(十二)数据库查询处理之Query Execution(1)
(十二)数据库查询处理之Query Execution(1)
1. 写在前面
- 这一大部分就是为了Lab3做准备的
- 每一个query plan都要实现一个next函数和一个init函数
对于next函数每次调用时,返回一个元组或空标记(如果没有更多元组
2. 迭代模型(ITERATOR MODEL)

对于上面这个图的理解就是获取所有的r.id然后构建hash表

然后在right的关系中获取出所有满足要求的S.ID
这里的evalPred(t)就等价于 S.value > 100
几乎所有的DBMS都是用上面的方法。但是允许我们流水线化的实现
不过一些操作必须是顺序化的如Joins、Order By
3. MATERIALIZATION 模型
一次处理所有输入,然后一次获得它的所有输出。

可以发现这种实现没有了next函数(可以把next理解成一种迭代器)
而是在一个list中放了所有满足要求的输入。然后最后也是获得所有输出
对于OLTP(主要是对数据的增删改)工作负载更好,因为一次访问少量元组。→降低执行/协调开销。→更少的函数调用。
Not good for OLAP(主要是对于大型数据的分析) queries with large intermediate results.
4. VECTORIZATION 模型
和上面模型的区别是这种模型用batch代替了全部

这种方法适合OLAP因为它大大减少了每个运算符的执行次数
5. 对于顺序扫描的优化
DBMS可以访问存储于table中的数据的最简单方法莫过于顺序扫描法
for page in table.pages:
for t in page.tuples:
if (check(t)):
// DO something
很显然这种方法不好。下面来看一些对于这个方法的简单优化
1. Zone MAPS
先维护一些关于这个page 的信息
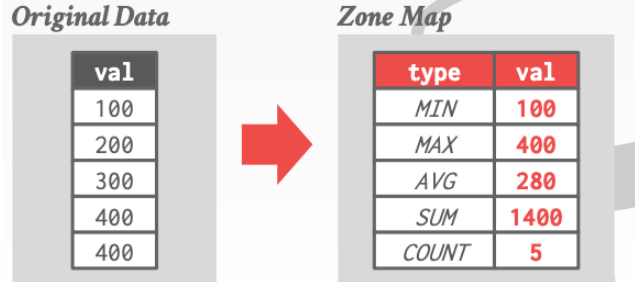
对于这个page那们我们如果要执行
SELECT * FROM TABLE WHERE val > 500
我们就不用访问这个page了因为我们通过Zone Map 知道了这个page里最大的val为400.
2. LATE MATERIALIZATION
DBMS可以延迟拼接元组。到最上层的操作再进行元祖拼接
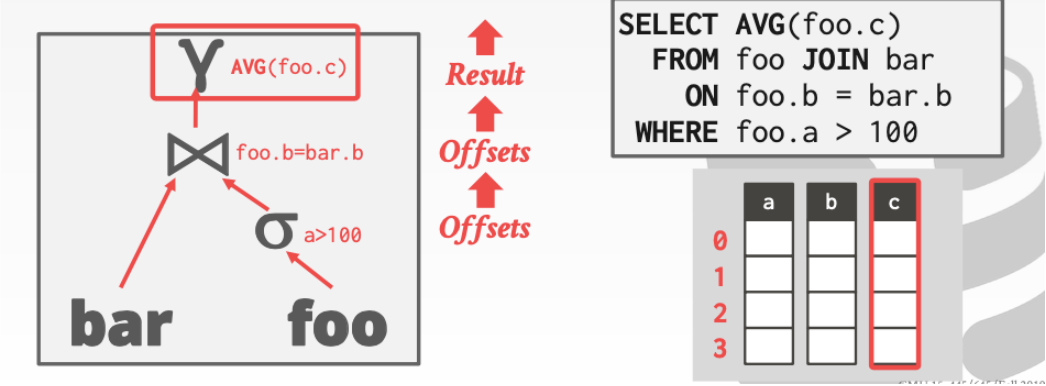
对于上面,这个操作而言我们进行一些分析
- 获取a表中满足要求的行号比如(0 ,1,3)并往上传递
- 获取b中在(0,1,3)行满足要求的行号比如(0,3)然后继续往上传递
- 在最上层元素我们就可以直接在c中的(0,3)行进行AVG操作
3. HEAP CLUSTERING
就是前面说过的聚簇索引。
6. index scan
- 多index scan

这个比较简单对于每一个索引根据条件获取一个集合。然后把集合结合起来最后根据另一个查询条件获得结果
2. INDEX SCAN PAGE SORTING
检索元组在非聚簇索引中是十分低效的
DBMS可以根据page id对于元组进行排序。这样就可以把我们随机访问变成顺序访问

7. EXPRESSION EVALUATION
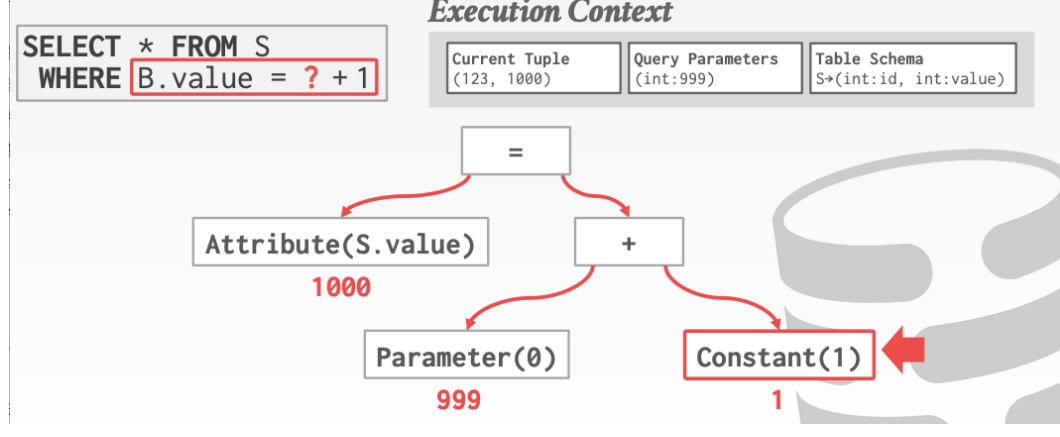
当执行语句发生的时候。我们会有一个Execution Context的东西来保存我们的上下文
上下文中包含
当前元组
执行的参数
Table的Scheme
8.总结
- 相同的query plan 会有不同的执行方法
- 要尽可能多的利用index scan
- 表达式树虽然很直观但是非常慢
