【转】 JavaSE学习总结(19)--java8 新特性(二)
1.编译器类型推断提升


public class Value<T> { public static <T> T defaultValue() { return null; } public T getValue(T t1, T t2) { return t1 != null ? t1 : t2; } public static void main(String[] args) { final Value<String> value = new Value<>(); value.getValue("22", /*此处编译器自动会推到出类型如果是java7那么报错*/defaultValue()); } }
注意:切换JDK包括Project Structer中的 SDKS Project Modules以及setting中的Java Compile
2.获取参数名上提供支持
在语言层面(使用反射API和Parameter.getName()方法)和字节码层面(使用新的javac编译器以及-parameters参数)提供支持。
public class ParaNameTest { public static void main(String[] args) throws NoSuchMethodException { Method main = ParaNameTest.class.getMethod("main", String[].class); for (Parameter parameter : main.getParameters()) { System.out.println("parameter:" + parameter.getName()); } } }
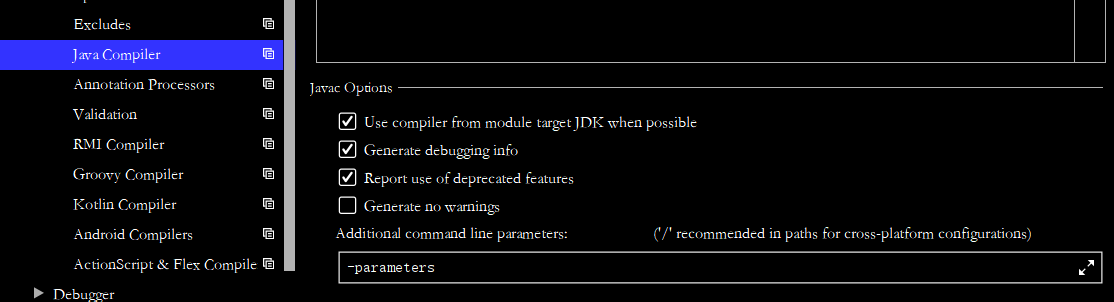
通过设置参数-parameters可以获取正确的获取参数名args如果没有参数会得到arg0
如果你使用Maven进行项目管理,则可以在maven-compiler-plugin编译器的配置项中配置-parameters参数:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<compilerArgument>-parameters</compilerArgument>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>3.接口静态方法和默认方法
增加了default方法(属于接口实现类实例)和static方法(属于接口)
默认方法使得开发者可以在 不破坏二进制兼容性的前提下,往现存接口中添加新的方法,即不强制那些实现了该接口的类也同时实现这个新加的方法。
默认方法和抽象方法之间的区别在于抽象方法需要实现,而默认方法不需要。接口提供的默认方法会被接口的实现类继承或者覆写。具体详情参考官方文档
4.函数式编程-->Lambda表达式
1.lambda表达式可以看成一个特殊匿名内部类
2.只能用于函数式接口
什么是函数式接口?简单地说,接口中若只包含一个抽象方法,则称该接口为函数式接口。可以在接口前使用注解@FunctionalInterface检查该接口是否为函数式接口。
从上面的代码我们可以看出,有了函数式编程,使代码变的简单灵活,我们不需要具体的实现,而是根据具体的需要在参数中传递即可。
@FunctionalInterface public interface MyFunctionsInterface { int get(int a, int b, int c); } public static void main(String[] args) { System.out.println(new MyFunctionsInterface() { @Override public int get(int a, int b, int c) { return a + b + c; } }.get(1, 2, 3)); System.out.println(((MyFunctionsInterface) (a, b, c) -> a + b + c).get(1, 2, 3)); }
具体详情参考官方文档
5.四大接口
java8的java.util.funciton包下提供了四大接口。我们从上面可以了解到,我们要实现功能需要定制接口。为了更加简单,java8为我们提供了四类接口,另外还有一些拓展的接口。
1)Consumer<T> 接收一个参数并且没有返回值
@FunctionalInterface public interface Consumer<T> { void accept(T t); default Consumer<T> andThen(Consumer<? super T> after) { Objects.requireNonNull(after); return (T t) -> { accept(t); after.accept(t); }; } } public static void main(String[] args) { ((Consumer)(t-> System.out.println(t))).accept("AAAAAA"); }
2)Supplier<T>没有参数返回一个结果
@FunctionalInterface public interface Supplier<T> { T get(); } public static void main(String[] args) { System.out.println(((Supplier) (() -> "hello")).get()); }
3)Function<T,R> 接收一个类型参数,返回另一个参数类型结果
案例:把字符串转大写
System.out.println(((Function<String,String>)(x->x.toUpperCase())).apply("abc"));
4)Predicate<T> 传入一个参数,返回一个boolean值
案例:把String[]中长度大于4的字符串放入List中
@FunctionalInterface public interface Predicate<T> { boolean test(T t); default Predicate<T> or(Predicate<? super T> other) { Objects.requireNonNull(other); return (t) -> test(t) || other.test(t); } static <T> Predicate<T> isEqual(Object targetRef) { return (null == targetRef) ? Objects::isNull : object -> targetRef.equals(object); } } String[] strings = {"abcde", "dasfdasfe", "ab", "ddd"}; List<String> stringList = new ArrayList<>(); for (String string : strings) { if (((Predicate<String>) (s -> s.length() > 4)).test(string)) { stringList.add(string); } } System.out.println(stringList);
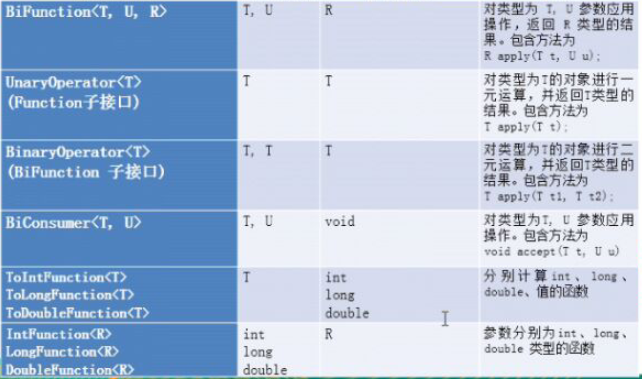
5)拓展接口
除了上面的四种接口外java8还提供了一些拓展接口
6.方法引用
1.对象::实例方法名 典型例子System.out::println
//对象::方法名 println方法的参数列表和返回值类型,与Consumer<String>的accept参数列表和返回值类型一致 PrintStream out = System.out; Consumer<String> consumer=x->out.println(x); consumer.accept("hello"); PrintStream out1 = System.out; Consumer<String> consumer1=out1::println; // Consumer<String> consumer1=System.out::println; consumer1.accept("world");
2.类::静态方法名
//类::静态方法名 Comparator<Integer> comparator=(x,y)->Integer.compare(x, y); Comparator<Integer> compare = Integer::compare;
注意:1、2需要满足的条件是 Lambda中调用的方法中返回值类型和参数列表类型,要与函数式接口的方法返回值类型和参数列表类型一样。 为啥呢?返回值类型一样很明显因为方法引用本身就是接口的一种实现,而参数列表要求一致,我自己的理解新语法底层写的时候为了分清参数所以规定成这样的(如果参数顺序不一样可能再底层会分不清参数)。
3 .类::实例方法名
public static void main(String[] args) { //类::实力方法 BiPredicate<String,String> bp=(x,y)->x.equals(y); System.out.println(bp.test("hello", "hello")); BiPredicate<String,String> bp2=String::equals; System.out.println(bp2.test("hello", "hello"));
注意:通过类名掉用实例方法,显然不能直接调用。而且我们通过例子发现:显然参数列表不满足1、2的规则。所以它有自己的语法:第一个参数是类实例,第二个参数是类实例中方法的参数,返回值类型和1、2满足同样的规则。
4 类名::new
构造器引用显然是创建对象,所以返回值类型肯定是这个类。构造器的参数列表要与函数式接口一致。
package com.jiuzhouzhi.lambda; import java.util.Objects; public class Employee { private String name; private Integer age; private Double salary; private Status status; public Employee() { } public Employee(String name, Integer age, Double salary) { this.name = name; this.age = age; this.salary = salary; } public Employee(String name, Integer age, Double salary, Status status) { this.name = name; this.age = age; this.salary = salary; this.status = status; } public Status getStatus() { return status; } public void setStatus(Status status) { this.status = status; } public String getName() { return name; } public void setName(String name) { this.name = name; } public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } public Double getSalary() { return salary; } public void setSalary(Double salary) { this.salary = salary; } public Employee(String name) { this.name = name; } public Employee(String name, Integer age) { this.name = name; this.age = age; } public enum Status { FREE, BUSY, VOCATION; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Employee employee = (Employee) o; return Objects.equals(name, employee.name) && Objects.equals(age, employee.age) && Objects.equals(salary, employee.salary); } @Override public int hashCode() { return Objects.hash(name, age, salary); } @Override public String toString() { return "Employee{" + "name='" + name + '\'' + ", age=" + age + ", salary=" + salary + ", status=" + status + '}'; } }
