
SQL Server批量插入单个文件夹中的多个CSV文件
问题
您是否曾经想过将具有相似数据结构的大量CSV文件快速聚合到SQL Server数据库的主数据集中?AWS提供了一个名为Athena的服务,可以完成此任务,并且有许多Microsoft产品和脚本语言可以完成此任务,但是今天,我们探讨如何在纯T-SQL中完成该任务。
解
我们将研究如何使用BULK INSERT和一些系统存储过程来处理和导入文件夹中的所有文件。
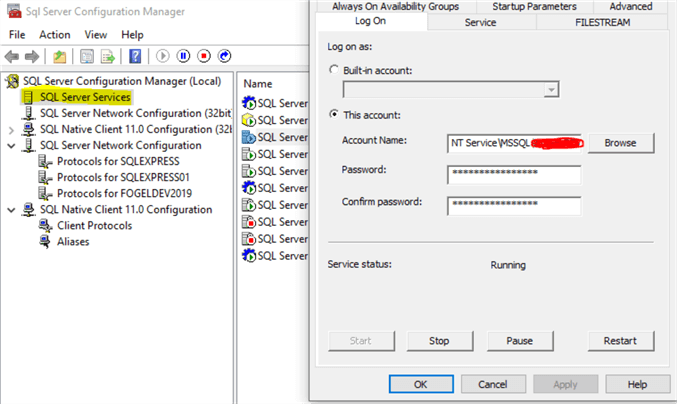
步骤1 –检查服务帐户权限
另外,请确保您的SQL Server服务帐户有权访问您尝试从中加载的驱动器和文件夹。如果不确定服务帐户的名称,可以通过打开相应版本的SQL Server配置管理器>> SQL Server服务并查看帐户名称来进行检查:
第2步-预览CSV文件
这是我们的工作目录,我们有两个带有单个列的csv文件1.csv和2.csv。

1.csv

2.csv
我们的目标是将所有.csv文件放入目录中,并将每个CSV文件中的数据动态批量插入SQL Server临时表中。为了找到目录中的文件,我们将使用xp_DirTree系统存储过程,该存储过程将返回目录中每个文件的名称,然后将这些结果加载到临时表中。
步骤3-为文件名创建临时表结构
下面,我们将获取文件夹“ C:\ Test \”中的所有文件。
IF OBJECT_ID('TEMPDB..#TEMP_FILES') IS NOT NULL DROP TABLE #TEMP_FILES CREATE TABLE #TEMP_FILES ( FileName VARCHAR(MAX), DEPTH VARCHAR(MAX), [FILE] VARCHAR(MAX) ) INSERT INTO #TEMP_FILES EXEC master.dbo.xp_DirTree 'C:\Test\',1,1
然后我们从该临时表中删除文件扩展名不是.csv的文件。
DELETE FROM #TEMP_FILES WHERE RIGHT(FileName,4) != '.CSV'
第4步-创建结果表并插入数据
接下来,我们构造另一个临时表,该表具有与要加载的csv文件相同的架构。在这种情况下,它是单列“ A”。
现在,我们遍历第一个临时表中的其余记录,这些记录应该是我们试图从中加载数据的.csv文件名。我们在while循环的每个迭代中分配一个文件名变量,以选择文件名并将其传递给动态SQL变量,然后执行它。
IF OBJECT_ID('TEMPDB..#TEMP_RESULTS') IS NOT NULL DROP TABLE #TMP CREATE TABLE #TEMP_RESULTS ( [A] VARCHAR(MAX) ) DECLARE @FILENAME VARCHAR(MAX),@SQL VARCHAR(MAX) WHILE EXISTS(SELECT * FROM #TEMP_FILES) BEGIN SET @FILENAME = (SELECT TOP 1 FileName FROM #TEMP_FILES) SET @SQL = 'BULK INSERT #TEMP_RESULTS FROM ''C:\Test\' + @FILENAME +''' WITH (FIRSTROW = 2, FIELDTERMINATOR = '','', ROWTERMINATOR = ''\n'');' PRINT @SQL EXEC(@SQL) DELETE FROM #TEMP_FILES WHERE FileName = @FILENAME END
执行完成后,来自1.csv和2.csv的所有数据都在我们的#temp_results表中。
SELECT * FROM #TEMP_RESULTS
第5步-使用try catch块改进插入过程
该策略可以是一种将数据加载到SQL Server数据库中的廉价且简便的方法。您可以编写脚本以运行该脚本,并每晚检查一次是否有新文件,并将结果集附加到生产数据中。任何分隔形式的大容量插入都需要记住的数据可能会破坏插入。即使第一个文件失败,try catch语句也会为每个文件提供处理的机会。
WHILE EXISTS(SELECT * FROM #TEMP_FILES) BEGIN BEGIN TRY SET @FILENAME = (SELECT TOP 1 FileName FROM #TEMP_FILES) SET @SQL = 'BULK INSERT #TEMP_RESULTS FROM ''C:\Test\' + @FILENAME +''' WITH (FIRSTROW = 2, FIELDTERMINATOR = '','', ROWTERMINATOR = ''\n'');' PRINT @SQL EXEC(@SQL) END TRY BEGIN CATCH PRINT 'Failed processing : ' + @FILENAME END CATCH DELETE FROM #TEMP_FILES WHERE FileName = @FILENAME END
步骤6-一个更复杂的示例
让我们将我们创建的逻辑应用于更复杂的数据集。
在这3个csv文件中,我们具有3条独立街道的房屋数据,这些街道涉及平方英尺,卧室和浴室的数量以及一个车库指示器字段。这次我们将更改脚本的目录,它将更新为C:\ Test \ Houses。



