微服务拆分治理最佳实践
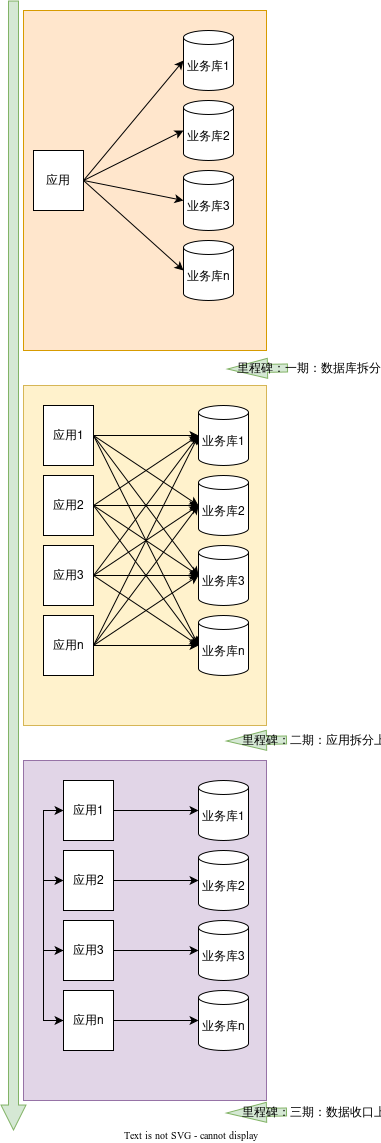
 随着业务快速发展,各种问题越来越明显,急需对系统进行微服务改造优化。经过思考,整体改造将分为三个阶段进行:数据库拆分、应用拆分、数据访问权限收口。
随着业务快速发展,各种问题越来越明显,急需对系统进行微服务改造优化。经过思考,整体改造将分为三个阶段进行:数据库拆分、应用拆分、数据访问权限收口。
作者:京东零售 徐强 黄威 张均杰
背景
部门中维护了一个老系统,功能都耦合在一个单体应用中(300+接口),表也放在同一个库中(200+表),导致系统存在很多风险和缺陷。经常出现问题:如数据库的单点、性能问题,应用的扩展受限,复杂性高等问题。
从下图可见。各业务相互耦合无明确边界,调用阿关系错综复杂。
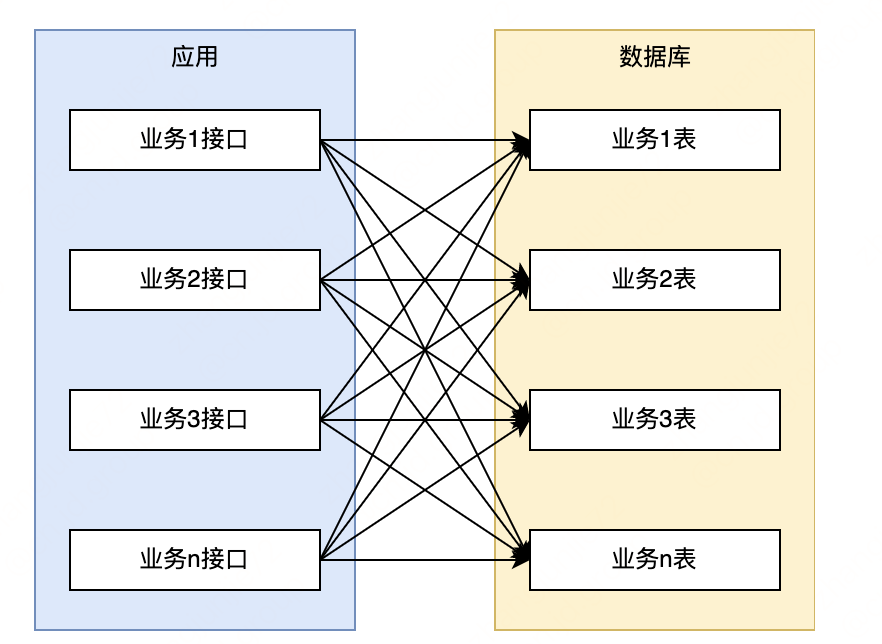
随着业务快速发展,各种问题越来越明显,急需对系统进行微服务改造优化。经过思考,整体改造将分为三个阶段进行:
-
数据库拆分:数据库按照业务垂直拆分。
-
应用拆分:应用按照业务垂直拆分。
-
数据访问权限收口:数据权限按照各自业务领域,归属到各自的应用,应用与数据库一对一,禁止交叉访问。
数据库拆分
单体数据库的痛点:未进行业务隔离,一个慢SQL易导致系统整体出现问题;吞吐量高,读写压力大,性能下降;
数据库改造
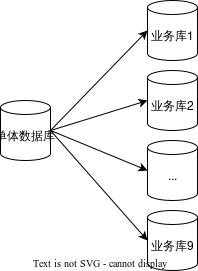
根据业务划分,我们计划将数据库拆分为9个业务库。数据同步方式采用主从复制的方式,并且通过binlog过滤将对应的表和数据同步到对应的新数据库中。
代码改造方案
如果一个接口中操作了多张表,之前这些表属于同一个库,数据库拆分后可能会分属于不同的库。所以需要针对代码进行相应的改造。
目前存在问题的位置:
-
数据源选择:系统之前是支持多数据源切换的,在service上添加注解来选择数据源。数据库拆分后出现的情况是同一个service中操作的多个mapper从属于不同的库。
-
事务:事务注解目前是存在于service上的,并且事务会缓存数据库链接,一个事务内不支持同时操作多个数据库。
改造点梳理:
-
同时写入多个库,且是同一事务的接口6个:需改造数据源,需改造事务,需要关注分布式事务;
-
同时写入多个库,且不是同一事务的接口50+:需改造数据源,需改造事务,无需关注分布式事务;
-
同时读取多个库 或 读取一个库写入另一个库的接口200+:需改造数据源,但无需关注事务;
-
涉及多个库的表的联合查询8个:需进行代码逻辑改造
梳理方式:
采用部门中的切面工具,抓取入口和表的调用关系(可识别表的读/写操作),找到一个接口中操作了多个表,并且多个表分属于不同业务库的情况;
分布式事务:
进行应用拆分和数据收口之后,是不存在分布式事务的问题的,因为操作第二个库会调用对应系统的RPC接口进行操作。所以本次不会正式支持分布式事务,而是采用代码逻辑保证一致性的方式来解决;
方案一
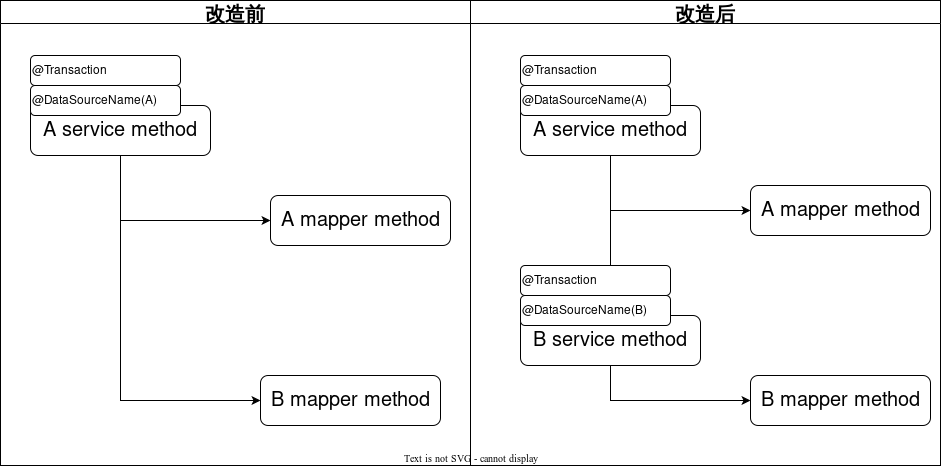
将service中分别操作多个库的mapper,抽取成多个Service。分别添加切换数据源注解和事务注解。
问题:改动位置多,涉及改动的每个方法都需要梳理历史业务;service存在很多嵌套调用的情况,有时难以理清逻辑;修改200+位置改动工作量大,风险高;
方案二
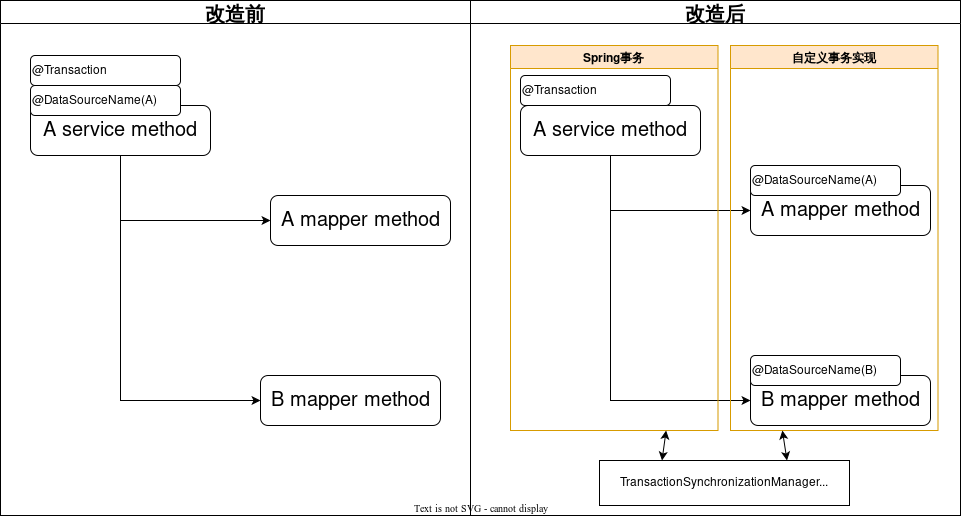
如图所示,方案二将数据源注解移动到Mapper上,并使用自定义的事务实现来处理事务。
将多数据源注解放到Mapper上的好处是,不需要梳理代码逻辑,只需要在Mapper上添加对应数据源名称即可。但是这样又有新的问题出现,
-
问题1:如上图,事务的是配置在Service层,当事务开启时,数据源的连接并没有获取到,因为真正的数据源配置在Mapper上。所以会报错,这个错误可以通过多数据源组件的默认数据源功能解决。
-
问题2:mybatis的事务实现会缓存数据库链接。当第一次缓存了数据库链接后,后续配置在mapper上的数据源注解并不会重新获取数据库链接,而是直接使用缓存起来的数据库链接。如果后续的mapper要操作其余数据库,会出现找不到表的情况。鉴于以上问题,我们开发了一个自定义的事务实现类,用来解决这个问题。
下面将对方案中出现的两个组件进行简要说明原理。
多数据源组件
多数据源组件是单个应用连接多个数据源时使用的工具,其核心原理是通过配置文件将数据库链接在程序启动时初始化好,在执行到存在注解的方法时,通过切面获取当前的数据源名称来切换数据源,当一次调用涉及多个数据源时,会利用栈的特性解决数据源嵌套的问题。
/**
* 切面方法
*/
public Object switchDataSourceAroundAdvice(ProceedingJoinPoint pjp) throws Throwable {
//获取数据源的名字
String dsName = getDataSourceName(pjp);
boolean dataSourceSwitched = false;
if (StringUtils.isNotEmpty(dsName)
&& !StringUtils.equals(dsName, StackRoutingDataSource.getCurrentTargetKey())) {
// 见下一段代码
StackRoutingDataSource.setTargetDs(dsName);
