(十四--十五)数据库查询优化Part I
(十四--十五)数据库查询优化Part I
如果理解的有问题。欢迎大家指出。这也是我在看课记得笔记。。可能会有很多问题
查询优化的重要性
- 请记住用户只会告诉DMBS他们想要什么样的结果,而不会告诉他们如何获得结果
- 不同的查询plan性能上会有非常大的差距。[比如之前的nested join 和 index join]
1. Heuristics / Rules策略
这一策略侧重于重构那些愚蠢的sql语句
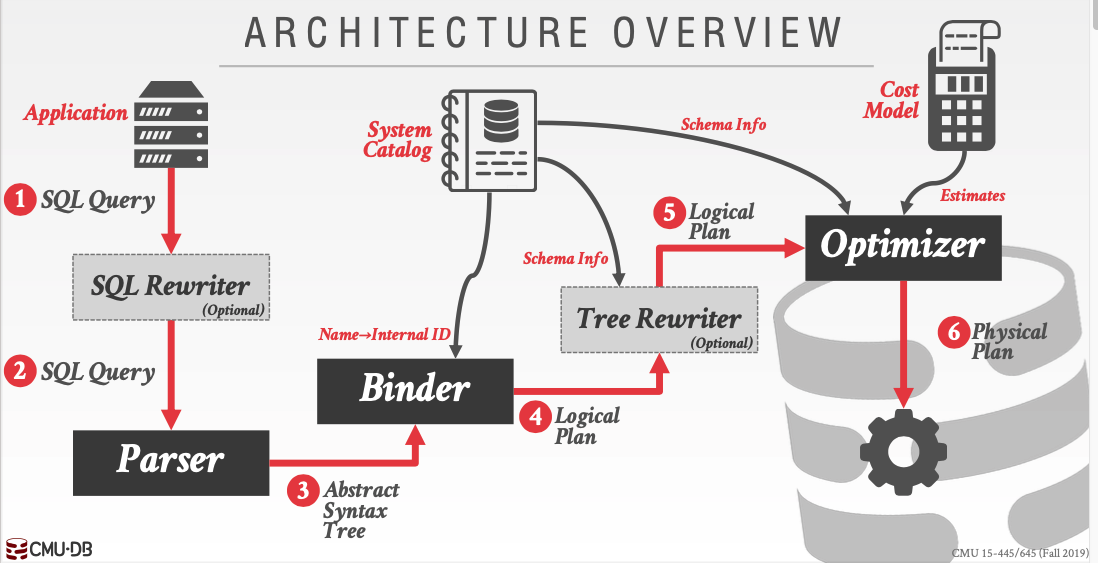
注意这里的Logical Plan和Physical Plan是不同的
- 在第一个阶段我们会重写SQL语句。这里更多的是利用一些启发式的思维,比如列裁剪(过滤掉查询不需要使用到的列)、谓词下推(将过滤尽可能地下沉到数据源端)、常量累加(比如 1 + 2 这种事先计算好) 以及常量替换(比如
SELECT * FROM table WHERE i = 5 AND j = i + 3可以转换成SELECT * FROM table WHERE i = 5 AND j = 8)等等。 - 后面会把引用格式转换成内部的标识符,然后构建语法树。至此我们的逻辑计划就大致构建完成。⚠️一个逻辑计划会对应许多的物理计划。
- 最后
Optimizer的作用就是选择代价最小的物理计划。根据代价,将确定从逻辑计划到物理计划的选择
这里需要一点关系代数的只是。但是cmu数据库重点并不是放在这个上面。所以附上一个链接大家看看就好
1.1 重写sql的优化-->谓词PushDown
这里用几个ppt里的例子看一下。这个操作对于查询的优化
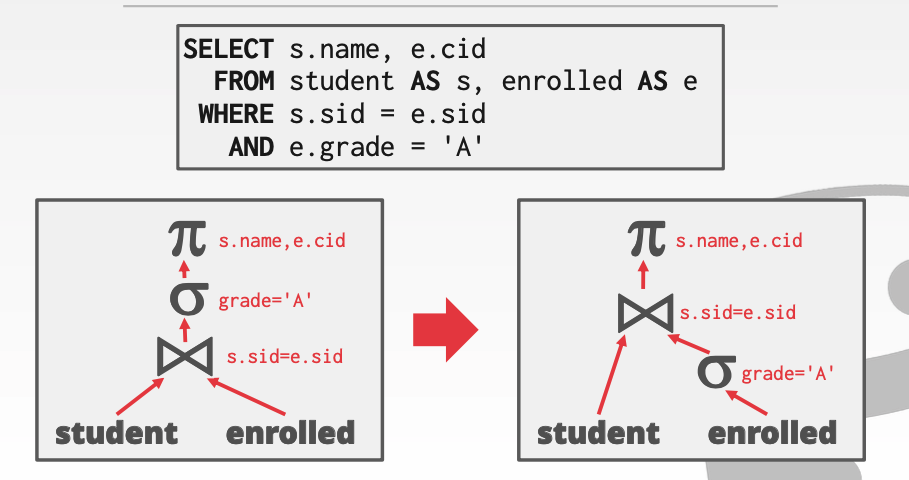
左右两个语法树最后产生的结果完全一致。但是性能上确大相径庭。