package simple; import com.jiuzhouzhi.lambda.Employee; import java.util.function.BiFunction; import java.util.function.Function; import java.util.function.Predicate; import java.util.function.Supplier; /** * @ClassName Test * @Description * @Author 刘志红 * @Date 2019/3/26 **/ public class Test { public static void main(String[] args) { //构造器引用 //无参构造 //--lambda-- Supplier<Employee> supplier=()->new Employee(); //---构造引用-- Supplier<Employee> supplier1=Employee::new; Employee employee = supplier1.get(); //有参构造 //---lambda--- Function<String,Employee> function=x->new Employee(x); //---构造器引用--- Function<String,Employee> function1=Employee::new; Employee xaoqiang = function1.apply("小强"); //---lambda--- BiFunction<String,Integer,Employee> function2=(x,y)->new Employee(x,y); //---构造器引用--- BiFunction<String,Integer,Employee> function3=Employee::new; Employee wangcai = function3.apply("旺财", 22); //三个或者以上的构造器,需要自己写接口 //数组对象 Function<Integer,String[]> function4=x->new String[x]; Function<Integer,String[]> function5=String[]::new; String[] apply = function5.apply(3); System.out.println(apply.length); } }
四种方法引用案例:
public class LambdaTest { public static class MyStringUtil { private static final MyStringUtil MY_STRING_UTIL = new MyStringUtil(); public static String toUppercase(String x) { return x.toUpperCase(); } public String toUppercase2(String x) { return x.toUpperCase(); } } public static class Person { private String name; private int age; public Person() { } public Person(String name) { this.name = name; } public Person(String name, int age) { this.name = name; this.age = age; } @Override public String toString() { return "Person{" + "name='" + name + '\'' + ", age=" + age + '}'; } } //方法引用其实就是本来实现需要自己写,现在已经有实现这个功能的方法了我们直接拿过来即可 public static void main(String[] args) { //方法引用1: 类名::静态方法 System.out.println("================静态方法引用==========================="); //用Lambda实现 Function<String, String> function = x -> x.toUpperCase(); String str = function.apply("abc"); System.out.println(str); //方法引用实现 由于没有现成方法满足所需条件,所以上面自己写了个方法 Function<String, String> function1 = MyStringUtil::toUppercase; str = function.apply("abc"); System.out.println(str); //方法应用2 类名::new 参数比较多的时候我们需要自己构造函数式接口 System.out.println("=========构造方法引用==============================="); //用Lambda实现 //无参构造 Supplier<Person> supplier = () -> new Person(); Person person1 = supplier.get(); System.out.println(person1); //一个参数构造 Function<String, Person> function2 = x -> new Person(x); Person person2 = function2.apply("小强"); System.out.println(person2); //两个参数的构造 BiFunction<String, Integer, Person> biFunction = (x, y) -> new Person(x, y); Person person3 = biFunction.apply("小强", 12); System.out.println(person3); //构造方法引用 类名::new Supplier<Person> supplier1 = Person::new; Person person11 = supplier1.get(); System.out.println(person11); Function<String, Person> function3 = Person::new; Person person12 = function3.apply("小王"); System.out.println(person12); BiFunction<String, Integer, Person> biFunction1 = Person::new; Person person13 = biFunction.apply("小强", 22); System.out.println(person13); System.out.println("======== 对象引用成员方法 ==================================="); //方法引用3 对象::成员方法 //我们把上面的例子重新拿下来 用Lambda方法如下 Function<String, String> function4 = x -> x.toUpperCase(); System.out.println(function4.apply("abcd")); //用对象引用方法如下.这种方法用于存在对象的情况下使用 Function<String, String> function5 = MyStringUtil.MY_STRING_UTIL::toUppercase2; System.out.println(function5.apply("abcd")); //上面是我们自己写对象。再入已经有的对象直接拿来用就行 Consumer consumer = System.out::println; consumer.accept("abcdddd"); //方法引用4 接口方法中第一个参数为类实例,后面参数为这个类实例对应方法的参数列表 System.out.println("==========类引用成员方法 ============================"); //还是用字符串转化为大写为例,本身有一个参数 //Lambda BiFunction<MyStringUtil, String, String> biFunction2 = (x, y) -> x.toUppercase2(y); System.out.println(biFunction2.apply(MyStringUtil.MY_STRING_UTIL,"abcd")); //类::成员方法 BiFunction<MyStringUtil, String, String> toUppercase2 = MyStringUtil::toUppercase2; System.out.println(toUppercase2.apply(MyStringUtil.MY_STRING_UTIL,"abcd")); } }
详情参考官方文档
7.Stream流
有关内容转自 https://blog.csdn.net/justloveyou_/article/details/79562574
前提Join/Fork
引用http://ifeve.com/talk-concurrency-forkjoin/
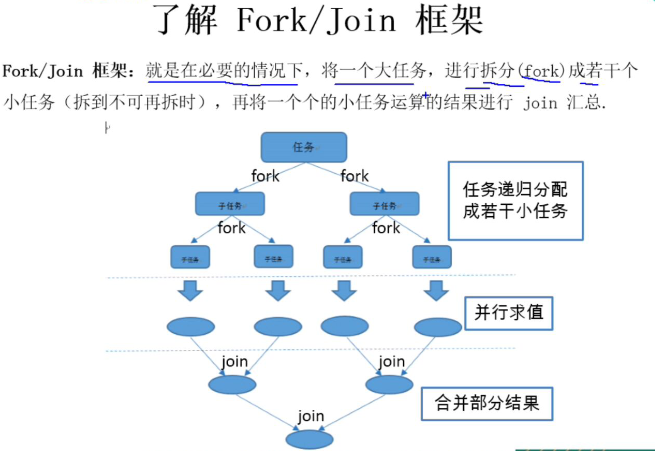
1.Fork/Join框架原理
Fork/Join框架是Java7提供了的一个用于并行执行任务的框架, 是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得 到大任务结果的框架。 我们再通过Fork和Join这两个单词来理解下Fork/Join框架,Fork就是把一个大任务切分为若干子任务并行的执行,Join就是合并这些子 任务的执行结果,最后得到这个大任务的结果。比如计算1+2+。。+10000,可以分割成10个子任务, 每个子任务分别对1000个数进行求和,最终汇总这10个子任务的结果,对于数据量特别大的话 Fork-Join执行效率会比普通方式高
2.采用工作窃取算法 工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。
