
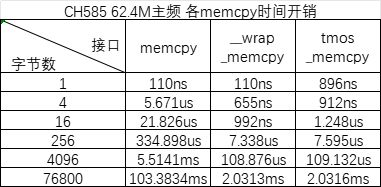
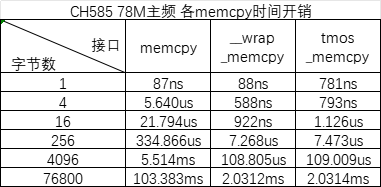
CH585的各memcpy时间开销测试
在涉及大块的/高频次的数据传输时,需要考虑数组拷贝的时间开销。本文基于CH585,测试了部分场景下的memcpy时间开销。
如果选型用的是CH592等型号,不支持__wrap_memcpy,可以用该博客中的接口:https://www.cnblogs.com/gscw/p/18636006
注:
①使用CH585M_R1_1v0开发板+2024年11月25日EVT驱动代码
②在main()中多次拷贝+GPIOA_InverseBits(GPIO_Pin_2);翻转IO测试。main()函数加了HIGHCODE修饰,翻转IO的时间开销也计在表格中
③拷贝源地址:const数组,目的地址:ram数组。拷贝涉及到的数组都用__attribute__((aligned(4)))修饰一下,确保数组的起始地址4字节对齐
④在工程配置中添加-Wl,--wrap=memcpy后,调用memcpy()接口即可获得__wrap_memcpy()的速度,代码中不必将“memcpy”替换为“__wrap_memcpy”

 浙公网安备 33010602011771号
浙公网安备 33010602011771号