左边是整个Student表和右边的enrolled表做join操作。然后再做select操作。但是如果在enrolled表中只有几条元素满足grade==A。这样我们把昨天的sql重写成右边的sql就会让整体的性能提高许多。
从语法树上看我们把select grade =='A'这个谓词向下push了。所以这种优化也叫谓词push down。
1.2 重写sql的优化 --> PROJECTION PUSHDOWN
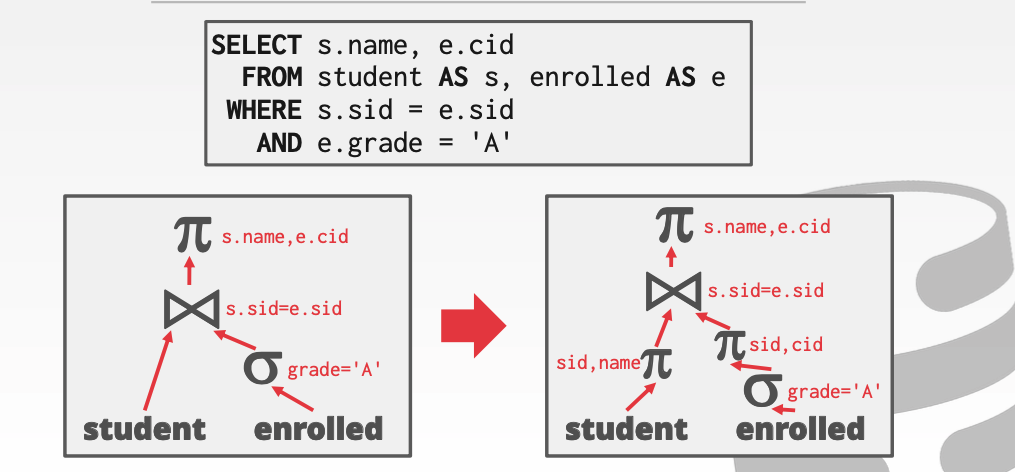
我们先进行投影操作。就可以减少遍历tuple的大小。对于速度和内存上都是不小的优化
同样我们可以直接删掉那些不可能或不必要的谓词
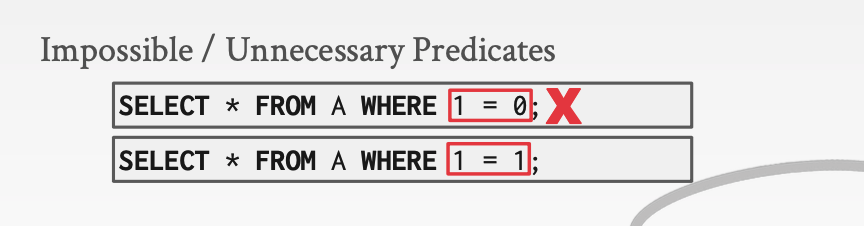

对于下面的我们就可以直接忽略谓词

对于下面的操作我们可以合并谓词

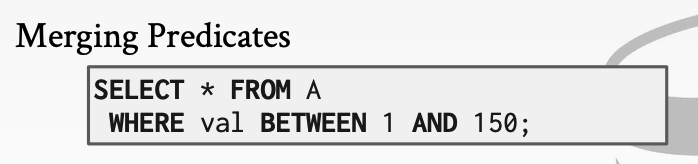
2. COST EMSTIMATION 优化
为了估计花销而引入的一些变量
\(N_R\) : Number of tuples in R.
\(V(A,R)\): Number of distinct values for attribute A.
\(SC(A,R)\) :selection cardinality is the average number of records with a value for an attribute A given \(\frac{N_R}{V(A,R)}\)
2.1 SELECTION STATISTICS
这里假设了所有的数据都符合均匀分布
看下面的例子。这个关系中有5个tuple。年龄分别为0~4。那么假设数据符合均匀分布。年龄为2的人在里面就占了百分之20.