dataSourceSwitched = true;
}
try {
// 执行切面方法
return pjp.proceed();
} catch (Throwable e) {
throw e;
} finally {
if (dataSourceSwitched) {
StackRoutingDataSource.clear();
}
}
}
public static void setTargetDs(String dbName) {
if (dbName == null) {
throw new NullPointerException();
}
if (contextHolder.get() == null) {
contextHolder.set(new Stack<String>());
}
contextHolder.get().push(dbName);
log.debug("set current datasource is " + dbName);
}
StackRoutingDataSource继承 AbstractRoutingDataSource类,AbstractRoutingDataSource是spring-jdbc包提供的一个了AbstractDataSource的抽象类,它实现了DataSource接口的用于获取数据库链接的方法。
自定义事务实现
从方案二的图中可以看到默认的事务实现使用的是mybatis的SpringManagedTransaction。
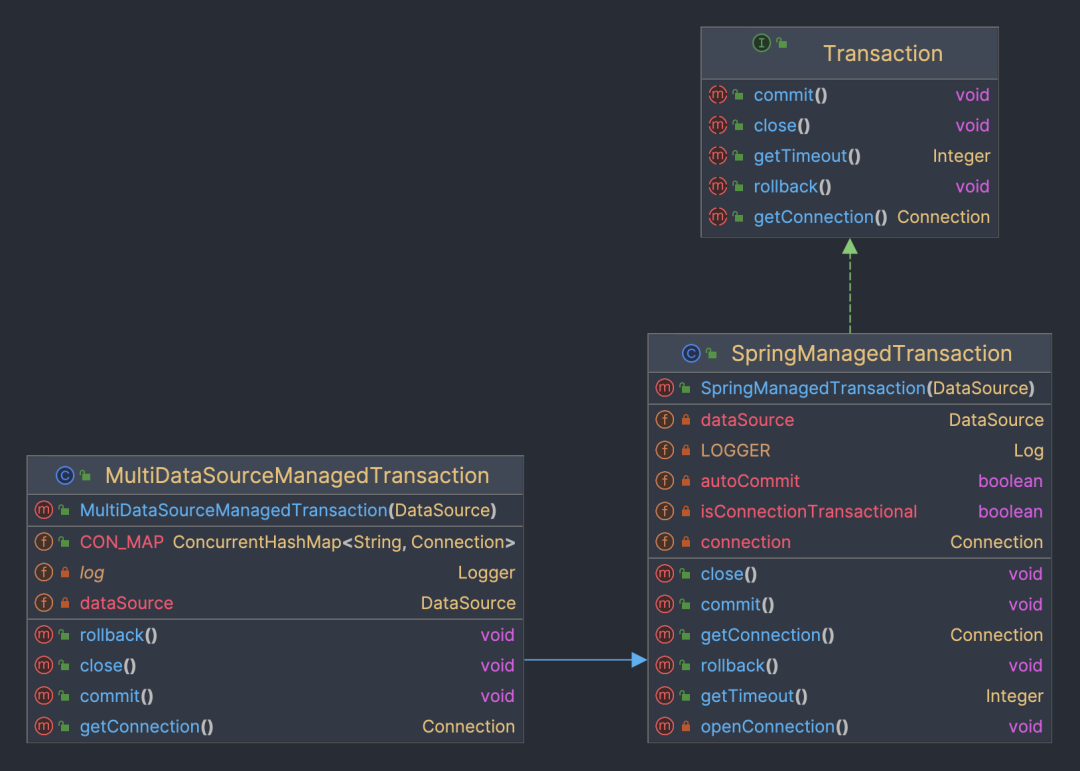
如上图,Transaction和SpringManagedTransaction都是mybatis提供的类,他提供了接口供SqlSession使用,处理事务操作。
通过下边的一段代码可以看到,事务对象中存在connection变量,首次获得数据库链接后,后续当前事务内的所有数据库操作都不会重新获取数据库链接,而是会使用现有的数据库链接,从而无法支持跨库操作。
public class SpringManagedTransaction implements Transaction {
private static final Log LOGGER = LogFactory.getLog(SpringManagedTransaction.class);
private final DataSource dataSource;
private Connection connection;
private boolean isConnectionTransactional;
private boolean autoCommit;
public SpringManagedTransaction(DataSource dataSource) {
notNull(dataSource, "No DataSource specified");
this.dataSource = dataSource;
}
// 下略
}
MultiDataSourceManagedTransaction是我们自定义的事务实现,继承自SpringManagedTransaction类,并在内部支持维护多个数据库链接。每次执行数据库操作时,会根据数据源名称判断,如果当前数据源没有缓存的链接则重新获取链接。这样,service上的事务注解其实控制了多个单库事务,且作用域范围相同,一起进行提交或回滚。
代码如下:
public class MultiDataSourceManagedTransaction extends SpringManagedTransaction {
private DataSource dataSource;
public ConcurrentHashMap<String, Connection> CON_MAP = new ConcurrentHashMap<>();
public MultiDataSourceManagedTransaction(DataSource dataSource) {
super(dataSource);
this.dataSource = dataSource;
}
@Override
public Connection getConnection() throws SQLException {
Method getCurrentTargetKey;
String dataSourceKey;
try {
getCurrentTargetKey = dataSource.getClass().getDeclaredMethod("getCurrentTargetKey");
getCurrentTargetKey.setAccessible(true);
dataSourceKey = (String) getCurrentTargetKey.invoke(dataSource);
} catch (Exception e) {
log.error("MultiDataSourceManagedTransaction invoke getCurrentTargetKey 异常", e);
return null;
}
if (CON_MAP.get(dataSourceKey) == null) {
Connection connection = dataSource.getConnection();
