Microsoft Azure Machine Learning Studio
随着机器学习(ML)成为软件行业的主流,重要的是要了解它的工作原理,并将其置于开发栈中。了解如何为您的应用程序构建ML服务,您可以确定您的ML应用程序中的机会,实施ML,并与您的团队的ML专业人士清楚沟通。
在整个系列中,我们将构建一个基于信用记录预测贷款审批的ML服务,创建一个Web服务,并从各种平台使用Web服务。通过这个过程,我们将了解有关构建自定义ML服务的ML工具Microsoft Azure ML Studio。对于系列的第一部分,我们将重点介绍如何构建培训实验,了解Azure ML studio的基础知识,并体验构建预测模型的过程。
我们开始讨论ML与应用程序堆栈的关系。
如果您想了解机器学习的一些核心概念,请查看我之前的文章“ 什么是机器学习”。
大图
现代应用程序架构通常由多层组成。在基本级别,这些分离位于服务器和客户端应用程序代码之间。服务器代码可以分为附加功能或服务。Azure ML通过Web服务为应用程序提供额外的服务。
Azure ML服务是可以由各种设备和平台使用的REST API和JSON格式的消息。这些Web服务通过专用API密钥进行安全保护,从而将这些服务暴露给某些客户端,要求服务器层在客户端之间进行调解。此外,一些应用程序可能需要在客户端和服务之间运行的其他进程,验证或身份验证。
学习全堆栈
了解ML在应用程序中的作用可能对完整的堆栈开发人员有好处。术语所指的全堆栈开发人员通常负责构建各种应用程序服务。虽然使用Azure ML的开发与编写代码不同,开发人员将会发现熟悉的用于编写SQL和R代码的概念和工具。
学习Azure ML服务的结构将为开发人员提供与开发团队沟通的基础。如果所有参与者了解系统,其输入和输出以及平台使用的术语,都有机会提高使用ML构建的服务质量。在ML层进行的设计决策可以将整个应用程序全部影响到用户界面。
培训实验基础
使用Azure ML是一个非常结构化的过程。我们将首先收集和分析将用于训练预测模型的数据。接下来,数据必须清除所有异常,丢失数据点和异常值。
一旦准备好数据,我们会将数据分成几组进行培训和测试。训练数据由机器学习算法使用以创建针对测试数据验证的预测模型。模型完成后,我们可以创建一个预测模型,并生成用于处理数据的Web端点。

要开始使用Azure ML studio创建新的实验,请单击,new然后从菜单中选择实验,空白实验。一旦创建了新的实验,将显示一个空的实验大纲,显示实验的基本工作流程。

所示的轮廓是构建模型流程如何的表示。
在整个过程中,我们将从左侧的实验项目中拖动模块,并将它们放入右侧的实验工作表面。然后将每个模块连接到其他模块的输入和输出,以执行以下任务:数据清理/转换,选择机器学习算法,模型评分和Web端点。运行每个模块后,可以通过右键单击模块并从菜单中选择可视化来显示输出。
准备数据
该过程首先分析和清理大量数据。ML依靠大量数据进行分析,以识别模式,更多的数据将产生更好的结果。了解数据很重要,数据点是生成良好预测模型的关键因素。这可能需要与应用程序所在领域的专家进行合作。
应准备数据,以便维护相关数据点,并从数据集中删除无效或丢失的数据。一旦准备好数据,就可以选择机器学习算法进行训练。
导入数据
我们开始将数据导入实验。对于以下示例,我们将使用由超过100,000个贷款记录组成的数据集。我们将使用贷款数据来预测未来贷款的违法。
要导入数据,我们将使用导入数据模块。该模块将简单地从目标数据源检索数据并将其加载到实验中。通过通过HTTP设置数据源的Web网址,数据会从网上下载。在这种情况下,我们将选择CSV格式,并指定该文件有一个头。运行实验将导入数据。

贷款资料分析
我们通过右键单击导入数据模块并从菜单中选择可视化来分析数据。在实验中右键单击任何模块将允许我们查看模块的输出。对于导入数据模块,我们可以可视化数据并了解每个数据列的各个方面,如:平均值,中值,最小值,最大值和唯一值和缺失值的数量。每个数据点还显示一个直方图,可以帮助我们发现趋势数据和识别异常值。