再看下面对于范围谓词的例子
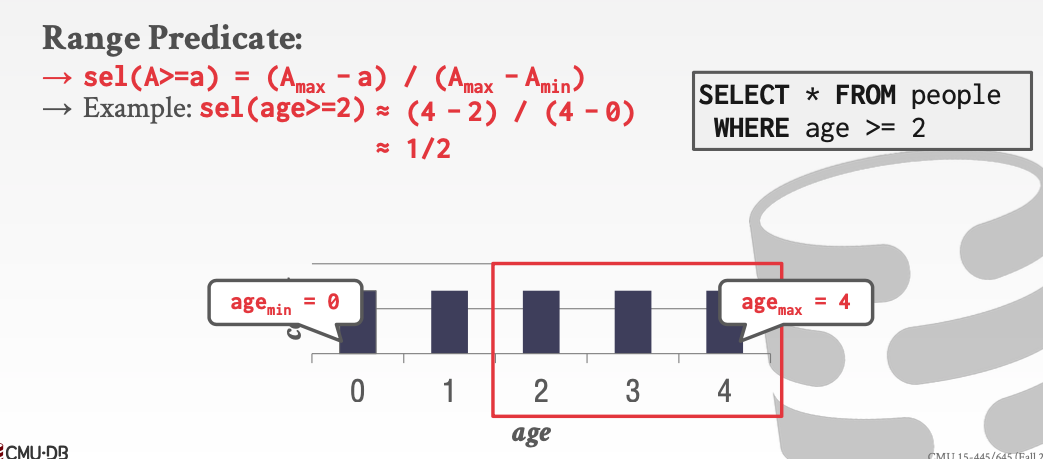
这里其实很好理解。就是看A所在的范围在整个数据范围占的比例
对于neg谓词
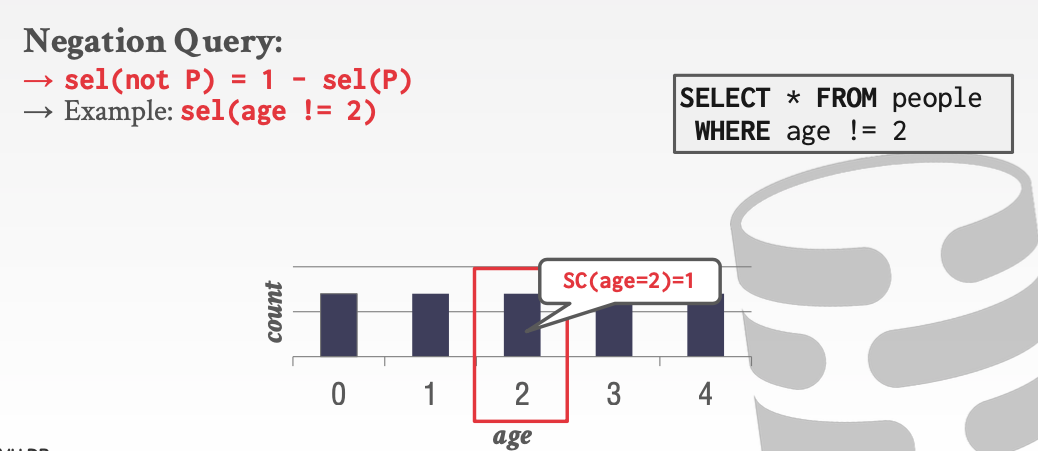
一些复杂的谓词
这里和概率论里的容斥原理基本类似
- 对于交运算

- 对于或运算

2.2 SELECTION CARDINALITY
显然数据不可能完全符合均匀分布。这里具体看一下不同分布的数据如何进行
对于数据不均衡的分布。
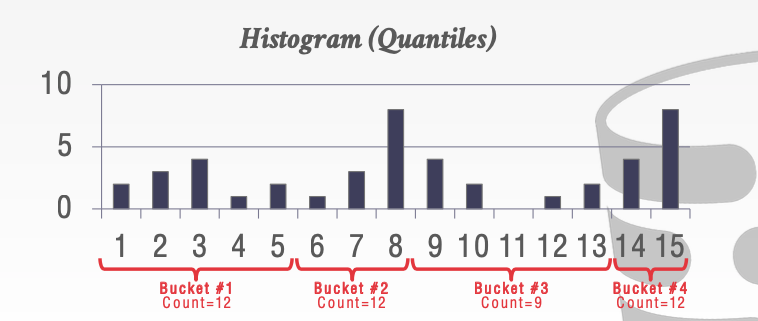
- 我们对数据进行分桶。随后统计每个桶内元素的个数
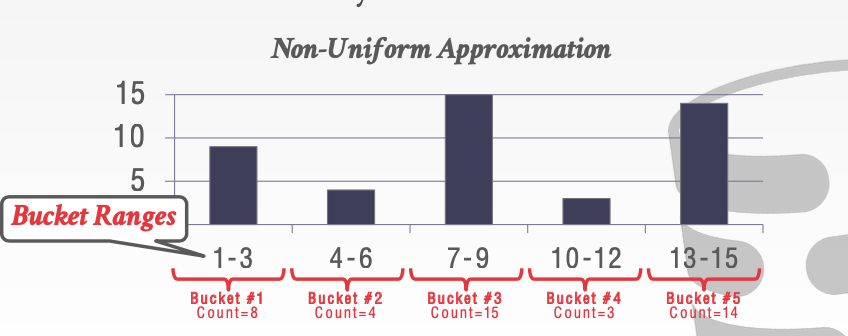