那么为什么需要使用工作窃取算法呢?假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务, 为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务, 线程和队列一一对应,比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完, 而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活, 于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争, 通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争, 比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列
3.Fork/Join框架的介绍 我们已经很清楚Fork/Join框架的需求了,那么我们可以思考一下,如果让我们来设计一个Fork/Join框架,该如何设计? 这个思考有助于你理解Fork/Join框架的设计。
第一步分割任务。首先我们需要有一个fork类来把大任务分割成子任务,有可能子任务还是很大,所以还需要不停的分割,直到分割出的子任务足够小。
第二步执行任务并合并结果。分割的子任务分别放在双端队列里,然后几个启动线程分别从双端队列里获取任务执行。子任务执行完的结果都统一放在一个队列里,启动一个线程从队列里拿数据,然后合并这些数据。
Fork/Join使用两个类来完成以上两件事情:
ForkJoinTask:我们要使用ForkJoin框架,必须首先创建一个ForkJoin任务。它提供在任务中执行fork()和join()操作的机制,通常情况下我们不需要直接继承ForkJoinTask类,而只需要继承它的子类,Fork/Join框架提供了以下两个子类: RecursiveAction:用于没有返回结果的任务。 RecursiveTask :用于有返回结果的任务。 ForkJoinPool :ForkJoinTask需要通过ForkJoinPool来执行,任务分割出的子任务会添加到当前工作线程所维护的双端队列中,进入队列的头部。当一个工作线程的队列里暂时没有任务时,它会随机从其他工作线程的队列的尾部获取一个任务。
为什么用的不是很多 由于java7及以前时候,代码比较发杂,java8对stream对Fork-join进行了封装简化 具体的看代码,在运行测试的时候我们打开任务管理器,发现cpu的利用率在运行fork-join时候会很高
java8的并行流和串行流

java1.7
package com.jiuzhouzhi.forkjoin.java7; import java.util.concurrent.RecursiveTask; /** * @ClassName ForkJoinCaculate * @Description java7中Fork/Join框架使用 * @Author 刘志红 * @Date 2018/9/12 **/ public class ForkJoinCaculate extends RecursiveTask { private long start; private long end; /** * THRESHOLD 阈值 */ private static final long THRESHOLD=10000L; public ForkJoinCaculate(long start, long end) { this.start = start; this.end = end; } @Override protected Long compute() { long sum=0; //如果小于等于阈值就计算 if((end-start)<=THRESHOLD){ for (long i = start; i <=end ; i++) { sum+=i; } } //不然就继续分成小任务 else{ long middle=(start+end)/2; //如果任务大于阀值,就分裂成两个子任务计算 ForkJoinCaculate left = new ForkJoinCaculate(start, middle); ForkJoinCaculate right = new ForkJoinCaculate(middle + 1, end); //执行子任务 left.fork(); right.fork(); //等待子任务执行结束,并得到结果 long leftResult= (long) left.join(); long rightResult= (long) right.join(); sum=leftResult+rightResult; } return sum; } }
package com.jiuzhouzhi.forkjoin.java7; import org.junit.Test; import java.util.concurrent.ForkJoinPool; import java.util.concurrent.RecursiveTask; /** * @ClassName ForkJoinTest * @Description Fork/Join框架测试 * @Author 刘志红 * @Date 2018/9/12 **/ public class ForkJoinTest { //使用fork/join方式计算1+2+...+10000000000L 数据小的话用普通的单线程运算快 因为fork-join还需要分任务也是需要耗费时间的 数据量 //大的话用fork/join运算效率高 @Test public void test() { long start = System.currentTimeMillis(); //java7计算时间的方法 ForkJoinPool forkJoinPool = new ForkJoinPool(); RecursiveTask recursiveTask = new ForkJoinCaculate(0, 10000L); long invoke = (long) forkJoinPool.invoke(recursiveTask); System.out.println(invoke); long end = System.currentTimeMillis(); System.out.println(end - start); } //采用普通方式 @Test public void test1() { long start = System.currentTimeMillis(); long sum = 0; for (long i = 0; i <= 10000L; i++) { sum += i; } System.out.println(sum); long end = System.currentTimeMillis(); System.out.println(end - start); } }
java1.8
package com.jiuzhouzhi.forkjoin.java8; import org.junit.Test; import java.time.Duration; import java.time.Instant; import java.util.stream.LongStream; /** * @ClassName ForkJoinTest * @Description java8中fork/join的使用 * @Author 刘志红 * @Date 2018/9/12 **/ public class ForkJoinTest { @Test public void test(){ Instant start = Instant.now();//java8中计算时间的方法 long reduce = LongStream.rangeClosed(0, 10000L) .parallel() //不加此句的话是串行流 加上这句是并行流 .reduce(0, Long::sum); System.out.println(reduce); Instant end = Instant.now(); System.out.println(Duration.between(start,end).toMillis());//java8中计算时间的方法 } }
1)概述
Stream是Java8的一大亮点,是对容器对象功能的增强,它专注于对容器对象进行各种非常便利、高效的 聚合操作(aggregate operation)或者大批量数据操作。Stream API借助于同样新出现的Lambda表达式,极大的提高编程效率和程序可读性。同时,它提供串行和并行两种模式进行汇聚操作,并发模式能够充分利用多核处理器的优势,使用fork/join并行方式来拆分任务和加速处理过程。所以说,Java8中首次出现的 java.util.stream是一个函数式语言+多核时代综合影响的产物。
什么是聚合操作
在传统的J2EE应用中,Java代码经常不得不依赖于关系型数据库的聚合操作来完成诸如:
- 客户每月平均消费金额
- 最昂贵的在售商品
- 本周完成的有效订单(排除了无效的)
- 取十个数据样本作为首页推荐
这类的操作。但在当今这个数据大爆炸的时代,在数据来源多样化、数据海量化的今天,很多时候不得不脱离 RDBMS,或者以底层返回的数据为基础进行更上层的数据统计。而Java的集合API中,仅仅有极少量的辅助型方法,更多的时候是程序员需要用Iterator来遍历集合,完成相关的聚合应用逻辑,这是一种远不够高效、笨拙的方法。
2)用法
Stream 的三个操作步骤
1.创建Stream
1.可以通过Collection系统集合提供stream()串行流(一个线程)或parallelStream()并行流(多个线程)
2.通过Arrays中的静态方法stream()获取数组流
3.通过Steam的静态方法of()
4.创建无限流
public class TestStreamAPI1 { @Test public void test1(){ //1.可以通过Collection系统集合提供stream()串行流(一个线程)或parallelStream()并行流(多个线程) List<String> list=new ArrayList<>(); Stream<String> stream1=list.stream(); //2.通过Arrays中的静态方法stream()获取数组流 Employee[] emps=new Employee[10]; Stream<Employee> stream2 = Arrays.stream(emps); //3.通过Steam的静态方法of() Stream<String> stream3 = Stream.of("aa", "bb", "cc"); //4.创建无限流 //迭代 Stream<Integer> stream4 = Stream.iterate(0, x -> x + 2); stream4.limit(10).forEach(System.out::println); //生成 Stream.generate(()->Math.random()).limit(5).forEach(System.out::println); } }
2.中间操作 :多个中间操作可以连接起来形成一个流水线,除非流水线上出发终止操作,否则中间操作不会执行任何处理而在终止操作时一次性全部处理,成为“惰性求值”
1. 筛选与切片
filter——接收Lambda, 从流中排除某些元素
limit——截断流,使其元素不超过给定数量
skip(n)——跳过元素,返回一个扔掉了前n个元素的流。若流中元素不足n个,则返回一个空流。与limit(n)互补
distinct——筛选,通过流所生成的元素的hashCode()和equals()方法去除重复元素。
2. 映射
map-映射 接收Lambda 将元素转换成其他形式提取信息。接收一个函数作为参数,该函数会被应用每个元素上,并将其映射成一个新的元素
flagMap-接收一个函数作为参数,将流中每一个值转换成另一个流,然后把所有流连接成一个流
3. 排序
sorted()--自然排序 Comparable
sorted(Comparator c) 制定排序 包装类有对应的静态方法 例如Integer.compare() String 有 对象.compareTo()方法
