数据测试实践:从一个bug开始的大数据引擎兼容性探索
 数据测试不仅关注数据加工的代码逻辑,还要考虑大数据执行引擎带来的影响,因为各种引擎框架将对同一份数据产生不同的计算或检索结果。本文将从一个年度账单bug引入,讲解在数据测试实践中对大数据执行引擎兼容性
数据测试不仅关注数据加工的代码逻辑,还要考虑大数据执行引擎带来的影响,因为各种引擎框架将对同一份数据产生不同的计算或检索结果。本文将从一个年度账单bug引入,讲解在数据测试实践中对大数据执行引擎兼容性
作者:京东零售 李晓洁
我们常常忘记,天才也取决于其所能掌握的数据,即使阿基米德也无法设计出爱迪生的发明。——Ernest Dimnet
在大数据时代,精准而有效的数据对于每个致力于长期发展的组织来说都是重要资产之一,而数据测试更是不可或缺的一部分。数据测试不仅关注数据加工的代码逻辑,还要考虑大数据执行引擎带来的影响,因为各种引擎框架将对同一份数据产生不同的计算或检索结果。本文将从一个年度账单bug引入,讲解在数据测试实践中对大数据执行引擎兼容性差异的探索。
一、需求内容
京东-我的京东-年度账单是一年一次,以用户视角对在平台一年的消费情况进行总结。账单从购物,权益,服务等方面切入,帮助用户挖掘在自我难以认知的数据角度,通过这种方式让用户从账单中发掘打动内心的立意,并主动进行分享和传播。本次,我京年度账单以“2022购物印象”为主题,通过不同的数据维度组成村落故事线,用户以虚拟人物形象贯穿始终,用户浏览完故事线后,可生成购物印象。
年度账单其中一个报表为用户年度购买的小家电品类。该报表使用年度账单汇总表中的小家电品类集合字段,计算了2022年度某用户全年最后购买的两款小家电所在的品类。本文bug分享将围绕这个字段展开。
二、 缺陷描述
缺陷描述:在APP层用户年度账单汇总模型app_my_jd_user_bill_year_sum中,对于小家电品类集合字段,APP表结果与手动计算结果不一致。
以用户'Mercury'、'乐乐1024'、'活力少年'的购买数据为例,上游ADM层以array<string>类型存储用户每月购买的小家电相关品类,如下图所示:
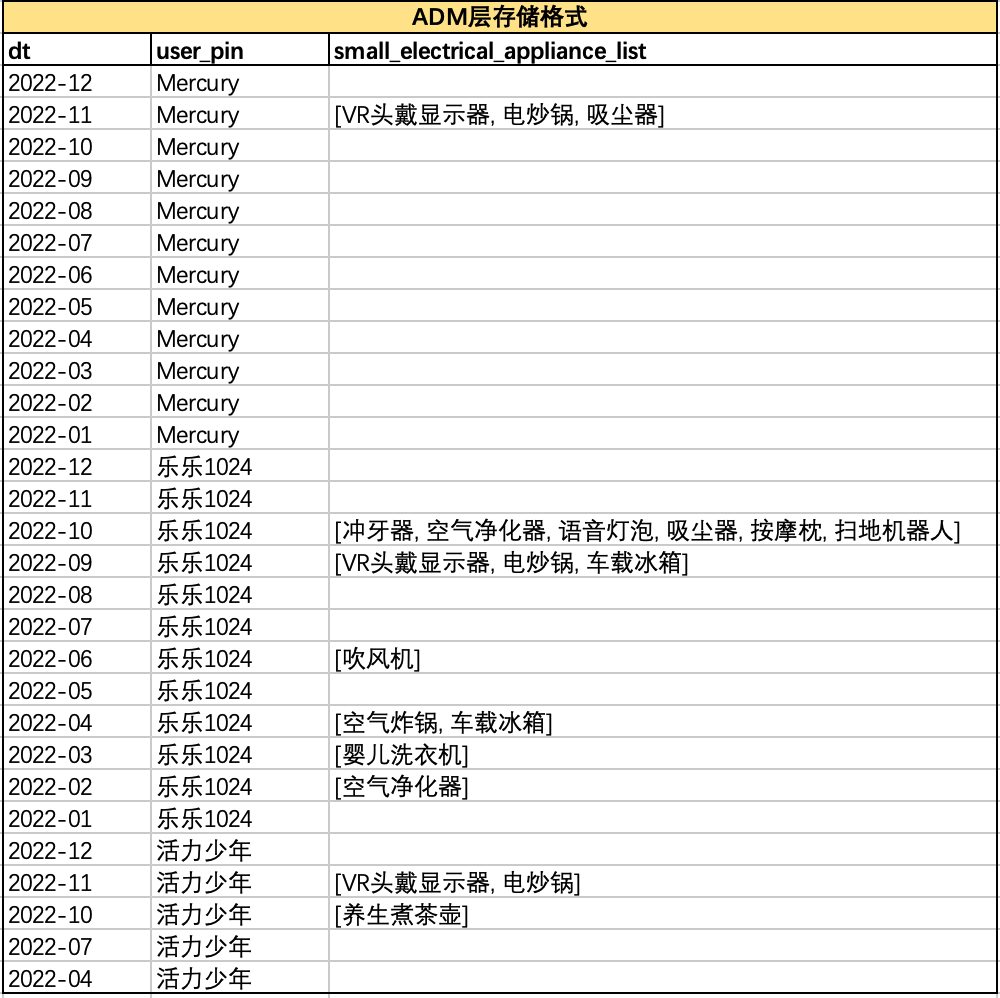
• 根据小家电品类集合字段定义,APP层应取这三个用户全年最后购买的2个品类,即'Mercury'在2022年11月购买的VR头戴显示器、电炒锅,'乐乐1024'在2022年10月购买的冲牙器、空气净化器,'活力少年'在2022年10月购买的VR头戴显示器、电炒锅。因此,经手动计算,APP层正确计算结果应为:

• 而APP层年度账单汇总表中的小家电集合品类如下,结果错误,不符合预期结果。

三、 缺陷排查过程
1. 执行引擎兼容差异
测试排查中,首先发现了Hive和Spark引擎之间的语法兼容差异。
• 当使用APP层脚本中小家电品类集合口径构建SQL,手动对上游表执行查询时发现,Hive引擎得到的集合有序,执行结果正确:

• 使用Spark引擎执行查询时,集合乱序,执行结果错误:

2. 脚本梳理
缺陷原因为集合乱序导致的取数错误。每个用户在上游ADM存在12个数组对应12个月购买小家电品类的集合,需要集合函数(collect)将12个月分组数据倒序排序,汇合成1个列表,然后取列表前两个元素。
HQL提供两种分组聚合函数:collect_list()和collect_set(),区别在于collect_set()会对列表元素去重。由于用户不同月购买的品类集合可能重复,因此脚本使用了collect_set()。
然而collect_set()将导致集合乱序,集合中元素不再按月份倒序排列,取出List[0]和List[1]不是用户全年最后购买的两个小家电品类。
SELECT
user_pin,
small_electrical_appliance_list,
concat_ws('|', small_electrical_appliance_list[0], small_electrical_appliance_list[1]) AS small_electrical_appliance
FROM(
SELECT
user_pin,
collect_set(concat_ws(',', small_electrical_appliance_list_split)) AS small_electrical_appliance_list
FROM(
SELECT
dt,
user_pin,
small_electrical_appliance_list,
concat_ws(',', small_electrical_appliance_list) AS small_electrical_appliance
FROM adm_my_jd_user_bill_month
WHERE
dt >= '2022-01'
AND dt <= '2022-12'
ORDER BY dt DESC) tmp
lateral VIEW explode(SPLIT(small_electrical_appliance, ',')) tmp AS small_electrical_appliance_list_split
GROUP BY user_log_acct )
3. 结论
• 计算脚本逻辑错误,不应使用collect_set()聚合分组。
• 在原生Hive/Spark中,collect_set()函数均无法保证集合有序,而大数据平台Hive对集合计算有序。因此,该脚本在Hive引擎下可以达到生成全年最后购买两个小家电品类的预期目标,但spark引擎则无法得到正确结果。
• Hive执行效率较低,研发通常通过Spark引擎执行,最终导致结果错误。
四、大数据计算引擎兼容差异
1. collect_list()/collect_set() 在hive/spark和presto之间的区别
• collect_set()与collect_list()在Presto中无法兼容。
• 替代函数:array_agg() (https://prestodb.io/docs/current/functions/aggregate.html?highlight=array_agg#array_agg)