- 我们更改桶的范围。来尽量使每个桶内的元素个数相同
2.3 Sample
这里的sample就和深度学习里的sample一个意思。
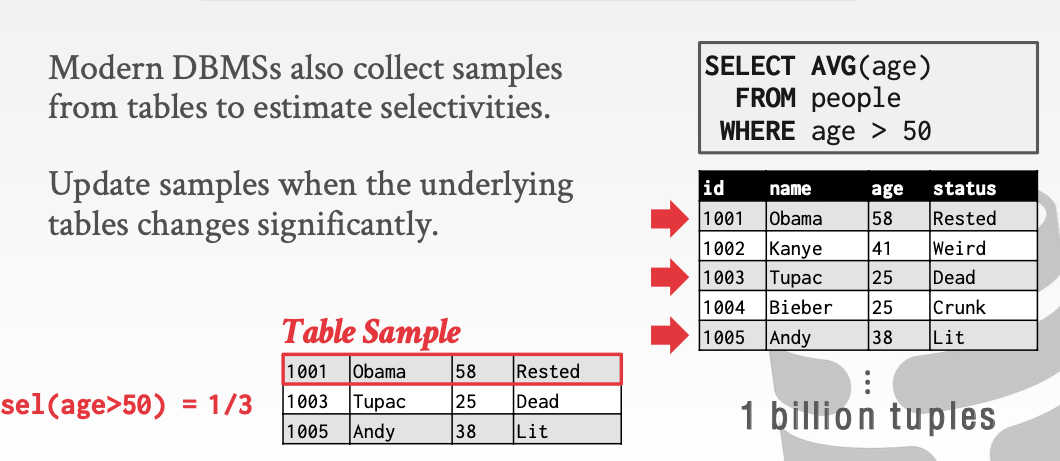
比如对于这个例子。我们在有一亿个tuple的表中随机sample出来三个tuple。以此来代表整个表中tuple的情况。当然这样是不准确的。但是作为一个简单的先学知识是完全可以的。
3. 应用动态规划的优化
从下面这个例子开始
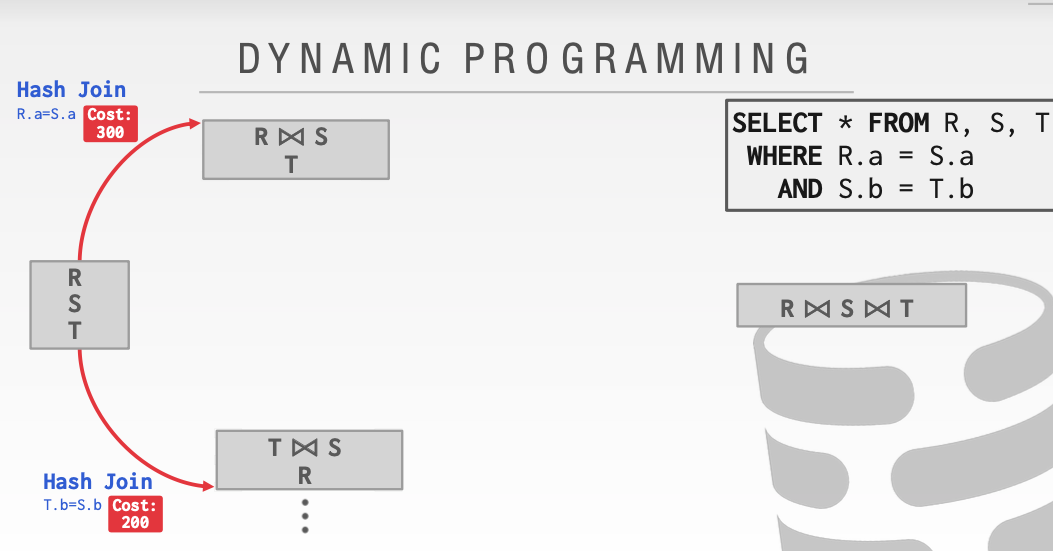
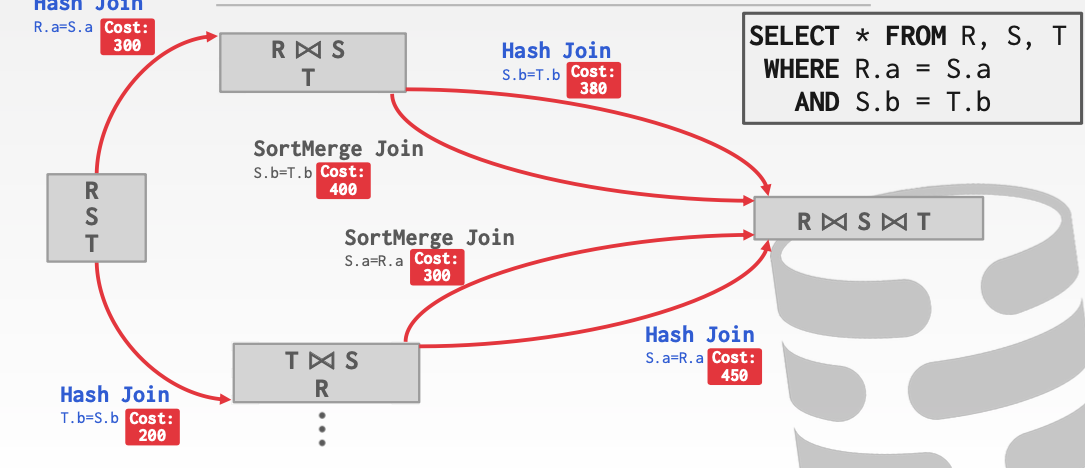