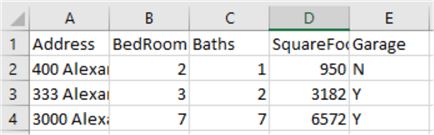
这是此示例的代码。
IF OBJECT_ID('TEMPDB..#TEMP_FILES') IS NOT NULL DROP TABLE #TEMP_FILES CREATE TABLE #TEMP_FILES ( FileName VARCHAR(MAX), DEPTH VARCHAR(MAX), [FILE] VARCHAR(MAX) ) INSERT INTO #TEMP_FILES EXEC master.dbo.xp_DirTree 'C:\Test\Houses\',1,1 DECLARE @FILENAME VARCHAR(MAX),@SQL VARCHAR(MAX) IF OBJECT_ID('TEMPDB..#TEMP_RESULTS') IS NOT NULL DROP TABLE #TEMP_RESULTS CREATE TABLE #TEMP_RESULTS ( [Address] VARCHAR(MAX), [BedRoom] VARCHAR(MAX), [Baths] VARCHAR(MAX), [SquareFootage] VARCHAR(MAX), [Garage] VARCHAR(MAX) ) WHILE EXISTS(SELECT * FROM #TEMP_FILES) BEGIN BEGIN TRY SET @FILENAME = (SELECT TOP 1 FileName FROM #TEMP_FILES) SET @SQL = 'BULK INSERT #TEMP_RESULTS FROM ''C:\Test\Houses\' + @FILENAME +''' WITH (FIRSTROW = 2, FIELDTERMINATOR = '','', ROWTERMINATOR = ''\n'');' PRINT @SQL EXEC(@SQL) END TRY BEGIN CATCH PRINT 'Failed processing : ' + @FILENAME END CATCH DELETE FROM #TEMP_FILES WHERE FileName = @FILENAME END
我们可以看看作为原始VARCHAR(MAX)数据类型加载的数据。
--ORIGINAL DATA TYPES
SELECT * FROM #TEMP_RESULTS
我们还可以将数据类型类型转换为对该数据集更有意义的类型。
--DATA CAST AFTER LOAD SELECT [Address], CAST(BEDROOM AS INT) AS BedRooms, CAST(BATHS AS Decimal(3,2)) AS BathRooms, CAST(SQUAREFOOTAGE AS INT) As SquareFootage, CAST(CASE WHEN GARAGE = 'Y' THEN 1 ELSE 0 END AS BIT) as GarageIndicator FROM #TEMP_RESULTS
最后,为避免重新处理在运行此过程的两个单独目录中可能存在的文件,请创建一个PreviouslyProcessed表,并在while循环中选择排除该名称的文件名。
IF OBJECT_ID('TEMPDB..#TEMP_FILES') IS NOT NULL DROP TABLE #TEMP_FILES CREATE TABLE #TEMP_FILES ( FileName VARCHAR(MAX), DEPTH VARCHAR(MAX), [FILE] VARCHAR(MAX) ) --CREATE A TABLE FOR LOGGING PROCESSED RECORDS. IF OBJECT_ID('dbo.PreviouslyProcessed') IS NOT NULL DROP TABLE PreviouslyProcessed CREATE TABLE PreviouslyProcessed ( FileName VARCHAR(MAX) ) insert into PreviouslyProcessed values('Budapest_Ln.csv') INSERT INTO #TEMP_FILES EXEC master.dbo.xp_DirTree 'C:\Test\Houses',1,1 DECLARE @FILENAME VARCHAR(MAX),@SQL VARCHAR(MAX) IF OBJECT_ID('TEMPDB..#TEMP_RESULTS') IS NOT NULL DROP TABLE #TEMP_RESULTS CREATE TABLE #TEMP_RESULTS ( [Address] VARCHAR(MAX), [BedRoom] VARCHAR(MAX), [Baths] VARCHAR(MAX), [SquareFootage] VARCHAR(MAX), [Garage] VARCHAR(MAX) ) WHILE EXISTS(SELECT * FROM #TEMP_FILES WHERE FILENAME NOT IN(SELECT FILENAME FROM PreviouslyProcessed)) --AVOID PROCESSING FILES ALREADY PROCESSED BEGIN SET @FILENAME = (SELECT TOP 1 FileName FROM #TEMP_FILES WHERE FILENAME NOT IN(SELECT FILENAME FROM PreviouslyProcessed)) SET @SQL = 'BULK INSERT #TEMP_RESULTS FROM ''C:\Test\Houses\' + @FILENAME +''' WITH (FIRSTROW = 2, FIELDTERMINATOR = '','', ROWTERMINATOR = ''\n'');' PRINT @SQL EXEC(@SQL) DELETE FROM #TEMP_FILES WHERE FileName = @FILENAME INSERT INTO dbo.PreviouslyProcessed VALUES(@FILENAME) END

 浙公网安备 33010602011771号
浙公网安备 33010602011771号