首先突出显示“贷款统计”列。此列将贷款确定为“已收费”和“全额付款”。这些值代表贷款的二进制结果,其中“收费”是不期望的结果,“完全支付”是理想的结果。在银行业务中,这些术语意味着银行被扣除贷款,可能会损失收入,或贷款全额支付,银行赚取收入。这一列最终将成为我们试图预测的价值。
我们需要检查每一列的统计信息以识别问题,以便可以从数据集中清除。在这个数据集中,我们会发现以下问题:
- 信用评分:信用评分栏中的项目的值超过正常信用评级0-850。这些值在最右边的数字中有一个额外的零。例如,值为7330,但应为733。
- 当前贷款金额:一些价值似乎最大到99999999,这不是一个现实的贷款价值。这些记录需要清理。
- 住房所有权:存在重要的描述为有偿和家庭抵押贷款。这些值可以合并为“住房抵押”。
- 目的:重复的描述存在于其他和其他。这些可以组合为“其他”。
- 破产和税务优先权:这些列具有
NA字符串值,应将其转换为0,允许将列格式化为整数。 - 当前工作年数:此列包含“n / a”值。这些可以分为现有的“<1年”值。
数据操作
要纠正我们的数据问题,我们将使用SQL查询。还有其他方法可以处理诸如R脚本和离散数据修改模块之类的数据,我们将在下面看看。SQL是最全面的堆栈开发人员友好的选项,所以我们从头开始。
以下SQL脚本将更正以前观察到的问题。此外,脚本将每个值转换为适当的数据类型。
SELECT
[Loan ID],
[Customer ID],
[Loan Status],
CAST(REPLACE([Current Loan Amount],'99999999',0) AS INT) AS [Loan Amount],
[Term],
CAST(SUBSTR([Credit Score],1,3) AS INT) AS [Credit Score] /* Clean outlier values of credit score */,
REPLACE([Years in current job],'n/a','< 1 year') AS [Years in Current Job] /* Clean n/a values in Years in current job */,
REPLACE([Home Ownership], 'HaveMortgage', 'Home Mortgage') AS [Home Ownership] /* combine home ownership: 'HaveMortgage' and 'Home Mortgage' */,
CAST([Annual Income] AS BIGINT) AS [Annual Income],
Replace([Purpose], 'other', 'Other') AS [Purpose] /* # combine Purpose: 'other' and 'Other' */,
CAST([Monthly Debt] AS FLOAT) AS [Monthly Debt],
CAST([Years of Credit History] AS FLOAT) AS [Years of Credit History],
CAST(REPLACE([Months since last delinquent],'NA','') AS INT) AS [Months Since Last Delinquent],
CAST([Number of Open Accounts] AS INT) AS [Number of Open Accounts],
CAST([Number of Credit Problems] AS INT) AS [Number of Credit Problems],
CAST([Current Credit Balance] AS BIGINT) AS [Current Credit Balance],
CAST([Maximum Open Credit] AS BIGINT) AS [Maximum Open Credit],
CAST(REPLACE([Bankruptcies],'NA','') AS INT) AS [Bankruptcies],
CAST(REPLACE([Tax Liens],'NA','') AS INT) AS [Tax Liens]
FROM t1;
缺失数据
随着数据转换,我们仍然有一些丢失数据的问题。我们将通过填写丢失的数据或从集合中删除数据来解决丢失的数据。要应用这些转换,我们将使用“转换为数据集”和“清除缺失数据”模块。
让我们从使用“SetMissingValues”操作的“转换为数据集”模块填充缺少的值开始。该模块将使用占位符标记任何缺失值,在这种情况下,我们将替换为0。