可以看见在第二步奔向第三步的时候,我们有了不同的选择。这里的Hash Join和sortMerge Join有了不同的花费。显然我们应该 选择花费更小的路径。
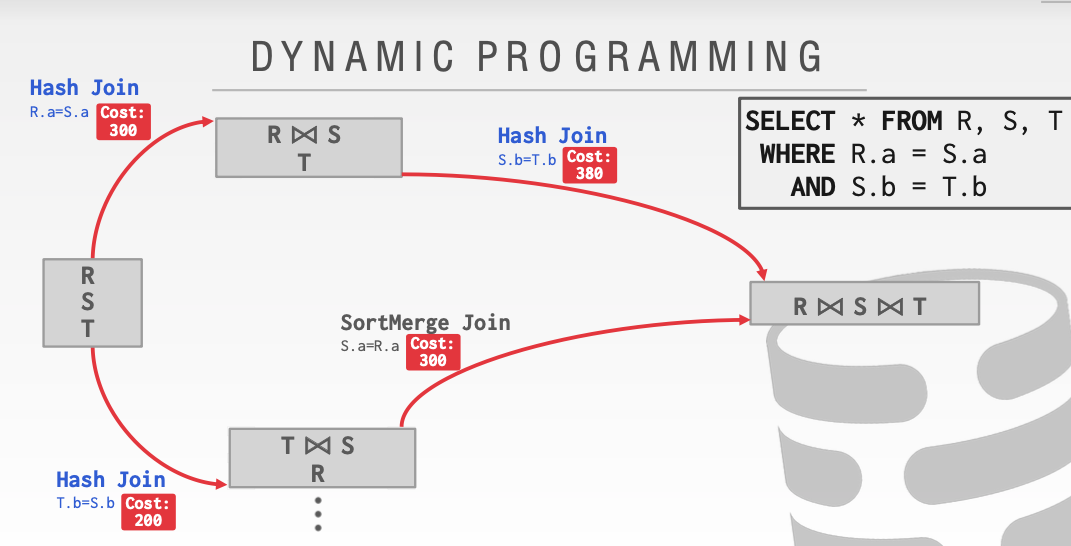
这里回到第一步我们应该选择一条花费更小的路径。由于200 + 300 < 300 + 300 。因此我们应该选择下面这条。
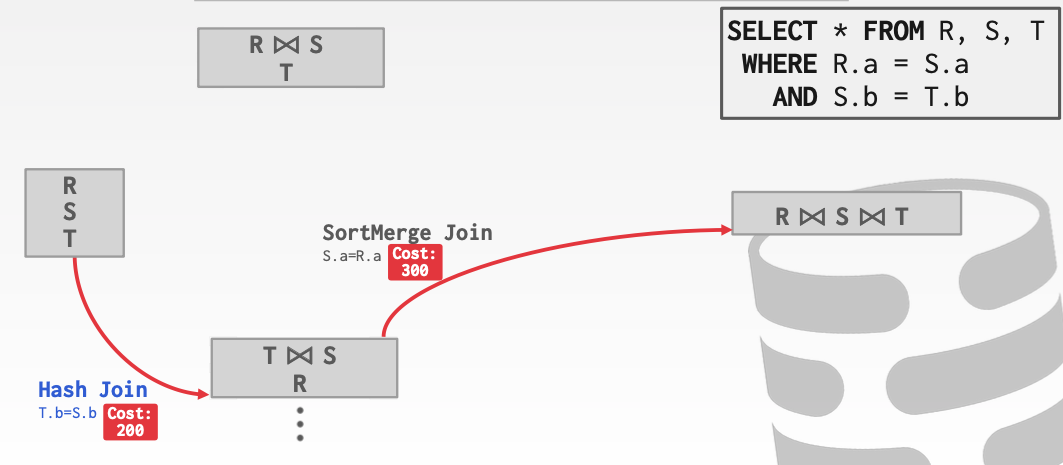
4. 候选plan的选择
由于一条逻辑plan会对应许多的物理plan
那么如何选择一个最好的plan。请看下面的步骤
- 首先列举出来所有的candidate plan
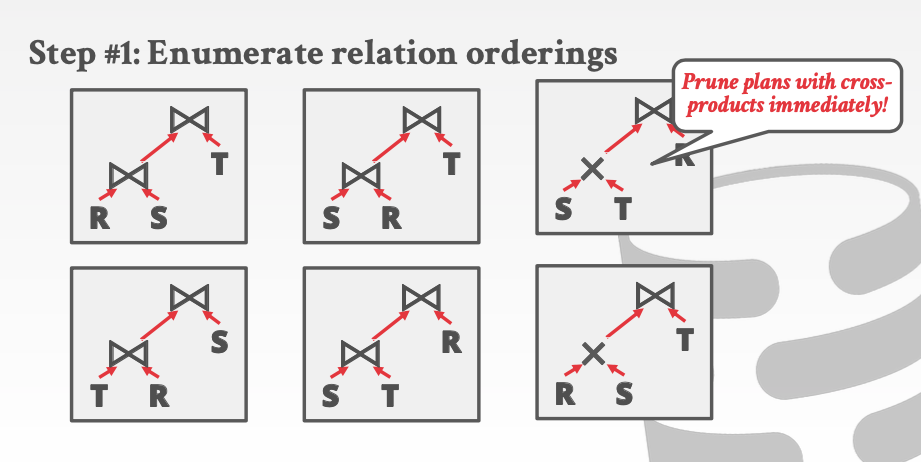