package com.jiuzhouzhi.lambda; import java.util.Objects; public class Employee { private String name; private Integer age; private Double salary; private Status status; public Employee() { } public Employee(String name, Integer age, Double salary) { this.name = name; this.age = age; this.salary = salary; } public Employee(String name, Integer age, Double salary, Status status) { this.name = name; this.age = age; this.salary = salary; this.status = status; } public Status getStatus() { return status; } public void setStatus(Status status) { this.status = status; } public String getName() { return name; } public void setName(String name) { this.name = name; } public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } public Double getSalary() { return salary; } public void setSalary(Double salary) { this.salary = salary; } public Employee(String name) { this.name = name; } public Employee(String name, Integer age) { this.name = name; this.age = age; } public enum Status { FREE, BUSY, VOCATION; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Employee employee = (Employee) o; return Objects.equals(name, employee.name) && Objects.equals(age, employee.age) && Objects.equals(salary, employee.salary); } @Override public int hashCode() { return Objects.hash(name, age, salary); } @Override public String toString() { return "Employee{" + "name='" + name + '\'' + ", age=" + age + ", salary=" + salary + ", status=" + status + '}'; } }
package com.jiuzhouzhi.stream; import com.jiuzhouzhi.lambda.Employee; import org.junit.Test; import java.util.*; import java.util.stream.Stream; /** * 多个中间操作可以连接起来形成一个流水线,除非流水线上出发终止操作,否则中间操作不会执行任何处理而在终止操作时一次性全部处理,成为“惰性求值” */ public class TestStreamAPI2 { List<Employee> list = Arrays.asList( new Employee("lisi", 25, 4500.0), new Employee("zhangsan", 20, 4000.0), new Employee("zhangsan", 20, 4000.0), new Employee("zhangsan", 20, 4000.0), new Employee("wangwu", 35, 6000.0), new Employee("zhaoliu", 40, 7000.0) ); List<String> list1 = Arrays.asList("aaa", "bbb", "ccc", "ddd"); /** * 筛选与切片 * filter——接收Lambda, 从流中排除某些元素 * limit——截断流,使其元素不超过给定数量 * skip(n)——跳过元素,返回一个扔掉了前n个元素的流。若流中元素不足n个,则返回一个空流。与limit(n)互补 * distinct——筛选,通过流所生成的元素的hashCode()和equals()方法去除重复元素。 */ //1.filter @Test public void test1() { Stream<Employee> employeeStream = list.stream().filter(x -> { System.out.println("中间操作不执行"); return x.getAge() > 25; }); System.out.println("======================"); //不加下面的终止操作 中间操作的打印语句不执行 employeeStream.forEach(System.out::println); //上面迭代操作是streamAPI自己完成称为内部迭代 //外部迭代:我们自己写代码迭代 System.out.println("======================"); Iterator<Employee> iterator = list.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); } } //limit @Test public void test2() { list.stream().filter(x -> x.getAge() >= 25) .limit(2) .forEach(System.out::println); } //skip @Test public void test3() { list.stream().filter(x -> x.getAge() >= 25) .skip(2) .forEach(System.out::println); } //distinct 由于distinct是通过流所生成的元素的hashCode()和equals()方法去除重复元素 //所以使用distinct时候需要重写过滤对象的hashCode和equals方法 @Test public void test4() { list.stream().filter(x -> x.getSalary() >= 4000) .distinct() .forEach(System.out::println); } /** * 映射 * map-映射 接收Lambda 将元素转换成其他形式提取信息。接收一个函数作为参数,该函数会被应用每个元素上,并将其映射成一个新的元素 * flagMap-接收一个函数作为参数,将流中每一个值转换成另一个流,然后把所有流连接成一个流 */ @Test public void test5() { list1.stream().map(String::toUpperCase) .forEach(System.out::println); System.out.println("----------------"); list.stream().map(Employee::getName).forEach(System.out::println); System.out.println("-------------------"); list1.stream().map(TestStreamAPI2::filterCharacter) .forEach(st -> st.forEach(System.out::println)); System.out.println("---------------------"); list1.stream().flatMap(TestStreamAPI2::filterCharacter).forEach(System.out::println); } public static Stream<Character> filterCharacter(String str) { List<Character> characters = new ArrayList<>(); for (Character c : str.toCharArray() ) { characters.add(c); } return characters.stream(); } /** * 排序 * sorted()--自然排序 Comparable * sorted(Comparator c) 制定排序 包装类有对应的静态方法 例如Integer.compare() String 有 对象.compareTo()方法 */ @Test public void test7(){ list1.stream().sorted().forEach(System.out::println); list.stream().sorted((x,y)->{ if (x.getAge().equals(y.getAge())){ return x.getSalary().compareTo(y.getSalary()); } else{ return -x.getAge().compareTo(y.getAge()); } }).forEach(System.out::println); } }
3.终止操作
1. 查找与匹配 allMatch——检查是否匹配所有元素
anyMatch——检查是否至少匹配一个元素
noneMatch——检查是否没有匹配所有元素
findFirst——返回第一个元素
findAny——返回当前流中的任意元素
count——返回流中元素总个数
max——返回流中元素最大值
min——返回流中元素最小值
2. 规约 reduce(T identity,BignaryOperator) / reduce(BigaryOperator)——可以将流中元素反复结合起来,得到一个值
3. 收集 collect——将流转换为其他形式,接收一个Collector接口的实现,用于给Stream中元素做汇总的方法 collect的参数是Collector接口 java8提供了
Collector操作的工具类Collectors
4.分组
5.分区