接下来,我们将使用“Missing Data”模块清理缺少的值。缺少数据模块指定如何处理数据集中丢失的值。我们将使用多个模块来处理以下每个场景:
-
贷款金额:由于此列中存在大量数据,因此我们可以使用统计算法尝试估算数据。在这种情况下,我们将使用缺少数据模块的“使用MICE”替换清洁模式。对于每个缺失值,此选项分配一个新值,该值通过使用统计文献中描述的方法计算,作为使用链接方程或链接方程的多重插补的多变量插值。
-
信用评分和年收入:在大多数情况下,信用评分和年收入都在同一行中丢失。最好将它们完全从数据集中删除。我们将为这些项目应用“删除整行”清除模式。顾名思义,信用评分和年收入中缺少值的行将被删除。
-
所有其他人:借助贷款金额,信用评分和年度收入缺失值解决,我们将剩余的任何数据标记为零。再次,我们将使用缺少数据模块,在这种情况下,我们将使用设置值的“自定义替换值”清除模式
0。
我们已经学习了使用Azure ML Studio清理数据的一些基本模块,还有更多的模块,我们没有覆盖。清理数据是在过程中了解的重要步骤,因为数据是我们依赖于我们的模型的基础。请记住,即使在实验的培训阶段给出了完美的数据集,该清理和数据操作模块也可用于从Web端点接收的数据,以及过滤来自用户或应用程序的数据。
建立模型
训练机器学习算法对数据的结果是一个模型。为了生成一个模型,我们需要创建两组准备好的数据,训练数据和测试数据。这样可以根据测试数据对模型进行训练和验证。该过程产生一个分数,这将有助于确定模型的准确性。模型的期望精度取决于应用程序及其如何使用。
培训模型在某些方面与在计算机编程中创建单元测试类似,因为模型根据已知的测试数据进行验证。然而,不是断言一个简单的通过或失败的结果,返回0到1之间的概率。评分模型评估测试数据的许多结果,并提供模型精度的其他指标。
我们使用Azure ML“拆分数据”模块拆分数据。该模块将帮助我们将数据分为培训和测试数据。使用“第一个输出数据集中的行分数”选项,我们可以决定将多少数据用于培训或测试。在我们的例子中,我们将把这个数值设置为将0.770%的数据提供给培训。

选择算法
Azure ML具有来自回归,分类,聚类和异常检测系列的大型算法库。每个设计用于解决特定类型的机器学习问题。为了协助这个过程,Microsoft已经提供了一个备忘单,帮助您为预测分析解决方案选择最佳的Azure ML算法。您选择的算法主要取决于您的数据的性质和您想要回答的问题。
对于我们的贷款审批数据,我们将使用两级升级决策树模块。增强的决策树是良好的通用机器学习算法,对于我们的数据集将很好地工作。值得注意的是,决策树是内存密集型学习者,可能无法处理非常大的数据集。
我们将通过将“分割数据”模块的第一个输出连接到列车模块的第二个输入,为实验添加“火车模型”模块。接下来,我们需要确定标签列,这是包含我们想要对模型进行预测的结果的列。对于我们的贷款数据,这是贷款状态。

为了利用“两级升压决策树”,我们将添加模块并将其输出连接到列车模型模块的第一个输入。这完成了模型的训练部分,接下来我们需要评估和评估模型。
得分与迭代
要完成培训实验,我们需要对我们的模型进行评分。一旦创建了第一个模型,分数将确定模型的有效性,并可能揭示需要解决的问题。丢失或无效的数据点可能会通过准确度谱线极端的分数显示出来。即使看起来正常的分数也可能受益于额外的改进,以提高其准确性。使用不同的参数和使用数据问题来对您的模型进行实验是找到正确模型的过程的一部分。
我们为实验添加一个“分数模型”模块。我们将从我们训练的模型的输出到第一个输入,以及从“分割数据”模块到第二个输入的验证数据。这将创建一个包含列的计分数据集scored probabilities。
得分概率表明相应条目属于Charged Off或Fully Paid类的概率。如果输入的得分概率大于0.5,则被预测为Fully Paid。否则,预测为Charged Off。要查看这些结果,我们可以右键单击该模块,然后从菜单中选择“可视化”。
最后,我们将使用“评估模型”模块评估模型。该模块将提供模型执行情况的统计分析。二进制分类模型的评估指标有:精度,精度,召回,F1分数和AUC。此外,模块输出一个混淆矩阵,显示真阳性,假阴性,假阳性和真阴性数以及ROC,精度/回归和提升曲线。
一旦Evaluate Model模块连接到Score Model模块的输出,运行实验并将Evaluate Model模块的输出可视化。