if (!TransactionSynchronizationManager.isActualTransactionActive()) {
connection.setAutoCommit(true);
} else {
connection.setAutoCommit(false);
}
CON_MAP.put(dataSourceKey, connection);
return connection;
}
return CON_MAP.get(dataSourceKey);
}
@Override
public void commit() throws SQLException {
if (CON_MAP == null || CON_MAP.size() == 0) {
return;
}
Set<Map.Entry<String, Connection>> entries = CON_MAP.entrySet();
for (Map.Entry<String, Connection> entry : entries) {
Connection value = entry.getValue();
if (!value.isClosed() && !value.getAutoCommit()) {
value.commit();
}
}
}
@Override
public void rollback() throws SQLException {
if (CON_MAP == null || CON_MAP.size() == 0) {
return;
}
Set<Map.Entry<String, Connection>> entries = CON_MAP.entrySet();
for (Map.Entry<String, Connection> entry : entries) {
Connection value = entry.getValue();
if (value == null) {
continue;
}
if (!value.isClosed() && !value.getAutoCommit()) {
entry.getValue().rollback();
}
}
}
@Override
public void close() throws SQLException {
if (CON_MAP == null || CON_MAP.size() == 0) {
return;
}
Set<Map.Entry<String, Connection>> entries = CON_MAP.entrySet();
for (Map.Entry<String, Connection> entry : entries) {
DataSourceUtils.releaseConnection(entry.getValue(), this.dataSource);
}
CON_MAP.clear();
}
}
注:上面并不是分布式事务。在数据收口之前,它只存在于同一个JVM中。如果项目允许,可以考虑使用Atomikos和Mybatis整合的方案。
数据安全性
本次进行了很多代码改造,如何保证数据安全,保证数据不丢失,我们的机制如下,分为三种情况进行讨论:
-
跨库事务:6处,采用了代码保证一致性的改造方式;上线前经过重点测试,保证逻辑无问题;
-
单库事务:依赖于自定义事务实现,针对自定义事务实现这一个类进行充分测试即可,测试范围小,安全性有保障;
-
其余单表操作:相关修改是在mapper上添加了数据源切换注解,改动位置几百处,几乎是无脑改动,但也存在遗漏或错改的可能;测试同学可以覆盖到核心业务流程,但边缘业务可能会遗漏;我们添加了线上监测机制,当出现找不到表的错误时(说明数据源切换注解添加错误),记录当前执行sql并报警,我们进行逻辑修复与数据处理。
综上,通过对三种情况的处理来保证数据的安全性。
应用拆分
系统接近单体架构,存在以下风险:
-
系统性风险:一个组件缺陷会导致整个进程崩溃,如内存泄漏、死锁。
-
复杂性高:系统代码繁多,每次修改代码都心惊胆战,任何一个bug都可能导致整个系统崩溃,不敢优化代码导致代码可读性也越来越差。
-
测试环境冲突,测试效率低:业务都耦合在一个系统,只要有需求就会出现环境抢占,需要额外拉分支合并代码。
拆分方案
与数据库拆分相同,系统拆分也是根据业务划分拆成9个新系统。
方案一:搭建空的新系统,然后将老系统的相关代码挪到新系统。
-
优点:一步到位。
-
缺点:需要主观挑选代码,然后挪到新系统,可视为做了全量业务逻辑的变动,需要全量测试,风险高,周期长。
方案二:从老系统原样复制出9个新系统,然后直接上线,通过流量路由将老系统流量转发到新系统,后续再对新系统的冗余代码做删减。
-
优点:拆分速度快, 首次上线前无业务逻辑改动,风险低;后续删减代码时依据接口调用量情况来判定,也可视为无业务逻辑的改动,风险较低,并且各系统可各自进行,无需整体排期, 较为灵活。
-
缺点:分为了两步,拆分上线和删减代码

我们在考虑拆分风险和拆分效率后,最终选择了方案二。
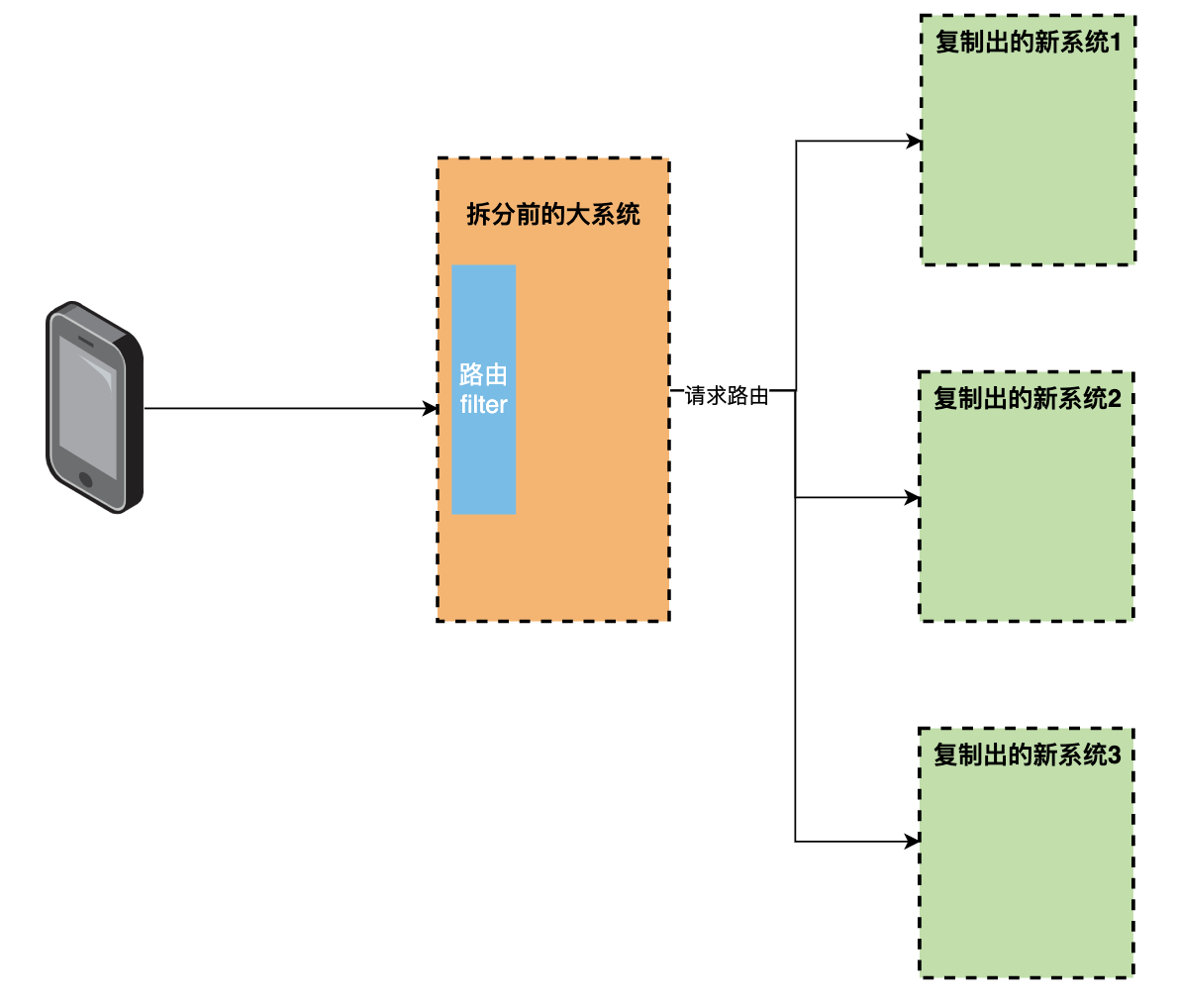
拆分实践
1、搭建新系统
直接复制老系统代码,修改系统名称,部署即可
2、流量路由
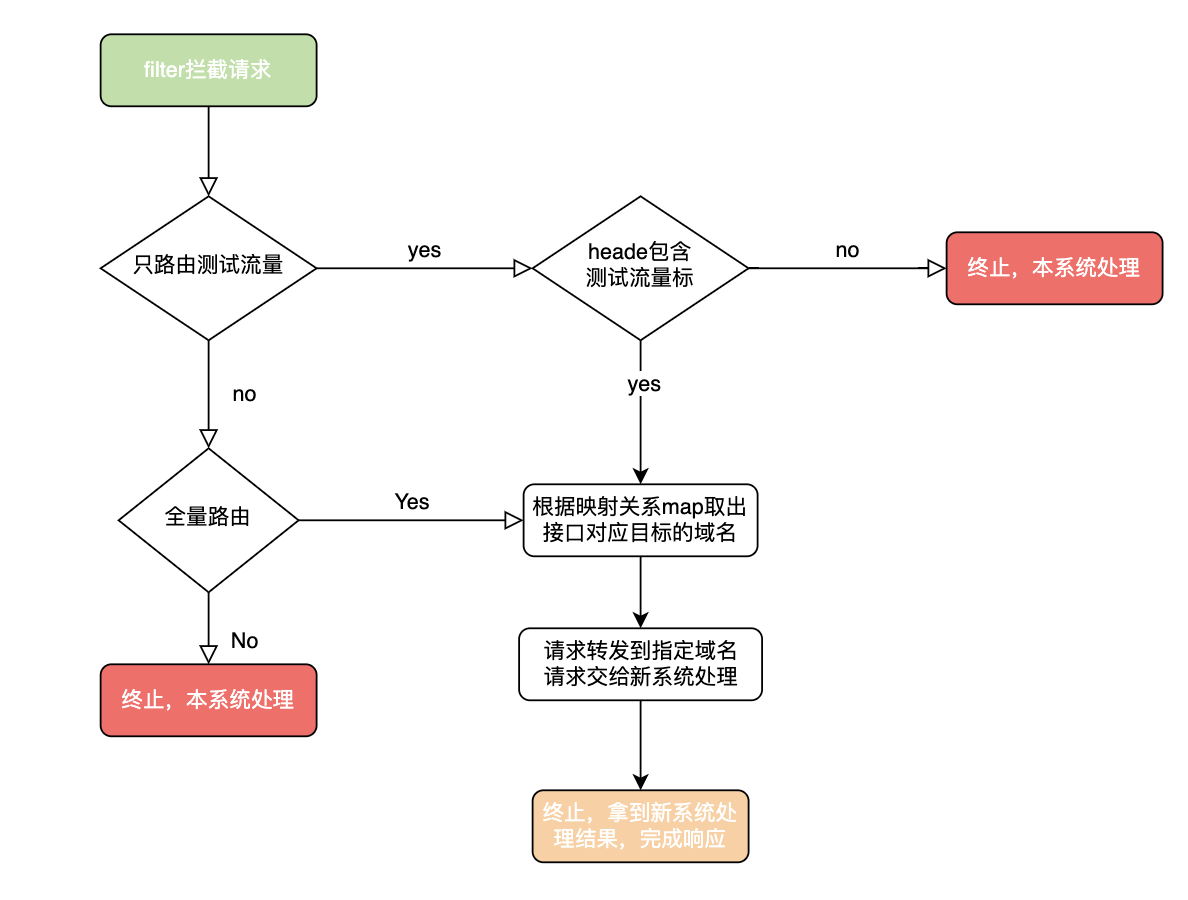
