
大数据Spark与Storm技术选型

先做一个对比:
|
对比点 |
Storm |
Spark Streaming |
|
实时计算模型 |
纯实时,来一条数据,处理一条数据 |
准实时,对一个时间段内的数据收集起来,作为一个RDD,再处理 |
|
实时计算延迟度 |
毫秒级 |
秒级 |
|
吞吐量 |
低 |
高 |
|
事务机制 |
支持完善 |
支持,但不够完善 |
|
健壮性 / 容错性 |
ZooKeeper,Acker,非常强 |
Checkpoint,WAL,一般 |
|
动态调整并行度 |
支持 |
不支持
|
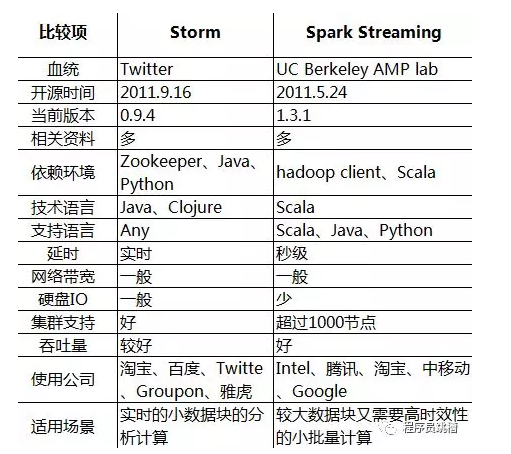
再来说说Spark Streaming与Storm的应用场景

先说一下Storm:
1、建议在那种需要纯实时,不能忍受1秒以上延迟的场景下使用,比如实时金融系统,要求纯实时进行金融交易和分析
2、此外,如果对于实时计算的功能中,要求可靠的事务机制和可靠性机制,即数据的处理完全精准,一条也不能多,一条也不能少,也可以考虑使用Storm
3、如果还需要针对高峰低峰时间段,动态调整实时计算程序的并行度,以最大限度利用集群资源(通常是在小型公司,集群资源紧张的情况),也可以考虑用Storm
4、如果一个大数据应用系统,它就是纯粹的实时计算,不需要在中间执行SQL交互式查询、复杂的transformation算子等,那么用Storm是比较好的选择

Spark 呢:
1、如果对上述适用于Storm的三点,一条都不满足的实时场景,即,不要求纯实时,不要求强大可靠的事务机制,不要求动态调整并行度,那么可以考虑使用Spark Streaming
2、考虑使用Spark Streaming最主要的一个因素,应该是针对整个项目进行宏观的考虑,即,如果一个项目除了实时计算之外,还包括了离线批处理、交互式查询等业务功能,而且实时计算中,可能还会牵扯到高延迟批处理、交互式查询等功能,那么就应该首选Spark生态,用Spark Core开发离线批处理,用Spark SQL开发交互式查询,用Spark Streaming开发实时计算,三者可以无缝整合,给系统提供非常高的可扩展性
Spark Streaming与Storm的优劣分析
事实上,Spark Streaming绝对谈不上比Storm优秀。这两个框架在实时计算领域中,都很优秀,只是擅长的细分场景并不相同。
Spark Streaming仅仅在吞吐量上比Storm要优秀,而吞吐量这一点,也是历来挺Spark Streaming,贬Storm的人着重强调的。但是问题是,是不是在所有的实时计算场景下,都那么注重吞吐量?不尽然。因此,通过吞吐量说Spark Streaming强于Storm,不靠谱。
事实上,Storm在实时延迟度上,比Spark Streaming就好多了,前者是纯实时,后者是准实时。而且,Storm的事务机制、健壮性 / 容错性、动态调整并行度等特性,都要比Spark Streaming更加优秀。
Spark Streaming,有一点是Storm绝对比不上的,就是:它位于Spark生态技术栈中,因此Spark Streaming可以和Spark Core、Spark SQL无缝整合,也就意味着,我们可以对实时处理出来的中间数据,立即在程序中无缝进行延迟批处理、交互式查询等操作。这个特点大大增强了Spark Streaming的优势和功能。
推荐阅读:
filebeat+kafka+strom+logstash+es 舆情采集系统
微信公众号:
加微信:wonter 发送:技术Q
医疗微信群:
加微信:wonter 发送:医疗Q
更多文章关注公众号:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号