- 立即去掉所有带corss-product操作的plan
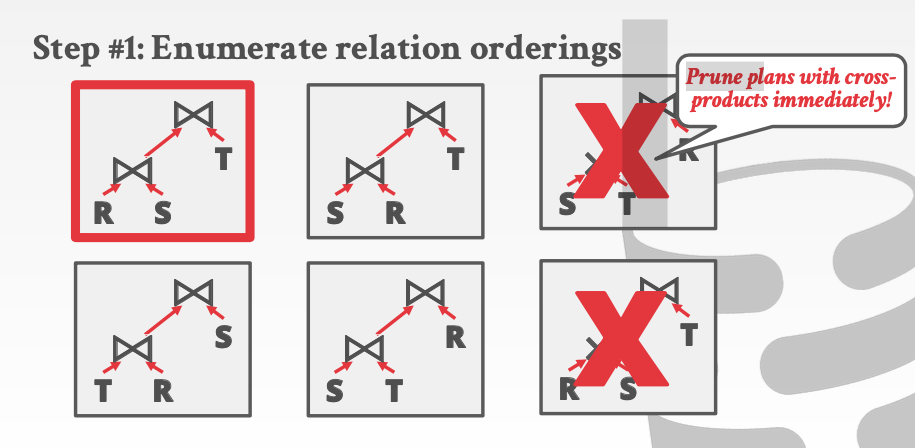
- 用不同的join算法替代join操作。这样就可以列出所有的情况
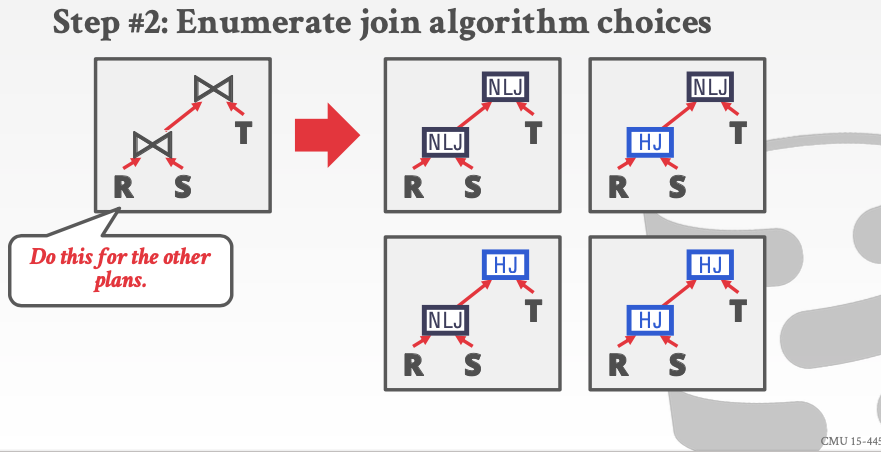
NLJ = nested Loop Join
HJ = hash join
显然我们可以从里面选择最好的。也就是两个join操作都基于HJ
- 在替代所有的访问算法
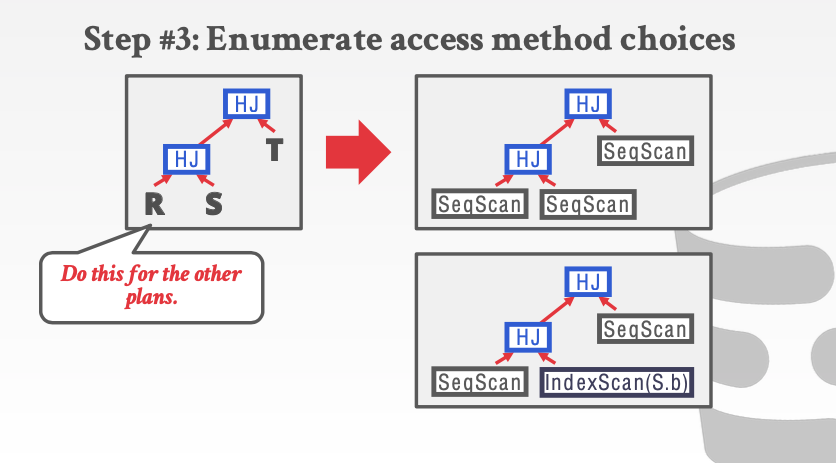
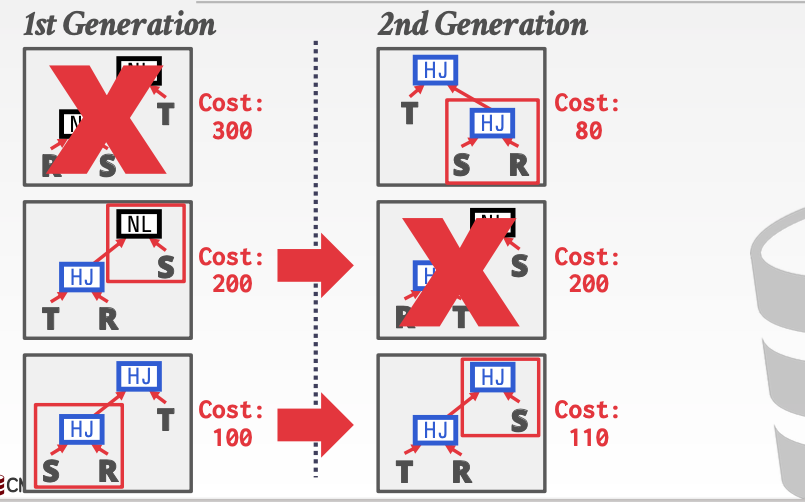
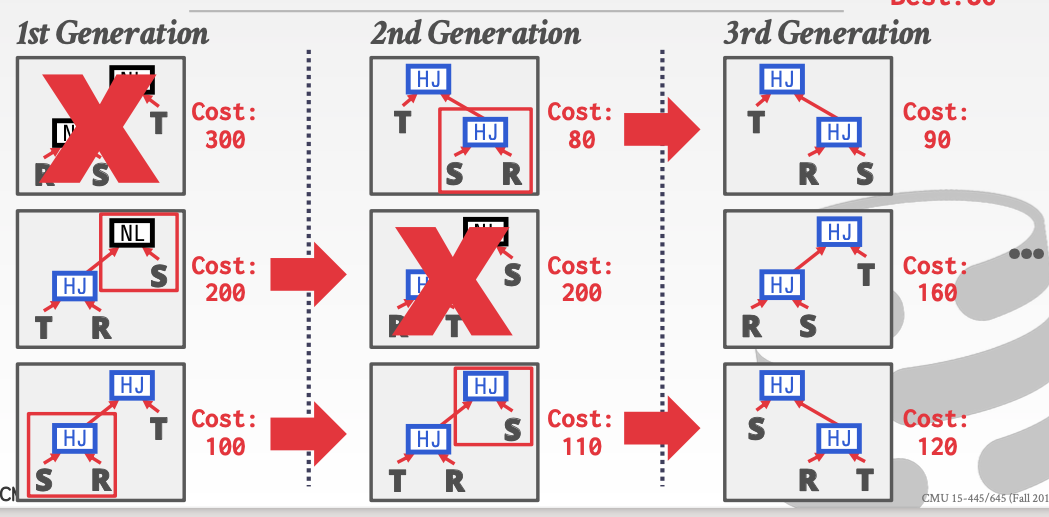