路由器是拆分的核心,负责分发流量到新系统,同时需要支持识别测试流量,让测试同学可以提前在线上测试新系统。我们这边用filter来作为路由器的,源码见下方。
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain filterChain) throws ServletException, IOException {
HttpServletRequest servletRequest = (HttpServletRequest) request;
HttpServletResponse servletResponse = (HttpServletResponse) response;
// 路由开关(0-不路由, 1-根据指定请求头路由, 2-全量路由)
final int systemRouteSwitch = configUtils.getInteger("system_route_switch", 1);
if (systemRouteSwitch == 0) {
filterChain.doFilter(request, response);
return;
}
// 只路由测试流量
if (systemRouteSwitch == 1) {
// 检查请求头是否包含测试流量标识 包含才进行路由
String systemRoute = ((HttpServletRequest) request).getHeader("systemRoute");
if (systemRoute == null || !systemRoute.equals("1")) {
filterChain.doFilter(request, response);
return;
}
}
String systemRouteMapJsonStr = configUtils.getString("route.map", "");
Map<String, String> map = JSONObject.parseObject(systemRouteMapJsonStr, Map.class);
String rootUrl = map.get(servletRequest.getRequestURI());
if (StringUtils.isEmpty(rootUrl)) {
log.error("路由失败,本地服务内部处理。原因:请求地址映射不到对应系统, uri : {}", servletRequest.getRequestURI());
filterChain.doFilter(request, response);
return;
}
String targetURL = rootUrl + servletRequest.getRequestURI();
if (servletRequest.getQueryString() != null) {
targetURL = targetURL + "?" + servletRequest.getQueryString();
}
RequestEntity<byte[]> requestEntity = null;
try {
log.info("路由开始 targetURL = {}", targetURL);
requestEntity = createRequestEntity(servletRequest, targetURL);
ResponseEntity responseEntity = restTemplate.exchange(requestEntity, byte[].class);
if (requestEntity != null && requestEntity.getBody() != null && requestEntity.getBody().length > 0) {
log.info("路由完成-请求信息: requestEntity = {}, body = {}", requestEntity.toString(), new String(requestEntity.getBody()));
} else {
log.info("路由完成-请求信息: requestEntity = {}", requestEntity != null ? requestEntity.toString() : targetURL);
}
HttpHeaders headers = responseEntity.getHeaders();
String resp = null;
if (responseEntity.getBody() != null && headers != null && headers.get("Content-Encoding") != null && headers.get("Content-Encoding").contains("gzip")) {
byte[] bytes = new byte[30 * 1024];
int len = new GZIPInputStream(new ByteArrayInputStream((byte[]) responseEntity.getBody())).read(bytes, 0, bytes.length);
resp = new String(bytes, 0, len);
}
log.info("路由完成-响应信息: targetURL = {}, headers = {}, resp = {}", targetURL, JSON.toJSONString(headers), resp);
