MFiX-DEM中的串行碰撞搜索
在计算颗粒碰撞的时候,需要进行neighbor颗粒的搜寻,只知道大概是基于网格与颗粒绑定的方式,但是具体的实现方式还是比较模糊。搜寻部分代码如下 (mfix-19.2.2):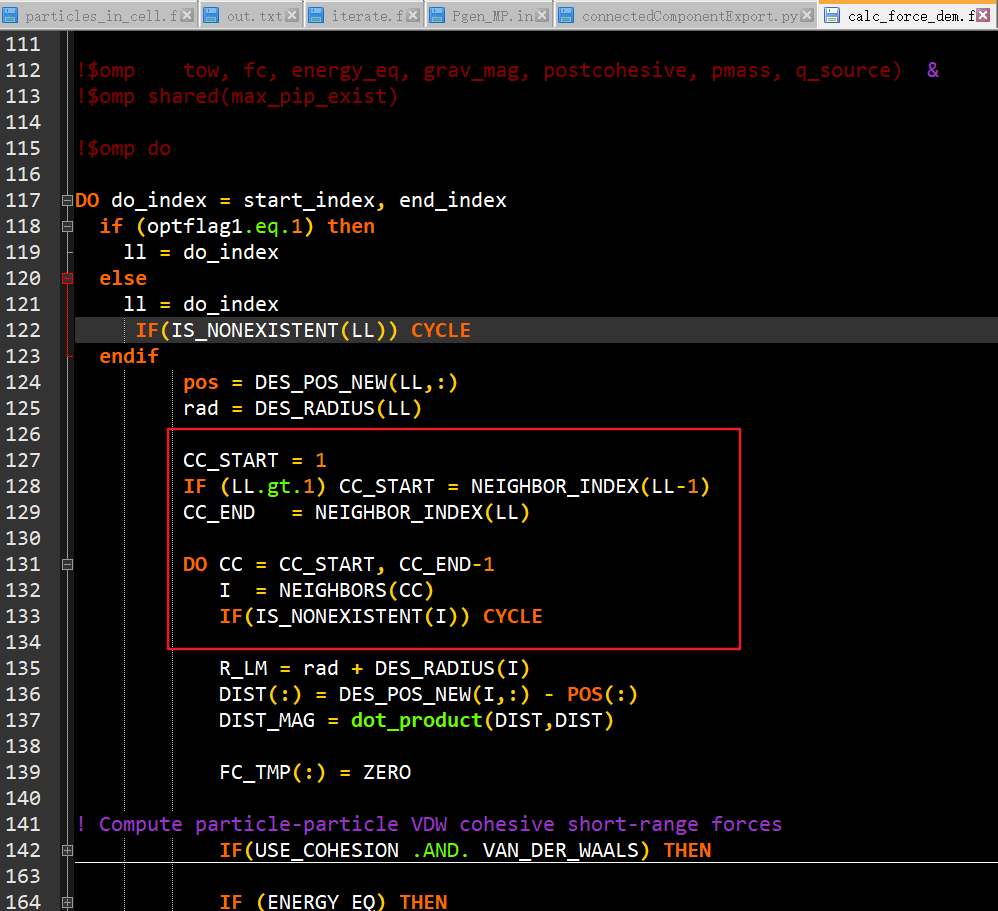
可以直接观察到的是,这里用到了两层do循环,外层循环是遍历所有颗粒的ID,LL,这个ID是每个颗粒的全局标记。内层循环用来遍历颗粒LL周围的颗粒,ID为I。主要问题就在于上图红色方框的内容的含义。
通过借助mfix-16.1版这部分代码debug内容的输出可以大概理解上面的内容。16版代码如下: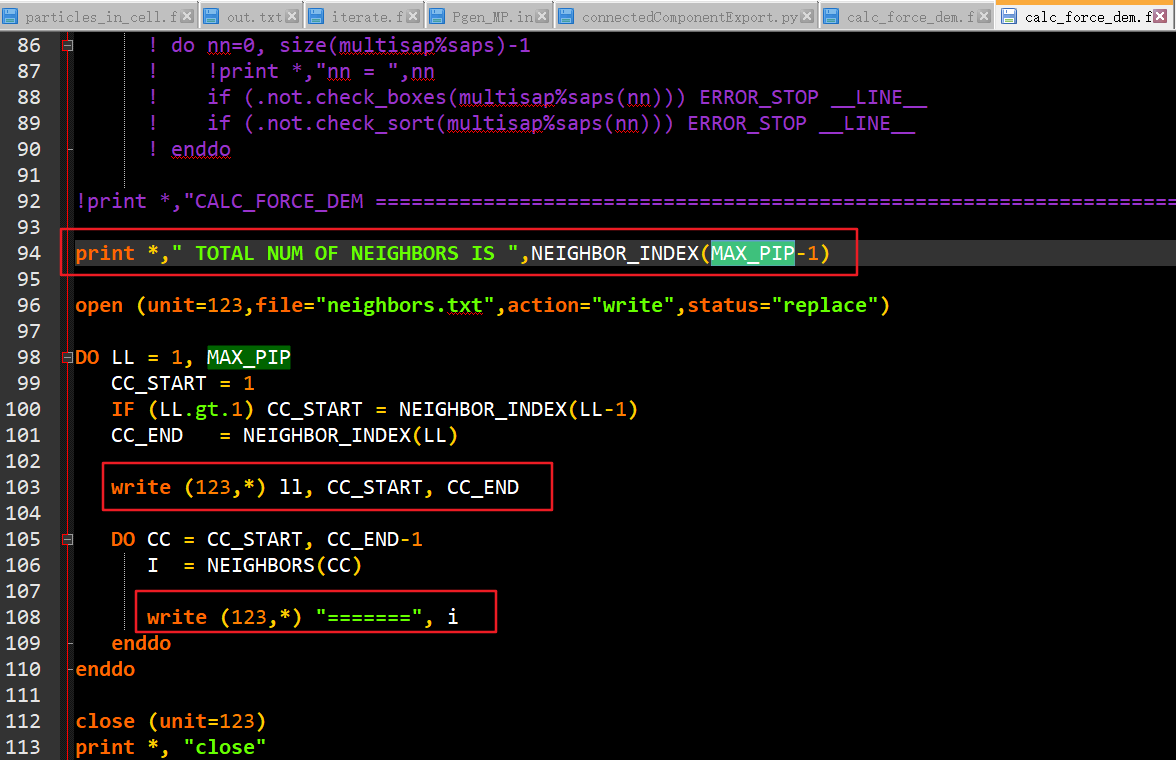
在这里,外层循环输出了三个变量,LL,CC_START,CC_END,内层循环输出了I。输出结果为: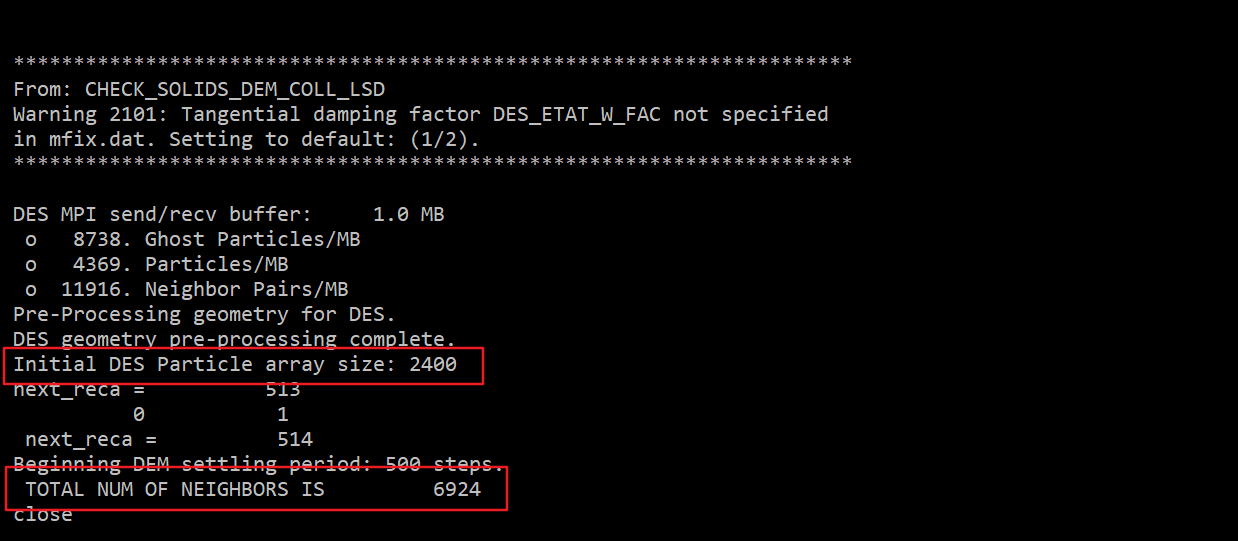
