

【远程医疗】互联网医院 卫健委数据上报平台技术方案
说到数据上报,很多人第一印象是直接点对点的上报数据,优点是简单直接省事,但是缺点很明显,侵入性太强,业务中会掺杂很多非业务的事情。当然这里的简单省事是短暂的,如果业务以及开发完了,后面追加数据上报功能,再按照这个模式,将带来空前的压力,代码基本上要重新写、测试。这个任务量也许会很大,因为一时的省事为以后埋下大坑,这个是做研发要极力避免的、不能容忍的。此时我们要做的事是如何解耦,将非业务性功能提取出来,做成一个统一的数据上报平台。因此我们就有了下文的技术方案。
系统设计架构图:
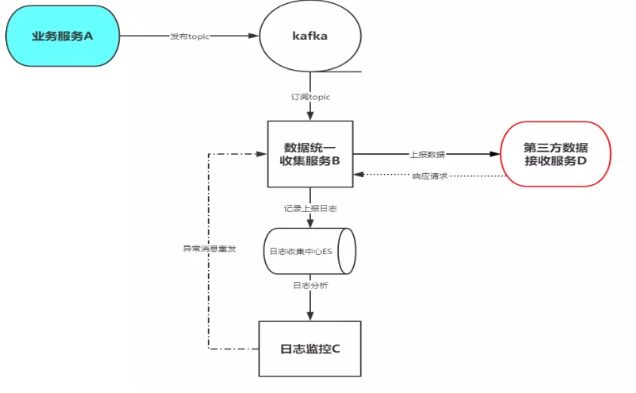
图示:关于技术选型,a、b、c都是基于springcloud,数据存储我们选择Elasticsearch,消息中间件使用kafka。
上图的业务是将a服务的数据上报到d服务。按照一般的流程我们可以直接将a服务的数据直接发送到d服务,这样的好处是简单,但是缺点显而易见,侵入性、耦合性太强,这不是我们想要的。我们要将与业务无关的服务剥离出来,做成一个统一的数据上报中心也就是上图中的b服务,在这个服务中只做一件事,那就是业务数据上报,而此时的a服务只管专心的做业务,无需关心其它,二者各司其职,互不影响,做到真正的业务分离。
此时b服务的上报数据从哪儿来,a服务直接发给b服务?很明显不是,如果这样做和a服务点对点发送到d服务有什么区别呢,反而增加了一个中间环节,增加了不稳定因素。那我们该怎么做?想一想,多个程序如何进行消息传递?此时我们会想到消息中间件这个很神奇的一个东西。网上搜索一大堆消息中间件,那么我们该如何选择呢?我们这里选择的是kafka,原因是我们这里的数据量大、生态环境非常好,实时数据处理比较好,而且我们之前已经在使用它了,在满足业务的情况下,没有必要再额外的维护一个中间件,我们要本着业务、经济的原则去技术选型,不要为了技术而技术。

在上报数据的时候我们还得考虑很多问题:
1.上报数据日志监控
我们这里的日志量很大,而且需要各种维度的日志分析这个功能,因此日志存储我们采用Elasticsearch。
它是一个分布式搜索引擎,支持海量数据存储,检索查询。在这里使用它再适合不过。
2.数据丢失。比如服务d宕机、网络堵塞原因会导致上报数据丢失(在a、b服务正常的情况下),那么如何解决这个?由于我们做了日志监控,所以会很简单的解决这个问题,将上报异常的数据重新发送就好了。
使用场景:
本架构使用在互联网医院项目中,业务是卫健委要求医院上报在线看病患者产生的数据,且上报数据不允许丢失,如果对方平台无法使用,则要求补发丢失数据。
a对应医院在线看病服务,d对应卫健委数据接收服务。b、c就是内部非业务服务。
最后总结核心点,我们要将业务和非业务相关的东西剥离开来,各司其职,互不影响,这正符合现在流行的微服务理念。
推荐阅读:
【大厂】基于rabbitMQ消息中心技术方案
【干货】一篇文章讲透数据挖掘
【干货】微服务设计的基础知识【对话老王】聊聊那数据
【轻松话题】闲话程序员
【划划重点】论大数据中主数据的重要性
【谈大数据】CDH6.x学习笔记(角色简介)
加微信:wonter 发送:技术Q
医疗微信群:
加微信:wonter 发送:医疗Q
更多文章关注公众号:




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】