package com.jiuzhouzhi.stream; import com.jiuzhouzhi.lambda.Employee; import org.junit.Test; import java.util.*; import java.util.stream.Collectors; /** * 查找与匹配 * allMatch——检查是否匹配所有元素 * anyMatch——检查是否至少匹配一个元素 * noneMatch——检查是否没有匹配所有元素 * findFirst——返回第一个元素 * findAny——返回当前流中的任意元素 * count——返回流中元素总个数 * max——返回流中元素最大值 * min——返回流中元素最小值 */ public class TestStreamAPI3 { List<Employee> list = Arrays.asList( new Employee("zhangsan", 20, 4000.0, Employee.Status.FREE), new Employee("zhangsan", 20, 4000.0, Employee.Status.BUSY), new Employee("zhangsan", 20, 4000.0, Employee.Status.BUSY), new Employee("zhangsan", 20, 4000.0, Employee.Status.BUSY), new Employee("zhangsan", 20, 4000.0, Employee.Status.BUSY), new Employee("wangwu", 35, 6000.0, Employee.Status.BUSY), new Employee("wangwu", 35, 6000.0, Employee.Status.BUSY), new Employee("zhaoliu", 40, 7000.0, Employee.Status.VOCATION) ); @Test public void test1() { System.out.println("---------------------allMatch"); boolean b = list.stream().allMatch(e -> e.getStatus().equals(Employee.Status.BUSY)); System.out.println(b); System.out.println("---------------anyMatch"); boolean b1 = list.stream().anyMatch(e -> e.getStatus().equals(Employee.Status.BUSY)); System.out.println(b1); System.out.println("-------------------noneMatch"); boolean b2 = list.stream().noneMatch(e -> e.getStatus().equals(Employee.Status.BUSY)); System.out.println(b2); System.out.println("-----------------findFirst"); Optional<Employee> first = list.stream().sorted((x, y) -> -Double.compare(x.getSalary(), y.getSalary())).findFirst(); System.out.println(first.get()); System.out.println("---------------findAny"); //由于findAny是找到任何一个元素 Optional<Employee> any = list.parallelStream().filter(e -> e.getStatus().equals(Employee.Status.BUSY)).findAny(); System.out.println(any); } @Test public void test2() { System.out.println("-----------count"); long count = list.stream().count(); System.out.println(count); System.out.println("-------------max"); /*Optional<Employee> max = list.stream().max((x, y) -> Double.compare(x.getSalary(), y.getSalary()));*/ //用下面的代码等价于上面的 Optional<Employee> max = list.stream().max(Comparator.comparingDouble(x -> x.getSalary())); System.out.println(max.get()); System.out.println("--------------min"); Optional<Double> min = list.stream().map(Employee::getSalary).min(Double::compare); System.out.println(min.get()); } /** * 规约 * reduce(T identity,BignaryOperator) / reduce(BigaryOperator)——可以将流中元素反复结合起来,得到一个值 */ @Test public void test3(){ List<Integer> integers=Arrays.asList(1,2,3,4,5,6,7,8,9); Integer reduce = integers.stream().reduce(0, (x, y) -> x + y); System.out.println(reduce); System.out.println("-----------------------------------------"); /** * map和reduce一起使用称为 map-reduce模式 */ Optional<Double> reduce1 = list.stream().map(Employee::getSalary).reduce(Double::sum); System.out.println(reduce1.get()); } /** * 收集 * collect——将流转换为其他形式,接收一个Collector接口的实现,用于给Stream中元素做汇总的方法 * collect的参数是Collector接口 java8提供了Collector操作的工具类Collectors */ @Test public void test4(){ System.out.println("--------------------------------------------收集到list中"); list.stream().map(Employee::getName).collect(Collectors.toList()).forEach(System.out::println); System.out.println("---------------------------------------------收集到set中"); list.stream().map(Employee::getName).collect(Collectors.toSet()).forEach(System.out::println); System.out.println("----------------------------------------------收集到hashSet中"); list.stream().map(Employee::getName).collect(Collectors.toCollection(HashSet::new)).forEach(System.out::println); } @Test public void test5(){ System.out.println("--------------------------总数"); Long collect = list.stream().collect(Collectors.counting()); System.out.println(collect); System.out.println("---------------------------平均值"); Double collect1 = list.stream().collect(Collectors.averagingDouble(Employee::getSalary)); System.out.println(collect1); System.out.println("--------------------------------总和"); Double collect2 = list.stream().collect(Collectors.summingDouble(Employee::getSalary)); System.out.println(collect2); System.out.println("-------------------------------最大最小值"); Optional<Double> max1 = list.stream().map(Employee::getSalary).collect(Collectors.maxBy(Double::compare)); System.out.println(max1.get()); Optional<Double> min1 = list.stream().map(Employee::getSalary).collect(Collectors.minBy(Double::compare)); System.out.println(min1.get()); System.out.println("-------------------------------工资最小值最大值对应的员工"); Optional<Employee> collect3 = list.stream().collect(Collectors.maxBy((x, y) -> Double.compare(x.getSalary(), y.getSalary()))); System.out.println(collect3.get()); Optional<Employee> max = list.stream().max(Comparator.comparingDouble(Employee::getSalary)); System.out.println(max.get()); } //分组 @Test public void test6(){ Map<Employee.Status, List<Employee>> collect = list.stream().collect(Collectors.groupingBy(Employee::getStatus)); System.out.println(collect); } //多级分组 @Test public void test7(){ Map<Double, Map<String, List<Employee>>> collect = list.stream().collect(Collectors.groupingBy(Employee::getSalary, Collectors.groupingBy(e -> { if (e.getAge() <= 35) { return "青年"; } else return "中年"; }))); System.out.println(collect); } //分区 以及多级分区 和分组类似 @Test public void test8(){ Map<Boolean, List<Employee>> collect = list.stream().collect(Collectors.partitioningBy(e -> e.getSalary() > 5000)); System.out.println(collect); } }
3) stream和for性能比较
stream和for性能比较:for本来就是比较底层的操作,性能自然很高。stream的优势是并行处理。数据量越大,stream的优势越明显,数据量小,肯定是for循环性能最好。
4)总结
总之,Stream 的特性可以归纳为:
-
不是数据结构;
-
它没有内部存储,它只是用操作管道从source(数据结构、数组、generator function、IO channel)抓取数据;
-
它也绝不修改自己所封装的底层数据结构的数据。例如Stream的filter操作会产生一个不包含被过滤元素的新Stream,而不是从source删除那些元素;
-
所有Stream的操作必须以lambda表达式为参数;
-
不支持索引访问;
-
你可以请求第一个元素,但无法请求第二个,第三个,或最后一个;
-
很容易生成数组或者List;
-
