3之前都不支持sql语句的开发,如果需要使用sql语句来开发es的数据查询,那么我们需要手动的自己安装插件。
但是在6.3版本之后,es自带就安装了sql的插件,集成在_xpack下面,我们可以直接通过sql语句的方式实现es当中的数据查询
以下为使用sql语句查询的步骤:
- 进入Dev Tools - Console(控制台)
POST /_xpack/sql
{
"query": "select * from index111 "
}
- 输入以上语句,默认返回格式为json

2.可以自定义返回的格式,如想返回文本格式, /_xpack/sql 后加上?format=txt
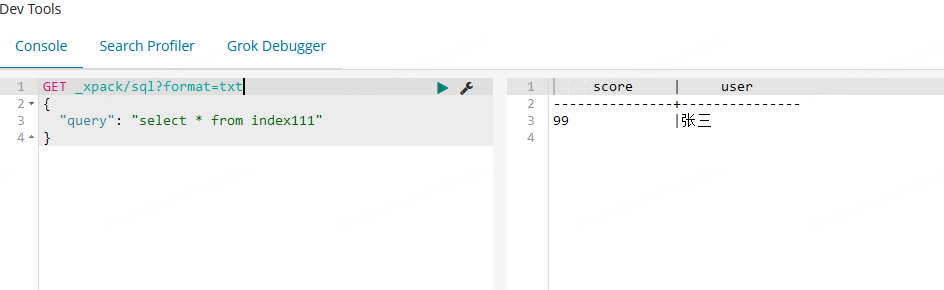
较为复杂的分类聚合计算的sql语句,也是支持的。
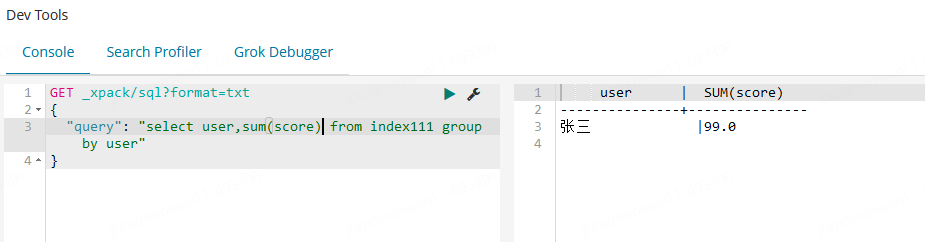
使用该功能,能够帮助测试同学较为方便快捷的查询es的数据,提高测试效率。
四. Visualize(可视化数据) 使用
使用上面的sql语句,能够较快的查询到数据,但该sql语句无法保存,等下次验证回归该内容,查询同样数据时,还需再次输入sql语句,就可能出现需要重新了解查询逻辑,延长回归时间的问题。