
CacheAsidePattern和延时双删
一、为什么不直接更新缓存?
无论写数据库和写缓存,哪个操作在前,都不要更新缓存;
因为更新数据库和更新缓存是两个独立的阶段,并发场景下不同线程的两个阶段,可能发生交叉,最终导致数据库和缓存长时间不一致,这种长时间的不一致是不能容忍的。
不一致时长:缓存过期时间,或下一次更新。
二、如何理解Cache Aside Pattern?
这是一种公认的经典缓存一致性处理模式,采用先写库,再删缓存的操作。这种无锁的方案,只能保证并发的前提下,尽可能的降低不一致的概率。这也是AP策略下的一种BASE方案
- 理想状态:因为并发场景下,这两个阶段之间其他线程会读到旧的缓存数据,但经过这个极短的间隙后,最终会再次一致。
不一致时长:写数据库后删除缓存前。
- 读卡顿问题:极端一点,在三个以上并发时,两写一读:
1.线程1完成了写数据库和删缓存;
2.此时由于缓存被删除,线程2只能读数据库,读完后写入缓存前,线程2卡顿了。
3.线程3又完成了一次写和删。
4.线程2才将其从数据库读到的数据写入缓存
5.此时缓存和数据库就不一致了。
不一致时长:缓存过期时间,或下一次更新。
三、延时双删策略解决了哪些极端场景下的数据不一致问题?
针对读卡顿问题,在Cache Aside Pattern的基础上,延时地再删一次缓存,能有效的缩短缓存不一致时长。
可以采用MQ延时消息,或其他异步手段来触发删除缓存动作。
延时的时长设定,通常1、2秒就能覆盖绝大多数场景。
不一致时长:延时时长。
四、注意
-
即便用【Cache Aside Pattern + 延时双删】这种组合,仍不能保证100%的缓存一致性。
-
但通常,使用缓存的场景本身就不要求强一致性。
-
实在要保证缓存和数据库的强一致性,最好的办法就是分布式锁,但是并发性能较差,除非场景要求强一致性,且能容忍较低的并发性才用锁。
五、读操作(分布式锁方案)
这里着重展示一次读操作,对缓存和数据库的访问过程,重点是使用分布式锁合重试机制,以应对高并发下,防止缓存击穿,达到保护数据库的目的。
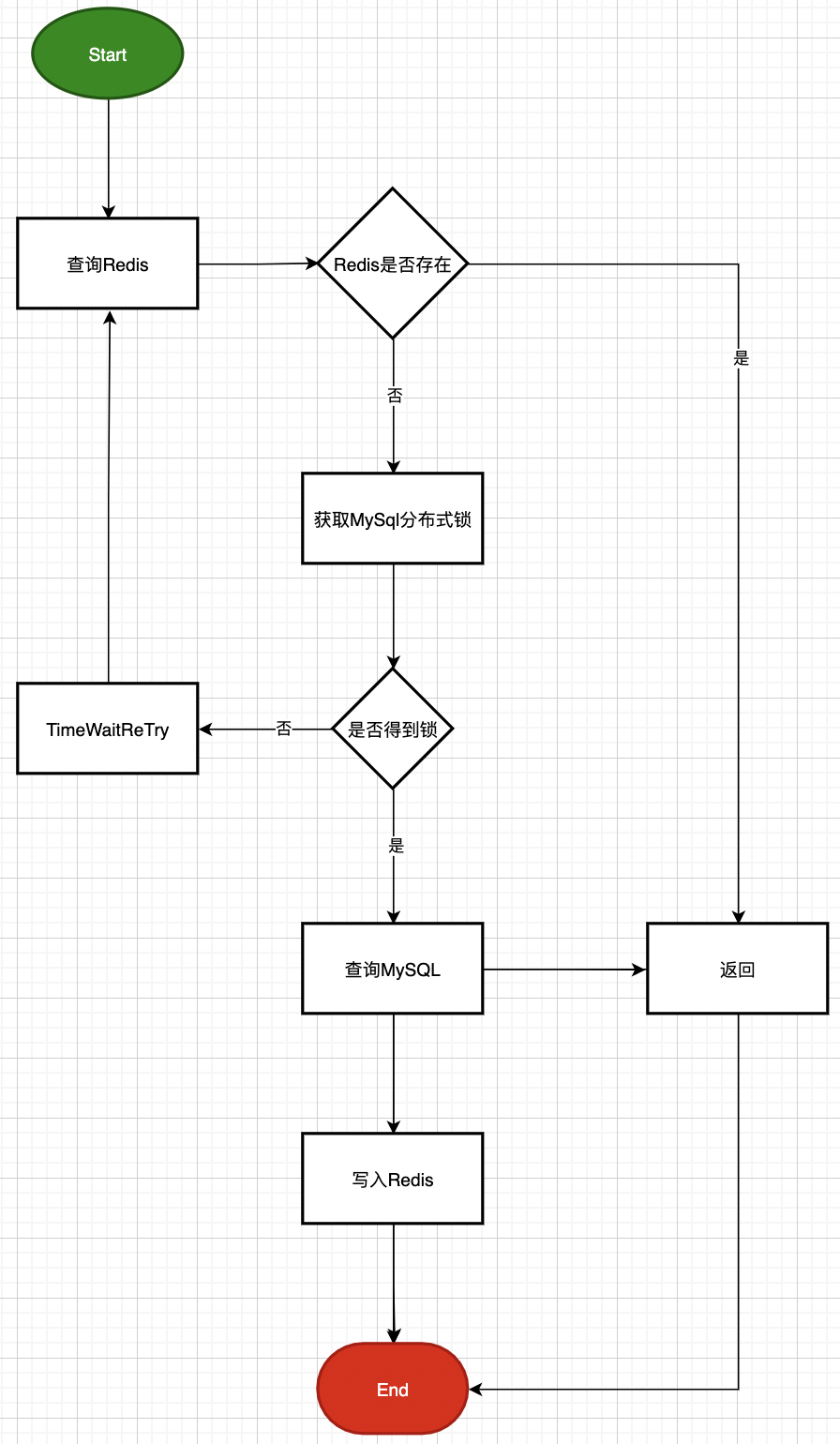
学习使我充实,分享给我快乐!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· Vue3状态管理终极指南:Pinia保姆级教程