if (headers != null && headers.containsKey("Location") && CollectionUtils.isNotEmpty(headers.get("Location"))) {
log.info("路由完成-需要重定向到 {}", headers.get("Location").get(0));
((HttpServletResponse) response).sendRedirect(headers.get("Location").get(0));
}
addResponseHeaders(servletRequest, servletResponse, responseEntity);
writeResponse(servletResponse, responseEntity);
} catch (Exception e) {
if (requestEntity != null && requestEntity.getBody() != null && requestEntity.getBody().length > 0) {
log.error("路由异常-请求信息: requestEntity = {}, body = {}", requestEntity.toString(), new String(requestEntity.getBody()), e);
} else {
log.error("路由异常-请求信息: requestEntity = {}", requestEntity != null ? requestEntity.toString() : targetURL, e);
}
response.setCharacterEncoding("UTF-8");
((HttpServletResponse) response).addHeader("Content-Type", "application/json");
response.getWriter().write(JSON.toJSONString(ApiResponse.failed("9999", "网络繁忙哦~,请您稍后重试")));
}
}
3、接口抓取&归类
路由filter是根据接口路径将请求分发到各个新系统的,所以需要抓取一份接口和新系统的映射关系。
我们这边自定义了一个注解@TargetSystem,用注解标识接口应该路由到的目标系统域名,
@TargetSystem(value = "http://order.demo.com")
@GetMapping("/order/info")
public ApiResponse orderInfo(String orderId) {
return ApiResponse.success();
}
然后遍历获取所有controller根据接口地址和注解生成路由映射关系map
/**
* 生成路由映射关系MAP
* key:接口地址 ,value:路由到目标新系统的域名
*/
public Map<String, String> generateRouteMap() {
Map<RequestMappingInfo, HandlerMethod> handlerMethods = requestMappingHandlerMapping.getHandlerMethods();
Set<Map.Entry<RequestMappingInfo, HandlerMethod>> entries = handlerMethods.entrySet();
Map<String, String> map = new HashMap<>();
for (Map.Entry<RequestMappingInfo, HandlerMethod> entry : entries) {
RequestMappingInfo key = entry.getKey();
HandlerMethod value = entry.getValue();
Class declaringClass = value.getMethod().getDeclaringClass();
TargetSystem targetSystem = (TargetSystem) declaringClass.getAnnotation(TargetSystem.class);
String targetUrl = targetSystem.value();
String s1 = key.getPatternsCondition().toString();
String url = s1.substring(1, s1.length() - 1);
map.put(url, targetUrl);
}
return map;
}

4、测试流量识别
测试可以用利用抓包工具charles,为每个请求都添加固定的请求头,也就是测试流量标识,路由器拦截请求后判断请求头内是否包含测试流量标,包含就路由到新系统,不包含就是线上流量留在老系统执行。
5、需求代码合并
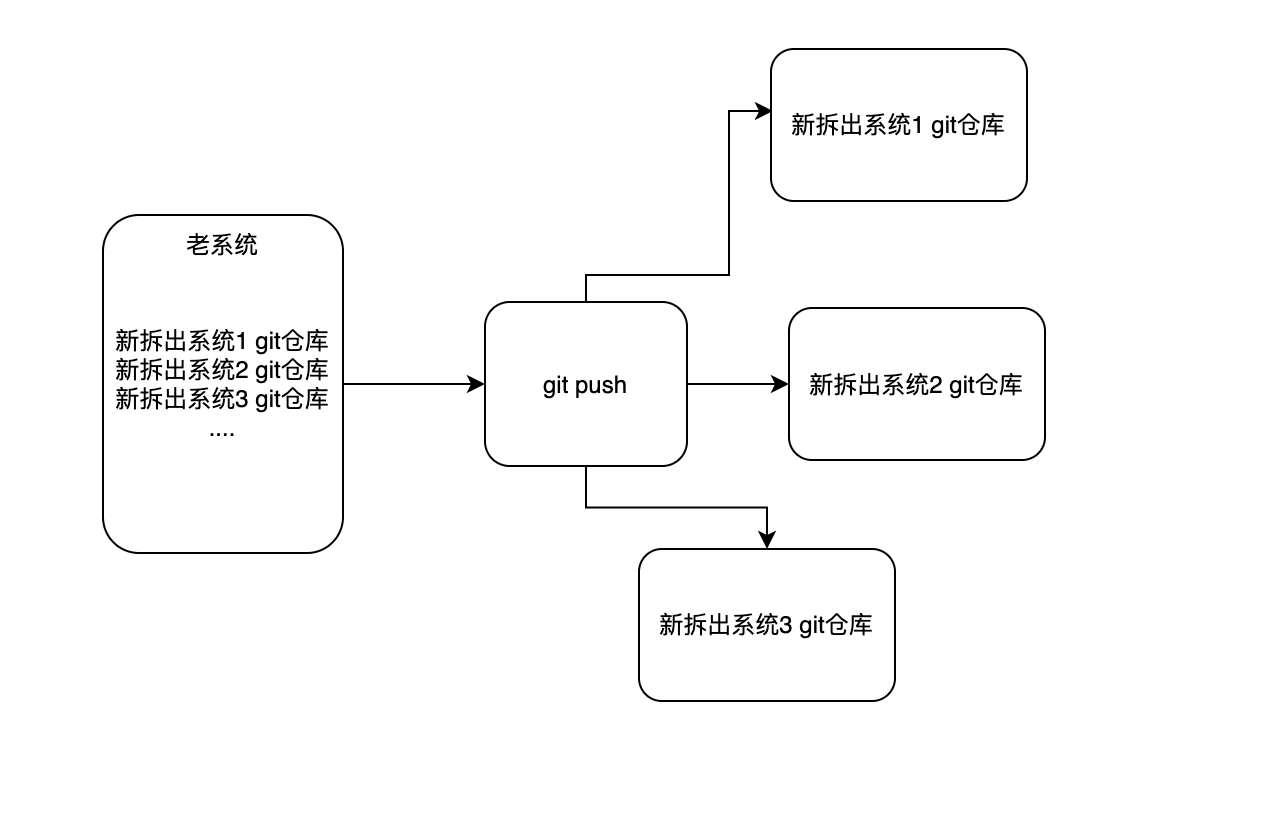
执行系统拆分的过程中,还是有需求正在并行开发,并且需求代码是写在老系统的,系统拆分完成上线后,需要将这部分需求的代码合并到新系统,同时要保证git版本记录不能丢失,那应该怎么做呢?