5. POSTGRES OPTIMIZER
这种优化方法主要针对于语法树的重构。每次都淘汰一种花费最多的方案。对于其他的方案都给机会。
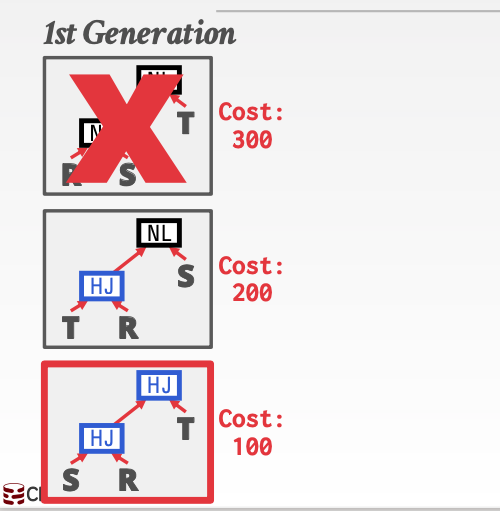
这里300花费最多。所以直接淘汰
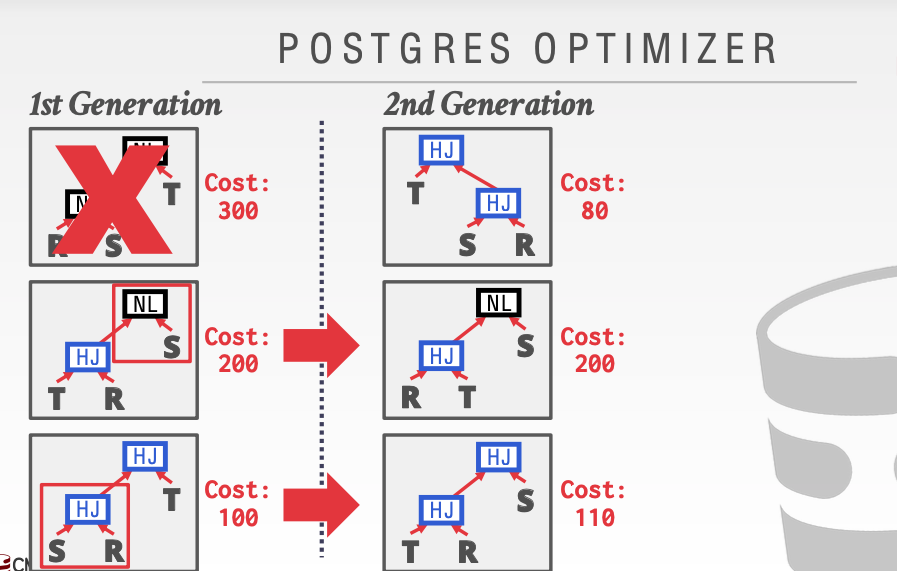
然后对于剩下的两种情况。把所有语法树重构的情况列举出来
6.Others
DBMS将where子句中的嵌套子查询视为获取参数并返回单个值或一组值的函数。
有下面一些简单的方法对于子查询的优化
-
Rewrite
对于下面这个nested的子查询

我们可以把这个sql语句重写

-
DECOMpose Query
对于下面这个例子