从上面的输出可以看到NEIGHBOR_INDEX(MAX_PIP-1)返回的是总的neighbor数量,从下面的输出可以看出CC_START = NEIGHBOR_INDEX(LL-1)和CC_END = NEIGHBOR_INDEX(LL)分别代表颗粒LL的neighbor遍历区间,下面说明一下这里的逻辑。
通过观察输出最后可以得到结论,首先程序会得到所有neighbor颗粒的数量,然后用数组NEIGHBOR_INDEX(:)来给所有neighbor颗粒编号,例如这个算例中一共有2400个颗粒,neighbor颗粒一共有6924个,因此编号从1~6924。
颗粒LL的neighbor颗粒编号则是从NEIGHBOR_INDEX(LL-1)到NEIGHBOR_INDEX(LL) - 1,这个编号是连续的,然后用这个编号又可以获取到neighbor颗粒的ID,如I = NEIGHBORS(CC)。
需要注意的是,这里在遍历neighbor的时候,没有出现重复计数的情况,用上面的图来举例:
47号颗粒的neighbor编号为75~77(CC = CC_START, CC_END-1),也就是说它有三个neighbor,对应的ID为48,78,79。48号颗粒的neighbor编号为78~80,对应的ID为49,79,80。可以看到48号颗粒的neighbor不再包含47号,因为47号颗粒遍历neighbor的时候已经将48号包含进去了,这样避免了重复循环带来的额外开销。
因此NEIGHBOR_INDEX(MAX_PIP-1)返回的是总的neighbor数量,因为最后一个颗粒MAX_PIP的neighbor编号一定是最大的编号,后面不再有未被遍历的neighbor了,如下图所示: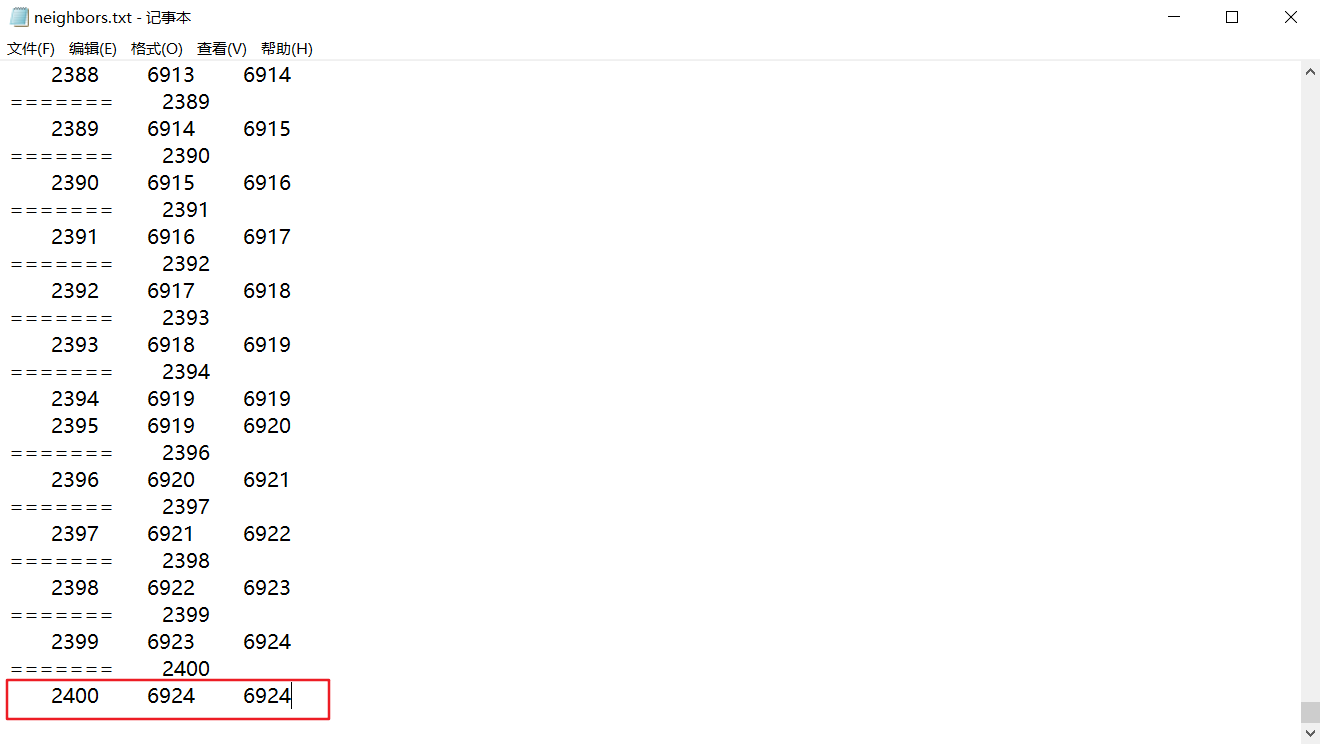
欢迎微信打赏!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号