惰性化;
-
很多Stream操作是向后延迟的,一直到它弄清楚了最后需要多少数据才会开始;
-
Intermediate操作永远是惰性化的;
-
并行能力;
-
当一个 Stream 是并行化的,就不需要再写多线程代码,所有对它的操作会自动并行进行的;
-
可以是无限的。集合有固定大小,Stream 则不必。limit(n)和findFirst()这类的short-circuiting操作可以对无限的Stream进行运算并很快完成。
stream中处理异常的方法:https://www.jianshu.com/p/597a7ccfec25
8.新容器类public final class Optional<T>
java8以前用null代表值不存在,这样会引发空指针异常,为了避免空指针异常java8出来这个类。
package com.jiuzhouzhi.optional; import org.junit.Test; import java.lang.management.OperatingSystemMXBean; import java.util.Optional; /** * @ClassName TestOptional2 * @Description 举例说明java7以前和java8多了Optional的区别 * @Author 刘志红 * @Date 2018/9/12 **/ public class TestOptional2 { /** * java7及以前 需要多层if判断null 如果Man Godness中字段更多的话那么需要判断的更多 */ public String getGodNessName(Man man) { if (man != null) { Godness godness = man.getGodness(); if (godness != null) { return godness.getName(); } } return "苍老师"; } @Test public void test1() { Man man = new Man(); String godNessName = getGodNessName(man); System.out.println(godNessName); } /** * java8以后 使用Optional类 NewMan Godness */ public String getGodNessNameNew(Optional<NewMan> man) { return man.orElse(new NewMan()).getOptional().orElse(new Godness("苍老师")).getName(); } @Test public void test2() { Optional<NewMan> o = Optional.ofNullable(null); String godNessNameNew = getGodNessNameNew(o); System.out.println(godNessNameNew); Optional<NewMan> xiaohua = Optional.ofNullable(new NewMan(Optional.ofNullable(new Godness("xiaohua")))); String godNessNameNew1 = getGodNessNameNew(xiaohua); System.out.println(godNessNameNew1); } }
常用方法:

package com.jiuzhouzhi.optional; import com.jiuzhouzhi.lambda.Employee; import org.junit.Test; import java.util.Optional; /** * @ClassName TestOptional * @Description Optional类的常用方式测试 * @Author 刘志红 * @Date 2018/9/12 **/ public class TestOptional { @Test public void test1(){ Optional<Employee> optional = Optional.of(new Employee()); Employee employee = optional.get(); System.out.println(employee); //创建一个空Optional 打开源码发现ofNullable是 of和empty的综合 Optional<Object> o = Optional.ofNullable(null); System.out.println(o); //判断Optional是否有值 if(o.isPresent()){ System.out.println(o.get()); } else{ o=Optional.of(new Employee()); System.out.println(o); } } @Test public void test2(){ //创建空Optional Optional<Object> empty = Optional.empty(); System.out.println(empty); System.out.println(empty.isPresent()); } @Test public void test3(){ // 如果有值返回值 无值用参数代替 Optional<Object> o = Optional.ofNullable(null); Object o1 = o.orElse(new Employee("张三", 25, 10000.0)); System.out.println(o1); Optional<Object> o2 = Optional.ofNullable(new Employee("李四", 25, 10000.0)); System.out.println(o2); } @Test public void test4(){ //orElseGet(Supplier s) //如果有值返回值 无值返回s获取的值 //由于参数是函数式接口那么我们可以添加我们想要的功能 Optional<Object> o = Optional.ofNullable(null); Object o1 = o.orElseGet(Employee::new); System.out.println(o1); } @Test public void test5(){ Optional<Employee> optional = Optional.ofNullable(new Employee("张三", 25, 10000.0)); Optional<String> s = optional.map(Employee::getName); System.out.println(s.get()); Optional<String> s1 = optional.flatMap(e -> Optional.of(e.getName())); System.out.println(s1.get()); } }
详情情参考官方文档
9.java8的新时间API
1) 概述
java8新出的一套时间的API 取代1.0出的Date和1.1的Calendar。Date、Calendar 的格式化存在线程安全问题 。并且时间日期格式化的类 SimpleDateFormat在java.text包中 显的不规范。新出的API都在java.time包下且不存在线程安全问题
测试类:
package com.jiuzhouzhi.time.java7; import org.junit.Test; import java.text.SimpleDateFormat; import java.util.ArrayList; import java.util.Date; import java.util.List; import java.util.concurrent.*; /** * @ClassName TimeTest * @Description java7及之前时间的问题 下面代码存在多线程问题 * @Author 刘志红 * @Date 2018/9/12 **/ public class TimeTest { @Test public void test1() throws ExecutionException, InterruptedException { SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyyMMdd"); Callable<Date> task = new Callable<Date>() { @Override public Date call() throws Exception { return simpleDateFormat.parse("20161212"); } }; //创建十个线程 ExecutorService pool = Executors.newFixedThreadPool(10); List<Future<Date>> list = new ArrayList<>(); for (int i = 0; i < 1000; i++) { Future<Date> submit = pool.submit(task);//用上面的十个线程执行1000次任务 list.add(submit); //执行结果放入list中 } System.out.println(list.size()); for (int i = 0; i <list.size() ; i++) { System.out.println(list.get(i).get()); } pool.shutdown(); //关闭线程池 } }
运行发现出现异常java.util.concurrent.ExecutionException: java.lang.NumberFormatException: For input string: ".1612E.16122E",处理办法 用 synchronized 或者ThreadLocal
添加synchronized比较简单这里不做说明,使用ThreadLocal如下:
package com.jiuzhouzhi.time.java7; import java.text.DateFormat; import java.text.ParseException; import java.text.SimpleDateFormat; import java.util.Date; /** * @ClassName DateFormatThreadLocal * @Description * @Author 刘志红 * @Date 2018/9/12 **/ public class DateFormatThreadLocal { private static final ThreadLocal<DateFormat> THREAD_LOCAL=new ThreadLocal<DateFormat>(){ @Override protected DateFormat initialValue() { return new SimpleDateFormat("yyyyMMdd"); } }; public static Date converse(String source) throws ParseException { return THREAD_LOCAL.get().parse(source); } } package com.jiuzhouzhi.time.java7; import org.junit.Test; import java.util.ArrayList; import java.util.Date; import java.util.List; import java.util.concurrent.*; /** * @ClassName TimeTest * @Description java7及之前处理时间多线程问题 * @Author 刘志红 * @Date 2018/9/12 **/ public class TimeTestHandled { @Test public void test1() throws ExecutionException, InterruptedException { Callable<Date> task = new Callable<Date>() { @Override public Date call() throws Exception { return com.jiuzhouzhi.time.java7.DateFormatThreadLocal.converse("20161212"); } }; ExecutorService pool = Executors.newFixedThreadPool(10); List<Future<Date>> list = new ArrayList<>(); for (int i = 0; i < 1000; i++) { Future<Date> submit = pool.submit(task); list.add(submit); } for (Future<Date> f : list ) { System.out.println(f.get()); } pool.shutdown(); } }