而使用Visualize(可视化数据)可以将es索引内容经过聚合,通过图表等多种方式保存并显示出来,能够更加直接浏览es的数据,同时产品业务也可用于进行数据分析,创建数据看板。
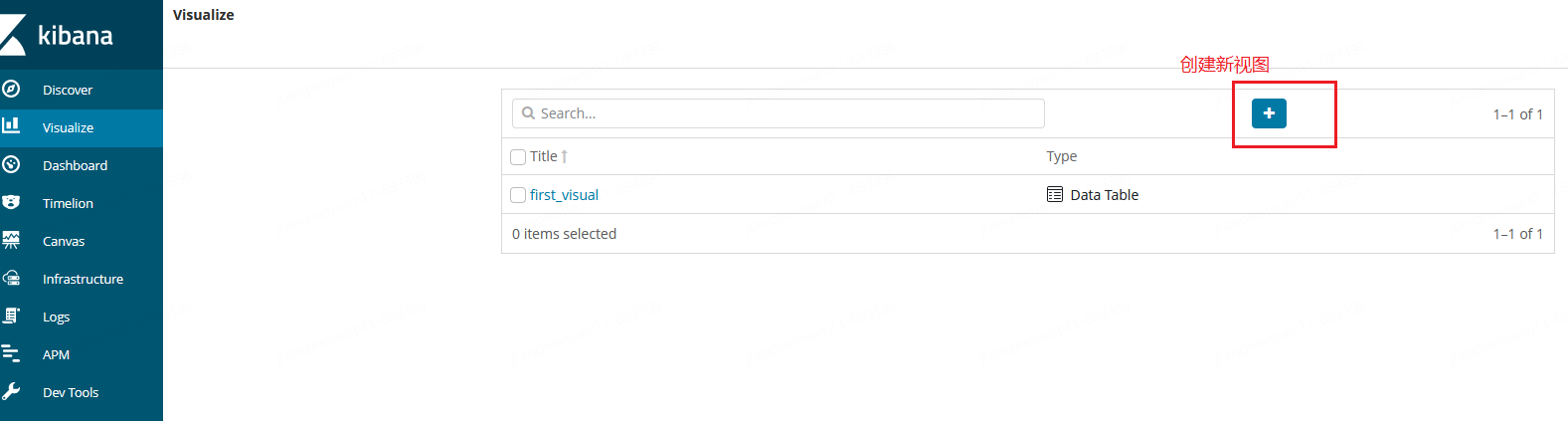
以下为针对单个es索引创建可视化图表的操作步骤:
- 进入Visualize-点击创建新视图
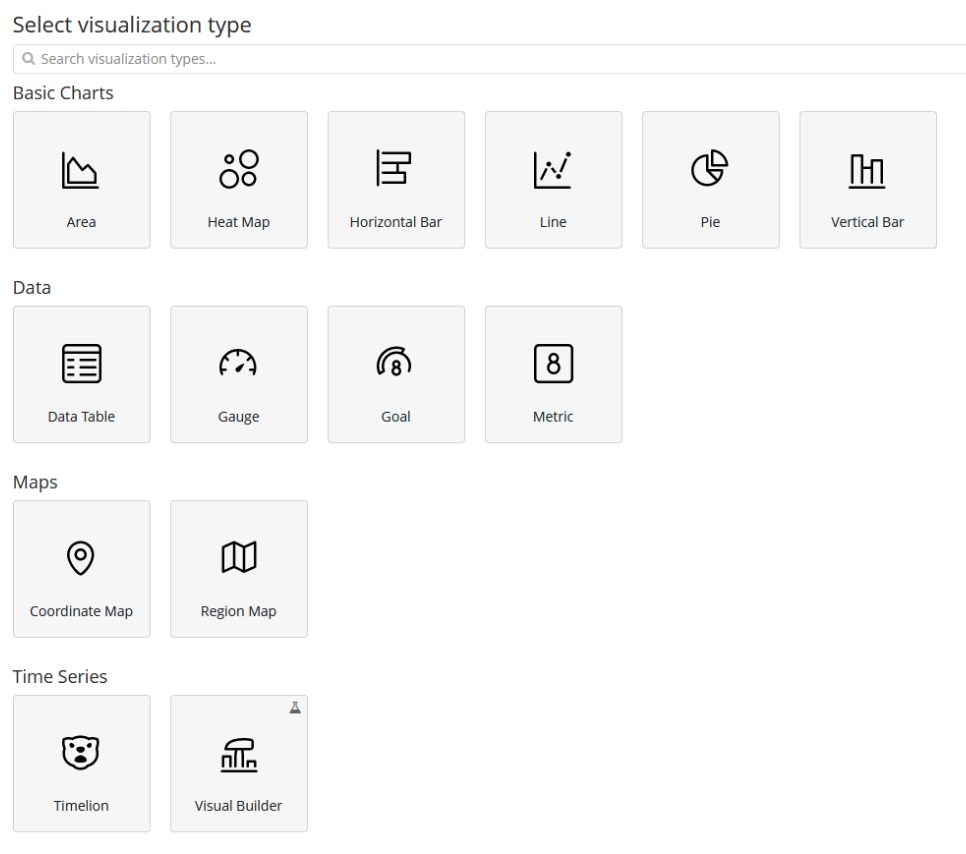
2. 选择想要以哪种图表样式显示数据
3. 选择应用的es索引
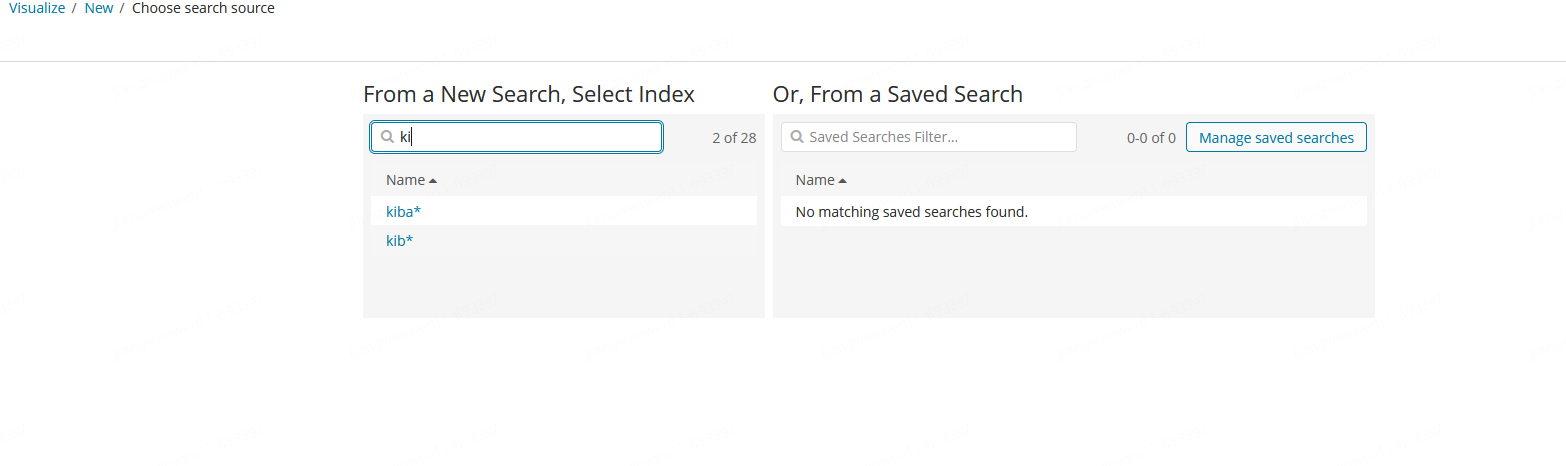
注意,首先需要对目标索引建立索引模式,否则在创建可视化图时会无法选择到该索引。路径:Management - Create index pattern。
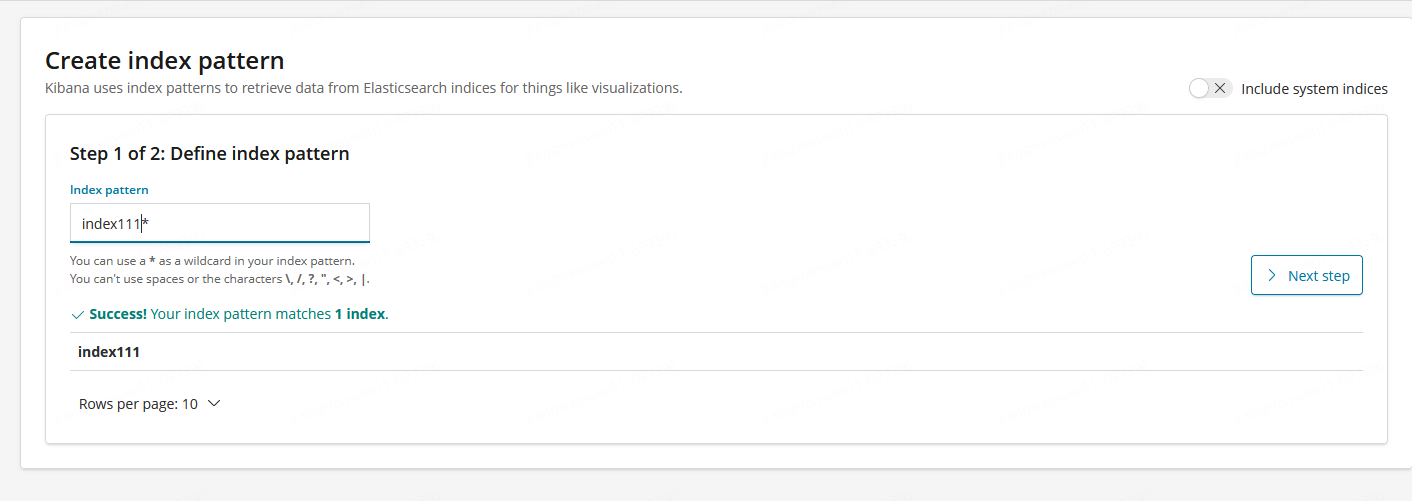
4. 进入图表设置界面,设置想要的数据:Metrics和Buckets, Metrics可以设置聚合
您可以使用 Elasticsearch 桶聚合 指定图表中显示哪些信息。桶聚合简单的把符合您搜索条件的文档分成不同类别,又叫做 buckets 即x轴。例如:数据的分类分析数据,通过使用桶聚合,您可以建立多个分类并看到每个分类下的数据汇总情况。