对于本文的范围,我们将研究曲线下的准确度和面积(AUC)来了解我们的模型的有效性。评估结果表明,该模型的准确度为0.779或77.9%。确定您的模型的准确性是否足够取决于您的业务需求。例如,我们的模型确定客户是否符合银行贷款资格。对于这种情况,准确度分数为79%可能是正确的,但是如果您的模型预测一种药物是否在患者中有效,则准确性可能需要更高。
接下来我们来看一下AUC。AUC对应于受试者操作特征(ROC)曲线,其包括真阳性率与假阳性率。这个曲线越靠近左上角,分类器的表现越好,这意味着我们有更高的真实阳性率和更低的假阳性率。

如果我们确定分数不足以满足我们的需求,我们会遍历清理数据,调整或选择替代学习算法的过程,并比较以前模型的分数。对于我们的方案,我们将考虑过程完成。我们的模型能够采取客户贷款数据的各种因素,并为个人贷款的风险提供合理的预测。通过模型完成,我们可以通过设置Web服务来继续该过程,以使应用程序能够利用预测模型。
1、新建workspace
注意,在填写workspace owner,一定要填写一个有效的windows live 账号

进入创建的workspace,界面如下图所示

2、上传数据
数据源:http://archive.ics.uci.edu/ml/datasets/Statlog+(German+Credit+Data)
下载名为german.data,该数据用于信用风险的机器学习算法,数据包括20个变量,1000条信用记录,其中700条问低风险,300条为高风险。注意,由于Azure Machine Learning stidio 只支持csv文件,所以需要把german.data转化为csv文件。
点击ML studio下方的"+new"链接,按下图所示将数据已建立好workspace中

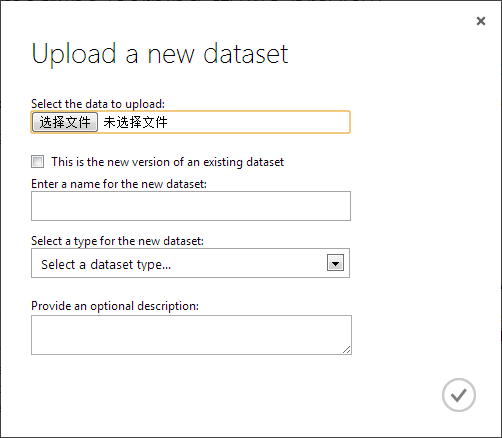
3、新建Azure ML的实验
点击ML studio下方的"+new"链接,选择Experiment选项,打开如下界面后

第一步,可以给这个实验添加一个标题,本文命名为"Experiment by Jiahua"
第二步,在左侧找到上传的数据,名字为上传数据是给定的数据名字,本文为"UCI German Credit Card Data",将数据拖到中间的工作区,然后右侧会给出数据的描述信息。数据进入工作区之后,用一个圆角的矩形表示,矩形下有一个圆圈,称为"output port",将鼠标放在上面并点击右键后,可以进行数据可视化等操作。拖动圆圈,可以指向下一个数据处理操作。
第三步,添加完数据集之后,就需要对数据集进行相应的处理,包括数据预处理,训练样本和测试样本划分,选择机器学习算法等等,详细操作课参加官方实例。完成上述操作后,一个可视化的机器学习过程就完成,如下图所示:

第四步,模型运行。完成上述操作后,就就可以运行程序了,点击下方的"Run",模型就会运行,每个模块运行完成之后会在右上方标示一个绿色小勾,如果每个模块或步骤出错了,会在同样的地方出现一个红色的 ,鼠标放上去之后就会提示错误的类型。
,鼠标放上去之后就会提示错误的类型。
第五步,查看结果,在"Evaluate Model"方框下的圆点处点击右键,选择"Visualize"即可查看模型运行结果,部分结果如下图所示:

https://studio.azureml.net/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号