运行发现没有异常
java8:
package com.jiuzhouzhi.time.java8; import org.junit.Test; import java.time.LocalDate; import java.time.format.DateTimeFormatter; import java.util.ArrayList; import java.util.List; import java.util.concurrent.*; /** * @ClassName TimeTest * @Description java7及之前时间的问题 下面代码存在多线程问题 * @Author 刘志红 * @Date 2018/9/12 **/ public class TimeTestJ8 { @Test public void test1() throws ExecutionException, InterruptedException { DateTimeFormatter dateTimeFormatter=DateTimeFormatter.ofPattern("yyyyMMdd"); Callable<LocalDate> task = new Callable<LocalDate>() { @Override public LocalDate call() throws Exception { return LocalDate.parse("20161212",dateTimeFormatter); } }; ExecutorService pool = Executors.newFixedThreadPool(10); List<Future<LocalDate>> list = new ArrayList<>(); for (int i = 0; i < 1000; i++) { Future<LocalDate> submit = pool.submit(task); list.add(submit); } for (Future<LocalDate> f : list ) { System.out.println(f.get()); } pool.shutdown(); } }
运行也没有异常
2)用法
新时间API,LocalDate、LocalTime、LocalDateTime类的实例是不可变的对象。分别表示使用ISO-8601日历系统(国际标准化组织制定的现代公民的日期和时间的表示法)的日期、时间、日期时间。他们提供了简单的日期和时间,并不包含当前的时间信息也不包含与时区相关的信息。
/** * LocalDate LocalTime LocalDateTime * 这里只举例说明LocalDateTime 其他两个基本差不多 可以查看API */ @Test public void test1() { LocalDateTime now = LocalDateTime.now(); System.out.println(now); LocalDateTime of = LocalDateTime.of(2018, 10, 21, 12, 0, 20); System.out.println(of); LocalDateTime localDateTime = now.plusDays(1); System.out.println(localDateTime); LocalDateTime localDateTime1 = now.minusHours(1); System.out.println(localDateTime1); System.out.println(now.getYear()); System.out.println(now.getMonth()); System.out.println(now.getMonthValue()); System.out.println(now.getDayOfMonth()); System.out.println(now.getMonth().getValue()); System.out.println(now.getDayOfYear()); }
时间戳Instant
/** * Instant 时间戳(以Unix元年:1970年1月1日00:00:00到某个时间的毫秒值) */ @Test public void test2(){ //获取UTC时区的当前时间 Instant now1 = Instant.now(); //默认的是UTC时区和中国差8个小时的时差 System.out.println(now1); OffsetDateTime offsetDateTime = now1.atOffset(ZoneOffset.ofHours(8)); System.out.println(offsetDateTime); //转换成毫秒 System.out.println(now1.toEpochMilli()); //1970年1月1日00:00:00 为基础获取的时间 第一个是+1000毫秒第二个是+60秒 Instant instant = Instant.ofEpochMilli(1000); Instant instant1 = Instant.ofEpochSecond(60); System.out.println(instant); System.out.println(instant1); }
/** * Duration计算两个时间之间的间隔 * Period计算两个日期直接的间隔 */ @Test public void test3(){ Instant start = Instant.now(); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } Instant end=Instant.now(); Duration between = Duration.between(start, end); /** * 获取对应的需要的时间戳 * to----方法 * get---方法 */ System.out.println(between.toMillis()); System.out.println("----------------------"); LocalTime localTime1=LocalTime.now(); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } LocalTime localTime2 = LocalTime.now(); Duration between1 = Duration.between(localTime1, localTime2); System.out.println(between1.toMillis()); } @Test public void test4(){ LocalDate now1 = LocalDate.now(); LocalDate of = LocalDate.of(2018, 10, 21); Period between = Period.between(now1, of); System.out.println(between.getYears()+" "+between.getMonths()+" "+between.getDays()); }
时间矫正器TemporalAdjuester以及工具类TemporalAjuesters:用于操作日期
/** * TemporalAdjuster时间矫正器 */ @Test public void test5(){ /** * 第一种方式调整时间 */ //现在时间 LocalDateTime now = LocalDateTime.now(); System.out.println(now); //调整日期到本月10号 LocalDateTime localDateTime = now.withDayOfMonth(10); System.out.println(localDateTime); System.out.println("-----------------"); /** * 第二种方式调整时间 */ //下一个星期日的日期时间 LocalDateTime with = now.with(TemporalAdjusters.next(DayOfWeek.SUNDAY)); System.out.println(with); //自定义 下一个工作日 //进入TemporalAdjuster我们发现他是一个函数式接口 //抽象方法 Temporal adjustInto(Temporal temporal); LocalDate now1 = LocalDate.now(); LocalDate with1 = now1.with(x -> { DayOfWeek dayOfWeek = now1.getDayOfWeek(); if (dayOfWeek.equals(DayOfWeek.FRIDAY)) { return now1.plusDays(3); } else if (dayOfWeek.equals(DayOfWeek.SATURDAY)) { return now1.plusDays(2); } else { return now1.plusDays(1); } }); System.out.println("下个工作日"+with1); }
时间格式化 DateTimeFormatter
@Test public void test6(){ /** * 使用DateTimeFormat默认提供的格式格式化 */ DateTimeFormatter isoLocalDateTime = DateTimeFormatter.ISO_LOCAL_DATE_TIME; LocalDateTime localDateTime=LocalDateTime.now(); String format = isoLocalDateTime.format(localDateTime); System.out.println(format); System.out.println("----------------"); /** * 自定义的格式 */ DateTimeFormatter d = DateTimeFormatter.ofPattern("yyyy年MM月dd日HH小时mm分钟ss秒"); String format1 = d.format(localDateTime); System.out.println(format1); /** * 上面是显示指定格式的时间 我们也可以把 字符串格式的时间解析回日期时间 */ DateTimeFormatter d2 = DateTimeFormatter.ofPattern("yyyy年MM月dd日HH小时mm分钟ss秒"); LocalDateTime parse = LocalDateTime.parse("2018年09月12日22小时20分钟54秒", d2); System.out.println(parse); }