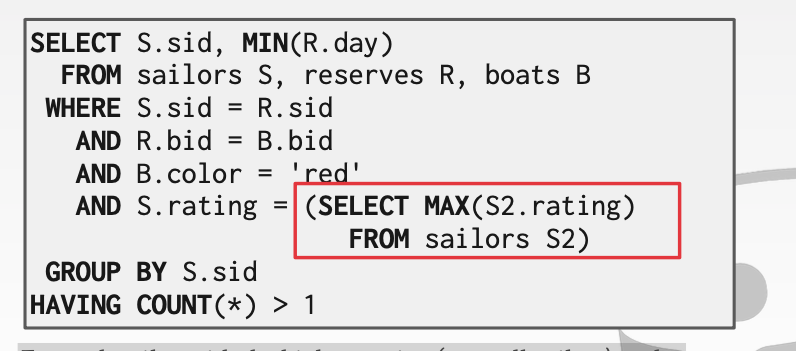
我们可以先执行对于标记为红色框框的select语句。并且我们知道这条语句整个sql执行过程中都不会发生变化。我们先把他执行完成。并将结果传递到这里。这样就可以省略超级多的sql查询。类比下面的c++代码
for (int i = 0; i < a.size(); ++i) {
xxxxx
}
// 对于上面的代码我们可以做出下面的优化
int size_ = a.size();
for (int i = 0; i < size_; ++i) {
xxxxx
}
//这是因为在整个for语句执行过程中这个size都不会发生变化。如果采取上面的写法,那我们会执行n次a.size()操作。这是非常浪费时间的