我们利用了git可以添加多个多个远程仓库来解决需求合并的痛点,命令:git remote add origin 仓库地址,把新系统的git仓库地址添加为老系统git的远程仓库,老系统的git变动就可以同时push到所有新系统的仓库内,新系统pull下代码后进行合并。
6、上线风险
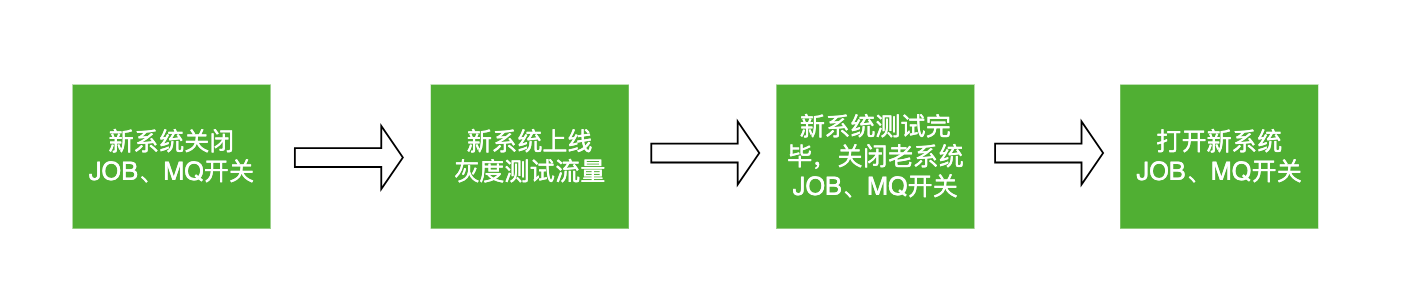
风险一:JOB在新老系统并行执行。新系统是复制的老系统,JOB也会复制过来,导致新老系统有相同的JOB,如果这时候上线新系统,新系统的JOB就会执行,老系统的JOB也一直在run,这样一个JOB就会执行2次。新系统刚上线还没经过测试验证,这时候执行JOB是有可能失败的。以上2种情况都会引起线上Bug,影响系统稳定性。
风险二:新系统提前消费MQ。和风险一一样,新系统监听和老系统一样的topic,如果新系统直接上线,消息是有可能被新系统消费的,新系统刚上线还没经过测试验证,消费消息有可能会出异常,造成消息丢失或其他问题,影响系统稳定性。
如何解决以上2个上线风险呢?
我们用“动态开关”解决了上述风险,为新老系统的JOB和MQ都加了开关,用开关控制JOB和MQ在新/老系统执行。上线后新系统的JOB和MQ都是关掉的,待QA测试通过后,把老系统的JOB和MQ关掉,把新系统的JOB和MQ打开就可以了。
系统瘦身
拆分的时候已经梳理出了一份“入口映射关系map”,每个新系统只需要保留自己系统负责的接口、JOB、MQ代码就可以了,除此之外都可以进行删除。
拆分带来的好处
-
系统架构更合理,可用性更高:即使某个服务挂了也不会导致整个系统崩溃
-
复杂性可控:每个系统都是单一职责,系统逻辑清晰
-
系统性能提升上限大:可以针对每个系统做优化,如加缓存
-