时区的处理:带时区的日期ZonedDate、时间ZonedTime、日期时间ZonedDateTime。其中每个时区都对应着ID。ZoneId类中包含了所有的时区信息。getAvailableZoneIds()可以获取所有时区的信息,of(id)用指定的时区信息获取ZoneId对象
/** * 时区的处理 ZoneDate ZoneTime ZoneDateTime * 和LocalDate LocalDateTime LocalTime类似 只不过加上时区 */ @Test public void test7(){ //查看所有的时区 ZoneId.getAvailableZoneIds().forEach(System.out::println); } @Test public void test8(){ //指定一个时区的当前时间 LocalDateTime now = LocalDateTime.now(ZoneId.of("America/Los_Angeles")); System.out.println(now); System.out.println("-----------------"); //查询当前的ZoneDateTime ZonedDateTime now1 = ZonedDateTime.now(); System.out.println(now1); //添加时区 ZonedDateTime now2 = ZonedDateTime.now(ZoneId.of("America/Los_Angeles")); System.out.println(now2); }
3)和Mysql的对应关系
引用自:https://blog.csdn.net/moxiong3212/article/details/74279739
首先保证数据库驱动不能低于4.2,查看驱动的方法解压jar找到MANIFEST.MF ,在其中找到Specification-Version对应的就是驱动的版本,如果你使用的mysql-connector-java版本低于5.1.37,则数据库的驱动版本低于4.2。运行会报错MysqlDataTruncation: Data truncation: Incorrect date
java时间和数据库时间的对应关系如下:
java mysql
LocalDateTime datetime
LocalDate date
LocalTime time
测试:注意数据库驱动jar和数据库版本的对应关系
test数据库中创建表:create table tb_java8date (id int not null primary key auto_increment,t_date date, t_time time, t_datetime datetime);
@Test public void test9() throws ClassNotFoundException, SQLException { Class.forName("com.mysql.jdbc.Driver"); Connection conn = DriverManager.getConnection("jdbc:mysql://localhost/test?characterEncoding=utf-8&useSSL=false&serverTimezone=UTC","root","1234"); PreparedStatement st = conn.prepareStatement("insert into tb_java8date (t_date,t_time,t_datetime)values(?,?,?)"); st.setObject(1, LocalDate.now()); st.setObject(2, LocalTime.now()); st.setObject(3, LocalDateTime.now()); st.execute(); st.close(); conn.close(); }
运行刷新数据库发现添加成功
9.对注解的改进
1)添加元注解@Repeatable
@Documented @Retention(RetentionPolicy.RUNTIME) @Target(ElementType.ANNOTATION_TYPE) public @interface Repeatable { Class<? extends Annotation> value(); }
2)@Target中添加了两种作用类型
public enum ElementType { /** Class, interface (including annotation type), or enum declaration */ TYPE, /** Field declaration (includes enum constants) */ FIELD, /** Method declaration */ METHOD, /** Formal parameter declaration */ PARAMETER, /** Constructor declaration */ CONSTRUCTOR, /** Local variable declaration */ LOCAL_VARIABLE, /** Annotation type declaration */ ANNOTATION_TYPE, /** Package declaration */ PACKAGE, /** * Type parameter declaration * * @since 1.8 */ TYPE_PARAMETER, /** * Use of a type * * @since 1.8 */ TYPE_USE }
//自定义注解如下
public class TestA { @Retention(RetentionPolicy.RUNTIME) @Target(ElementType.TYPE) public @interface Filters { Filter[] value(); } @Retention(RetentionPolicy.RUNTIME) @Target(ElementType.TYPE) @Repeatable(Filters.class) public @interface Filter { String value(); } @Filter("value1") @Filter("value2") public interface TestInterface{} @Test public void test() { for (Filter filter : TestInterface.class.getAnnotationsByType(Filter.class)) { System.out.println(filter.value()); } } }
详情参考官方文档
10.Nashorn JavaScript引擎
Java 8提供了新的Nashorn JavaScript引擎,使得我们可以在JVM上开发和运行JS应用。Nashorn JavaScript引擎是javax.script.ScriptEngine的另一个实现版本,这类Script引擎遵循相同的规则,允许Java和JavaScript交互使用,例子代码如下:
ScriptEngineManager scriptEngineManager=new ScriptEngineManager(); ScriptEngine script = scriptEngineManager.getEngineByName("javascript"); System.out.println(script.getClass().getName()); System.out.println(script.eval("function f(){return 1;} f()+1;"));
11.Base64编码
对Base64编码的支持已经被加入到Java 8官方库中,这样不需要使用第三方库就可以进行Base64编码,例子代码如下:
@Test public void test() { final String text = "I love you!"; final String encode = Base64.getEncoder().encodeToString(text.getBytes(StandardCharsets.UTF_8)); System.out.println(encode); final String decode=new String(Base64.getDecoder().decode(encode),StandardCharsets.UTF_8); System.out.println(decode); }
12.并行数组
//创建容量为20000的数组 long[] arrayOfLong=new long[20000]; //并行输入20000个随机数 Arrays.parallelSetAll(arrayOfLong, index-> ThreadLocalRandom.current().nextInt(1000000)); Arrays.stream(arrayOfLong).limit(20).forEach(i-> System.out.print(i+" ")); System.out.println(); //并行排序 Arrays.parallelSort(arrayOfLong); Arrays.stream(arrayOfLong).limit(20).forEach(i-> System.out.print(i+" "));
13.并发性
基于新增的lambda表达式和steam特性,为Java 8中为java.util.concurrent.ConcurrentHashMap类添加了新的方法来支持聚焦操作;另外,也为java.util.concurrentForkJoinPool类添加了新的方法来支持通用线程池操作(更多内容可以参考我们的并发编程课程)。
Java 8还添加了新的java.util.concurrent.locks.StampedLock类,用于支持基于容量的锁——该锁有三个模型用于支持读写操作(可以把这个锁当做是java.util.concurrent.locks.ReadWriteLock的替代者)。
在java.util.concurrent.atomic包中也新增了不少工具类,列举如下:
- DoubleAccumulator
- DoubleAdder
- LongAccumulator
- LongAdder
14.新的java工具
1)Nashorn引擎:jjs 官方文档 新手学习可以到https://www.runoob.com/java/java8-nashorn-javascript.html
打开jdk的bin目录我们可以看到jjs.exe,点击可以打开交互式控制台。
jjs> function f(){return 1;}
function f(){return 1;}
jjs> print(f()+1);
2
jjs>
也可以创建一个func.js文件
function f(){
return 1;
}
print(f()+1);
然后在对应路径下执行 jjs func.js
2)类依赖分析器:jdeps
jdeps是一个相当棒的命令行工具,它可以展示包层级和类层级的Java类依赖关系,它以.class文件、目录或者Jar文件为输入,然后会把依赖关系输出到控制台
详情参考官方文档
15.JVM新特性
使用Metaspace(JEP 122)代替持久代(PermGen space)。在JVM参数方面,使用-XX:MetaSpaceSize和-XX:MaxMetaspaceSize代替原来的-XX:PermSize和-XX:MaxPermSize。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号