| Hive/Spark | Presto |
|---|---|
| collect_list() | array_agg() |
| collect_set() | array_distinct(array_agg()) |
2. 行转列函数在hive和presto之间的区别
• Hive使用lateral VIEW explode()执行行转列的操作,而Presto不支持该函数。这种单列的值转换成和student列一对多的行的值映射.
◦ Hive/Spark query:
lateral VIEW explode(SPLIT(small_electrical_appliance, ',')) tmp AS small_electrical_appliance_list_split
• Presto支持UNNEST来扩展array和map。文档:(https://prestodb.io/docs/current/migration/from-hive.html)
◦ Presto query:
CROSS JOIN UNNEST(SPLIT(small_electrical_appliance, ',')) AS small_electrical_appliance_list_split;
3. 隐式转换在引擎之间的区别
• Hive/Spark支持包括字符串类型到数字类型在内的多种隐式转换,如将字符串'07'转化为数字7,然后进行比较操作。
◦ Hive隐式转换规则:详见链接 Allowed Implicit Conversions
• 虽然Presto也有自己的一套隐式类型转换规则包含在public Optional<Type> coerceTypeBase(Type sourceType, String resultTypeBase)方法中,但对数据类型的要求更为严格。一些在Hive中常见的数字与字符串进行比较的查询语句,Presto会直接抛类型不一致的错误。
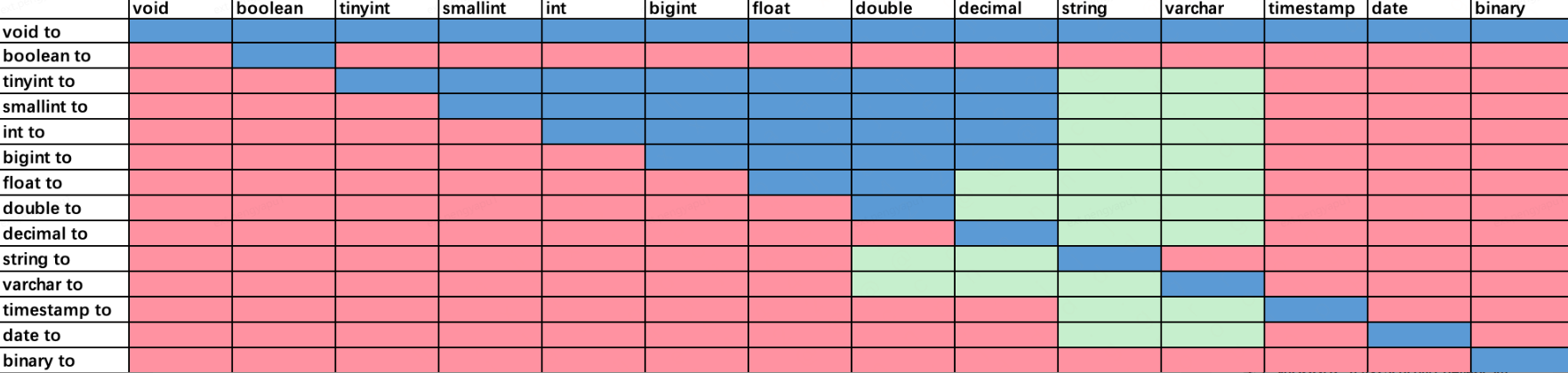
◦ 下图为Hive和Presto的隐式转换规则,蓝色区域是Presto和Hive都支持的类型转换,绿色区域是Presto不支持但是Hive支持的类型转换,红色区域是两者都不支持的类型转换。可以看到,hive的隐式转换更为广泛,而presto尤其在字符类型的隐式转换中更为严格。
• 隐式转换示例:
--Hive/Spark隐式转换
'07' >= 6 -- true (CAST('07' AS DOUBLE) >= CAST(6 AS DOUBLE))
'test' <> 1 -- NULL
'1' = 1.0 -- true
--Presto隐式转换
'07' >= 6 -- false (CAST('07' AS Varchar) >= CAST(6 AS Varchar))
'test' <> 1 -- true
'1' = 1.0 -- ERROR:io.prestosql.spi.PrestoException: Unexpected parameters (varchar(1), decimal(2,1)) for function $operator$equal. Expected: $operator$equal(T, T) T:comparable

 浙公网安备 33010602011771号
浙公网安备 33010602011771号