【转】 SpringCloudAlibaba--05——nacos
【转】 SpringCloudAlibaba--05——nacos
参考地址:蚂蚁课堂
上一集的Nacos 的集群方式存在很大的问题,还不算真正的集群,是3 份一样的配置数据,存在很大的冗余。
注意:Nacos 在不同的版本下运行集群式不一样的。
1、在Linux 下默认走的是集群模式,如果需要改为单机模式的集群,需要修改配置,(可以查看Nacos的 \bin目录下的statup.sh 的配置)
2、在Windows下默认走的是单机集群模式,如果需要改为集群模式,需要修改配置,(可以查看Nacos的 \bin目录下的statup.cmd 的配置)
设置集群:
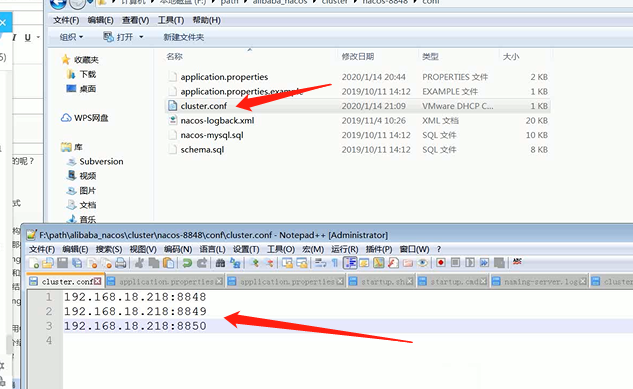
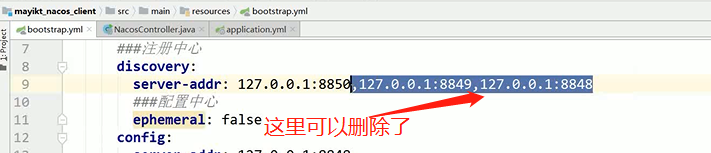
只需要注册到其中一个就可以了,它内部会自己去实现一个数据同步一致性的算法。(Raft协议)
CAP定律
这个定理的内容是指的是在一个分布式系统中、Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼。
一致性(C):在分布式系统中,如果服务器集群,每个节点在同时刻访问必须要保持数据的一致性。
可用性(A):集群节点中,部分节点出现故障后任然可以使用 (高可用)
分区容错性(P):在分布式系统中网络会存在脑裂的问题,部分Server与整个集群失去节点联系,无法组成一个群体。
只有在CP和AP选择一个平衡点
* Eureka 和 Zookeeper 区别
Zookeeper: 采用CP 保证数据一致性问题,采用Zab 原理广播协议,当zk 的主节点宕机,会重新选举一个新的主机点,但是,在选举过程中,为了保证数据一致性,整个zk 是不能使用的。所以就意味着,在微服务模式下,可能会无法实现通讯。(除非本地有缓存)注意:zk 的可运行节点必须满足过半的情况下,整个zk 才可以使用。
Eureka:采用的是AP 完全 去中心化思想,(中心化:必须围绕一个主节点作为核心;去中心化:每个节点都是均等的)也就是没有主从之分,每个节点都是均等的,采用相互注册原理,只要有一个eureka 节点存在,就可以保证整个微服务实现通讯。
* Nacos 和 Eureka 区别
Nacos支持两种模式:CP | AP,可以切换,默认使用是AP 模式。CP的形式集群,底层是raft 协议保证数据一致性的问题。所以它是有主从节点关系的。
Eureka 使用的是 去中心化,来保证数据一致性。
* 分布式一致性协议算法 | 分布式一致性框架
分布式一致性算法:应用于系统软件实现集群,保持每个节点数据的同步性和 一致性的问题,专业术语叫 分布式一致性算法。
比如有:raft(nacos的)、zab(zookeeper的)、paxos 等
分布式一致性框架:解决在实际系统中,产生跨事务导致的分布式事务问题,最主要是最终一致性。
比如有:rocketmq事务消息、rabbitmq补单、icn、seata 等
* Zab 协议怎么保持数据的一致性
怎分布式系统,存在多个系统之间集群保持数据一致性,采用CP一致性算法。
Zookeeper 的集群方式是要选举出一个领导者,怎么选举的??找一个节点能力比较强的。
在程序中如何成为节点能力比较强的:对每个节点配置一个myid 或 serverid(数值越大表示能力越强),或者是随机时间
如何保证数据一致性:所有的请求不管到哪个节点,都要必须经过交给领导者节点,领导者写完数据以后,再同步到其他所有节点。中间会发两次通知,第一次是通知到所有节点现在能不能接收,第二次就是发送数据,这时候会判断,只要同意接收的节点过半(大于 n/2 的数量),就直接同步过去了。假设中间同步了一下节点,还有很多没有同步到,这时候领导者突然宕机了,就会在已经同步了新的数据的节点中选举出一个新的领导者角色,因为那些没有同步到的节点数据不是最新的,不会考虑到给领导者角色。这就是Zab协议。
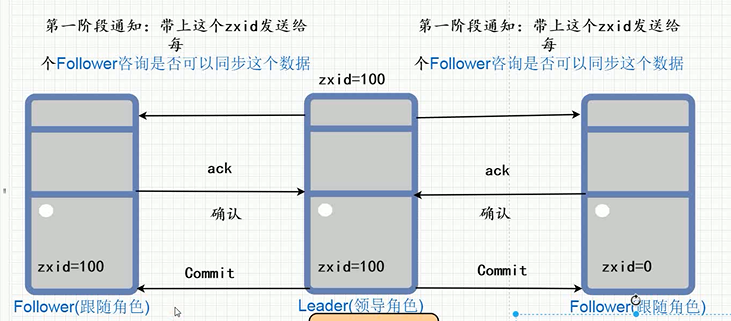
* Raft 协议
Raft 协议选举的概念:
在Raft协议算法中分为角色|名词:
1、3种状态:跟随者、竞选者(候选)、领导角色
2、大多数:大于 n / 2 + 1
3、任期:每次选举一个新的领导角色,任期都会增加(就是第几任的领导者)
Raft选举过程的原理:
细心的人不难发现,在我们创建nacos集群时候,刚开始都是跟随者,然后一闪而过,会有一个领导者角色出现。
选举过程:刚开始默认都是跟随者,每个节点会随机生成一个选举的超时时间,比如大概是100--300ms,在这个超时时间内,必须要等待,
时间最短的选举时间肯定最先醒来,最先醒来的就会变成一个竞选者,这个竞选者会给其他节点发出选举投票的通知,如果其他节点投票数量过半,这个竞选者就变成一个领导者。
Raft协议故障重新选举:
如果最开始的一个竞选者出来以后,给其他节点发出投票通知,这时候其他节点一直没有收到通知,那么竞选者就说明故障了,这时候其他节点会立马出来一个新的竞选者,还是一样根据选举超时时间来出来的竞选者
Raft数据如何保证一致性:
和Zab协议很相似,所有的请求都会经过交给领导者实现,然后根据日志心跳的形式发出同步消息给其他所有节点,只要过半数量的节点同意同步数据,就会同步过去了。这个成为日志复制。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号