测试环境冲突的问题解决,不会因为多个系统需求并行而抢占环境
数据访问权限收口
问题介绍
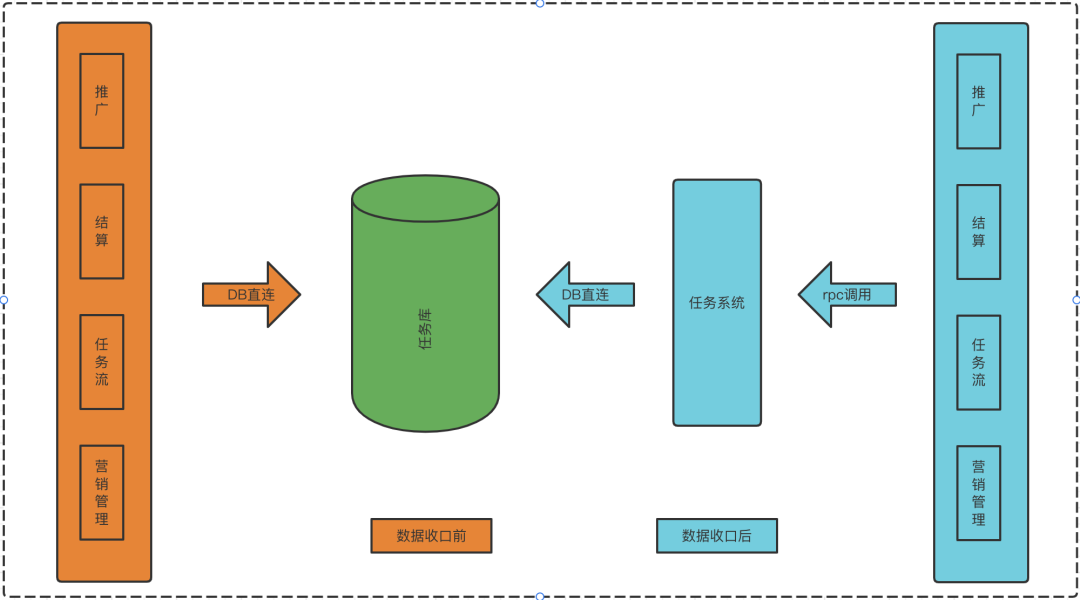
数据访问权限未收口:一个业务的数据库被其余业务应用直接访问,未通过rpc接口将数据访问权限收口到数据拥有方自己的应用。数据访问逻辑分散,存在业务耦合,阻碍后续迭代和优化。
问题产生的背景:之前是单体应用和单体数据库,未进行业务隔离。在进行数据库拆分和系统拆分时,为解决系统稳定性的问题需快速上线,所以未优化拆分后跨业务访问数据库的情况。本阶段是对数据库拆分和应用拆分的延伸和补充。
改造过程
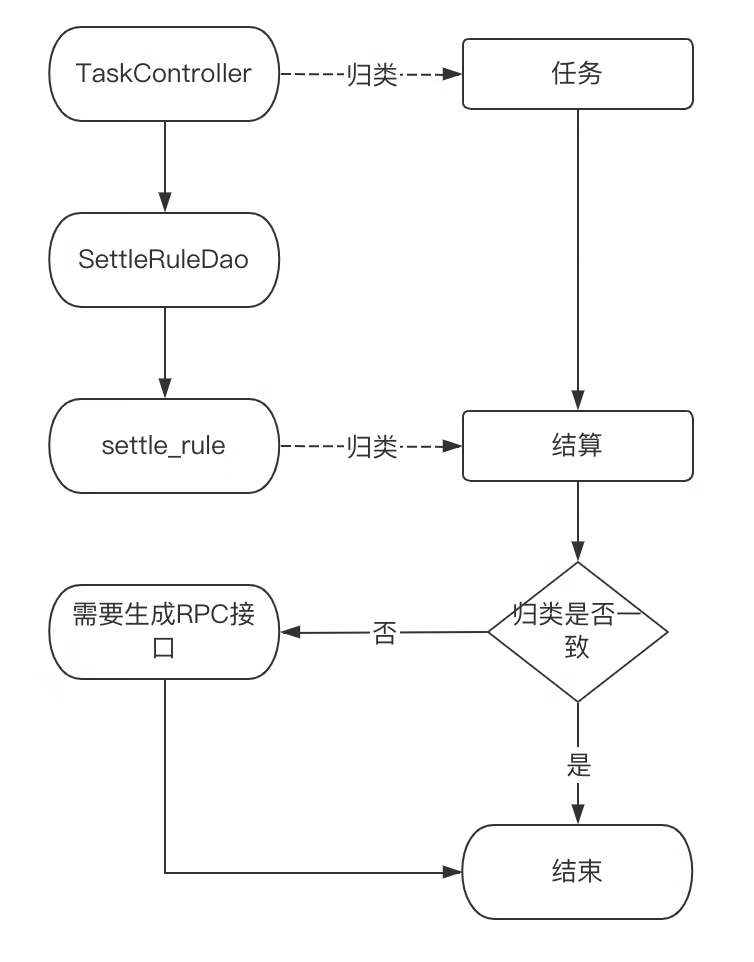
- RPC接口统计(如图一)
进行比对,如程序入口归类和调用的业务DB归类不一致,则认为Dao方法需提供RPC接口
经统计,应用访问非本业务数据库的位置有260+。由于涉及位置多,人工改造成本高、效率较低,且有错改和漏掉的风险,我们采用了开发工具,用工具进行代码生成和批量修改的方式进行改造。
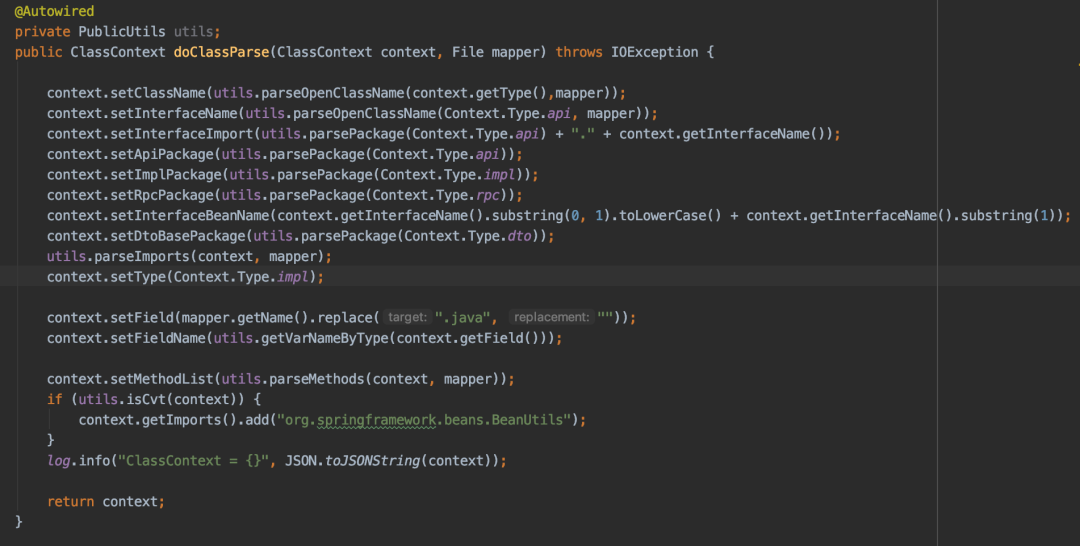
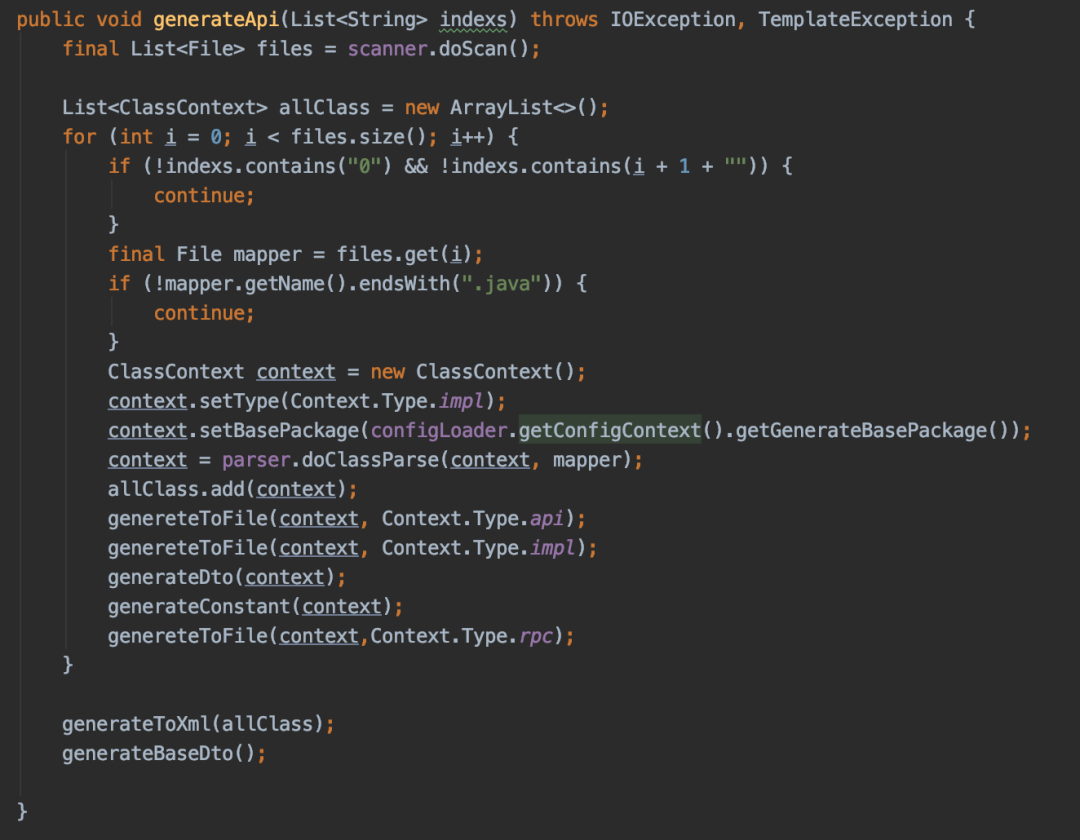
- RPC接口生成(如图二)
-
读取需要生成RPC接口的Dao文件,进行解析
-
获取文件名称,Dao方法列表,import导包列表等,放入ClassContext上下文
-
匹配api、rpc文件模板,从classContext内取值替换模板变量,通过package路径生成java文件到指定服务内
-
批量将服务内Dao名称后缀替换为Rpc服务名,减少人工改动风险,例:SettleRuleDao -> SettleRuleRpc