Metric有多种聚合方式:Count, Sum, Top Hit, Unique Count,可按需选择。
Buckets 可设置你的数据集中将要根据什么信息进行检索。
如想看各个人的总得分,Metric可增加一个分数,度量单位是SUM,Buckets增加人名,如果我们还想看各个人下其他维度的分数,可以再添加一个子分桶,在左侧下方点击 add sub buckets

5. 设置完成后,注意右上角需要选择应用的时间范围,默认为过去15分钟,可能就会出现无数据的情况,保存后,下次就无需使用sql查询,可以直接查看该表对应指标的数据了。
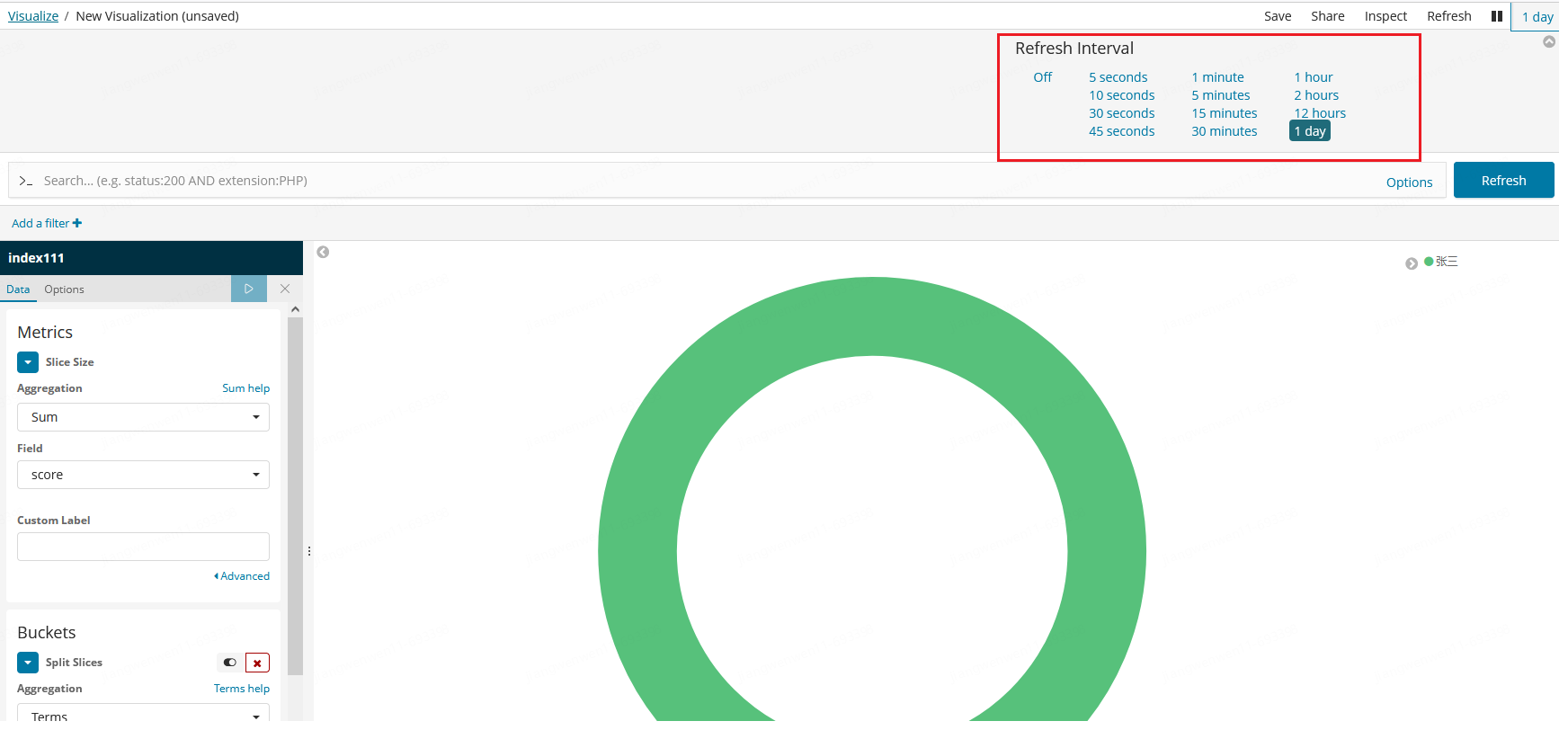
图表显示时,部分字段需要映射其他字段显示,或涉及到统计数据需要对表其中几个字段计算聚合处理,比如对其中两个字段求和,这时就可以使用到Management/Index Patterns/Script fields 脚本字段来加工原字段,将原字段映射为其他数据和增加一列计算求和的脚本字段,增加图表的易读性。例如:将姓名字段转换成其他人名映射。但如果使用script field, 需保证你的脚本的正确性,可执行性,避免因脚本问题出现的查询错误阻塞的情况。
Script field 可使用painless 语言,具有和groovy那样的语法,和 Java类似。以下为举例的字段映射脚本
def path = doc['user'].value;
String newUser;
if (path != null) {
path =path.toString();
if (path =='张三'){
newUser = '张同学';
}
if (path=='李四'){
newUser = '李同学';
}
}
return org
可以看到,Visualize桶聚合使用脚本加工字段,用户字段等就能直接映射出其他文本,方便直观。
五. 总结
以上为ES Kibana的 devtools sql查询和 Visualize 的相关介绍和使用操作步骤,Kibana还有其他的很多强大的功能,巧妙使用这些工具,能够帮助测试同学提高测试效率,帮助产品业务同学进行更高级的数据分析,希望本篇文章能够帮助大家更加了解和使用Kibana。
作者:京东物流 江雯雯
来源:京东云开发者社区 自猿其说 Tech 转载请注明来源

 浙公网安备 33010602011771号
浙公网安备 33010602011771号