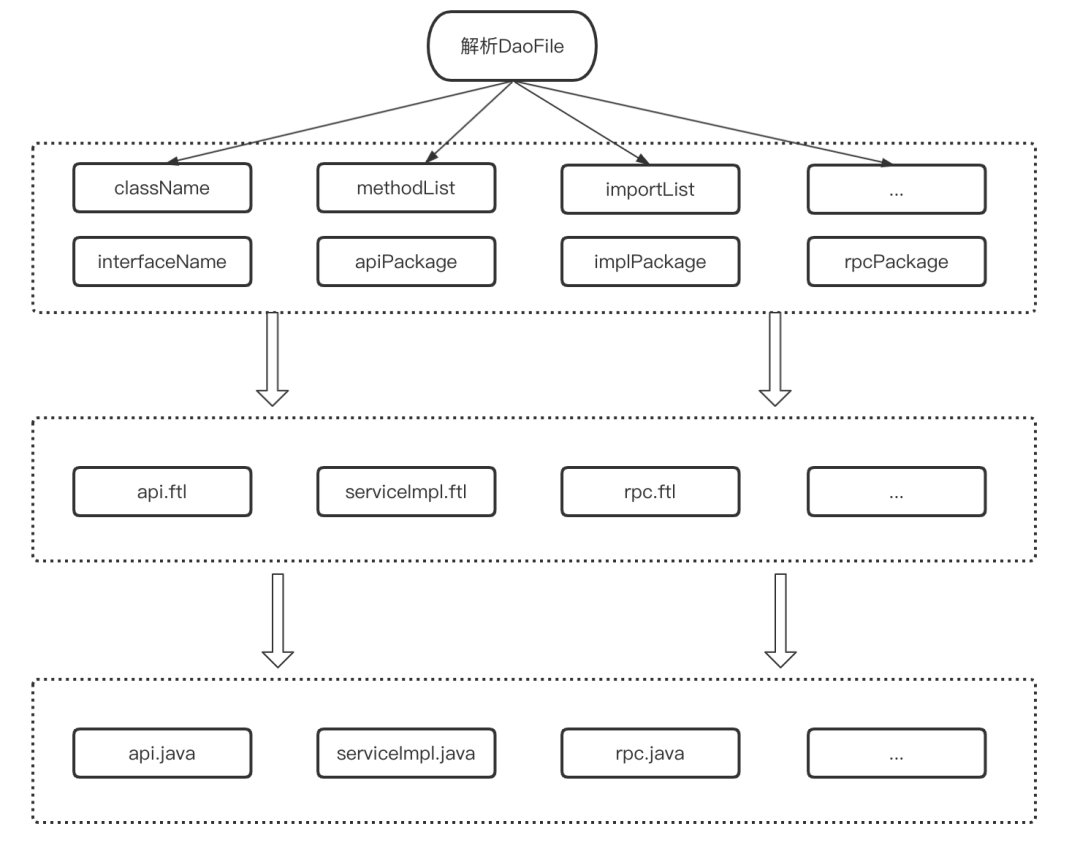
名词解释:
-
ftl:Freemarker模板的文件后缀名,FreeMarker是一个模版引擎,一个基于文本的模板输出工具。
-
interfaceName:用存放api文件名称
-
className:用于存放serviceImpl文件名称
-
methodList:用于存放方法列表,包含入参、出参、返回值等信息
-
importList:用于存放api和impl文件内其他引用实体的导包路径
-
apiPackage:用于存放生成的Api接口类包名
-
implPackage:用于存放生成的Api实现类包名
-
rpcPackage:用于存放生成的rpc调用类包名
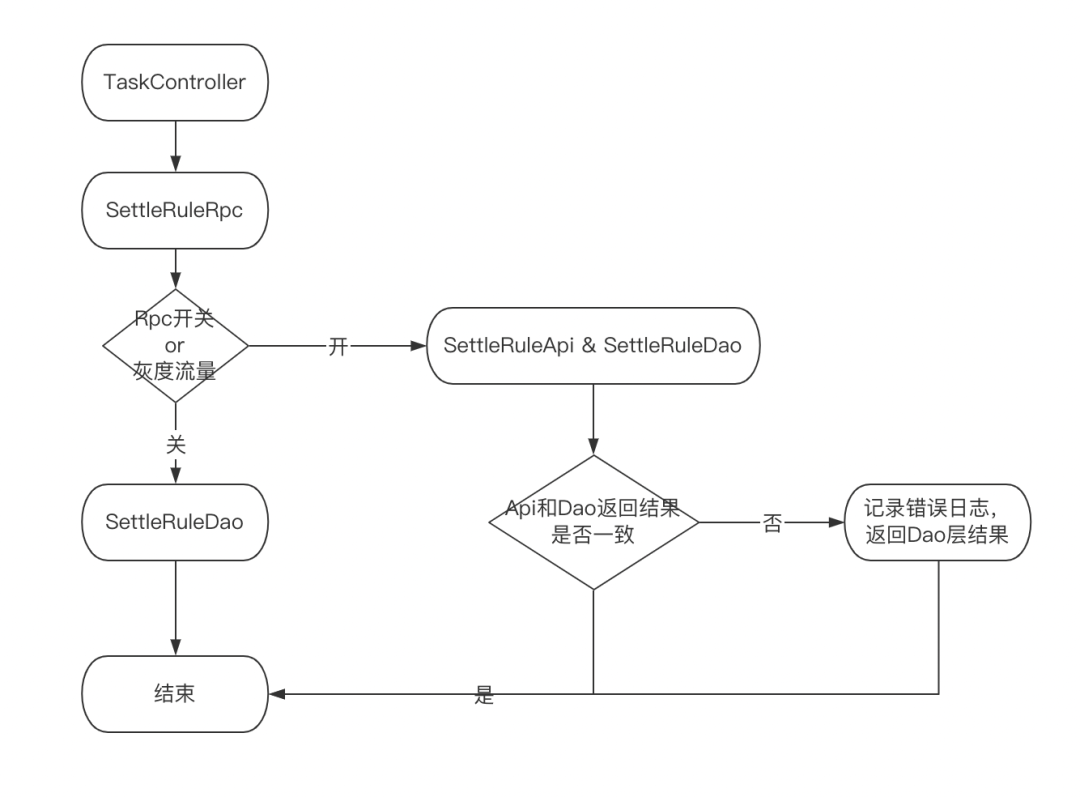
- 灰度方案(如图三)
-
数据操作统一走RPC层处理,初期阶段RPC层兼顾RPC调用,也有之前的DAO调用,使用开关切换。
-
RPC层进行双读,进行Api层和Dao层返回结果的比对,前期优先返回Dao层结果,验证无问题后,在全量返回RPC的结果,清除其他业务数据库连接。
-
支持开关一键切换,按流量进行灰度,降低数据收口风险
收益
-
业务数据解耦,数据操作统一由各自垂直系统进行,入口统一
-
方便后续在接口粒度上增加缓存和降级处理
总结
以上,是我们对单体系统的改造过程,经过了三步优化、上线,将单体系统平滑过渡到了微服务结构。解决了数据库的单点问题、性能问题,应用业务得到了简化,更利于分工,迭代。并且可以针对各业务单独进行优化升级,扩容、缩容,提升了资源的利用率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号