
图解Kafka Producer常用性能优化配置参数
1 基本参数
-
bootstrap.servers:Kafka broker服务器地址列表,
,分开,可不必写全,Kafka内部有自动感知Kafka broker的机制 -
client.dns.lookup:客户端寻找bootstrap地址的方式,支持两种方式:
- resolve_canonical_bootstrap_servers_only:依据bootstrap.servers提供的主机名(hostname),根据主机上的名称服务返回其IP地址的数组(InetAddress.getAllByName),然后依次获取inetAddress.getCanonicalHostName(),再建立tcp连接。一个主机可配置多个网卡,如果启用该功能,应该可以有效利用多网卡的优势,降低Broker的网络端负载压力。
- use_all_dns_ips:直接使用bootstrap.servers中提供的hostname、port创建tcp连接,默认选项。
-
compression.type:消息压缩算法,可选值:none、gzip、snappy、lz4、zstd,默认不压缩,建议与Kafka服务器配置的一样,当然Kafka服务端可配置的压缩类型为 producer,即采用与发送方配置的压缩类型。发送方与Broker 服务器采用相同的压缩类型,可有效避免在Broker服务端进行消息的压缩与解压缩,大大降低Broker的CPU使用压力。
-
client.id:客户端ID,如果不设置默认为producer-递增,强烈建议设置该值,尽量包含ip,port,pid
-
send.buffer.bytes:网络通道(TCP)的发送缓存区大小,默认128K
-
receive.buffer.bytes:网络通道(TCP)的接收缓存区大小,默认32K
-
reconnect.backoff.ms:重新建立链接的等待时长,默认50ms,属于底层网络参数,基本不关注
-
reconnect.backoff.max.ms:重建链接的最大等待时长,默认1s,连续两次对同一个连接建立重连,等待时间会在reconnect.backoff.ms的初始值上成指数级递增,但超过max后,将不再指数级递增
-
key.serializer:消息key的序列化策略,org.apache.kafka.common.serialization接口实现类,注意别导错包了
-
value.serializer:消息体序列化策略
-
partitioner.class:消息发送队列负载算法,默认 DefaultPartitioner,路由算法如下:
- 如指定 key ,则使用 key 的 hashcode 与分区数取模
- 如未指定 key,则轮询所有分区
-
interceptor.classes:拦截器列表,kafka运行在消息真正发送到broker之前对消息进行拦截加工
-
enable.idempotence:是否开启发送端的幂等,默认false
-
transaction.timeout.ms:事务协调器等待客户端的事务状态反馈的最大超时时间,默认60s
-
transactional.id:事务id,用于在一个事务中唯一标识一个客户端
2 性能优化常配参数
涉及到消息发送是如何工作的,本节首先将罗列参数,做简单说明,然后再给出运作图,进一步阐述其工作机制。
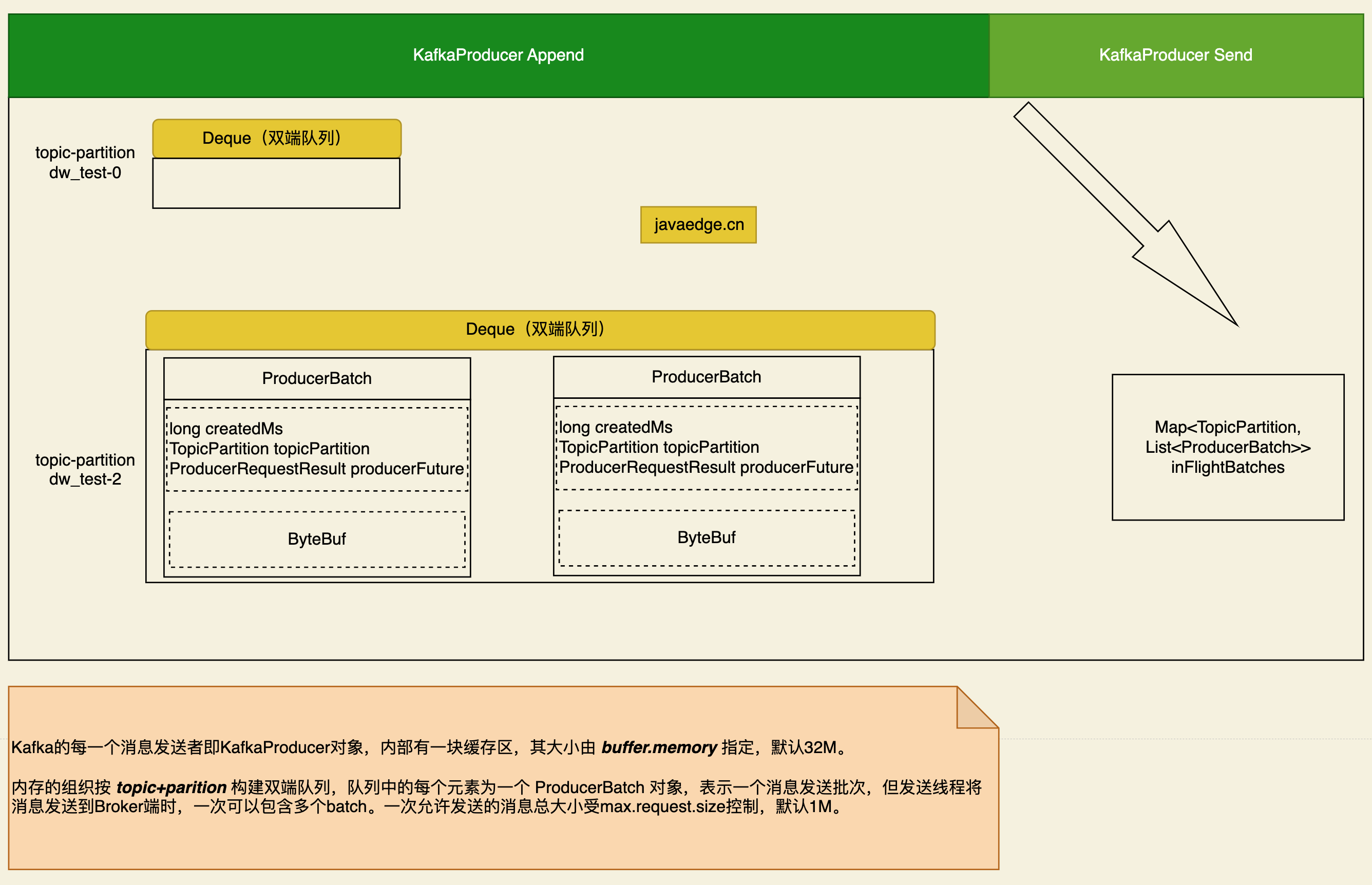
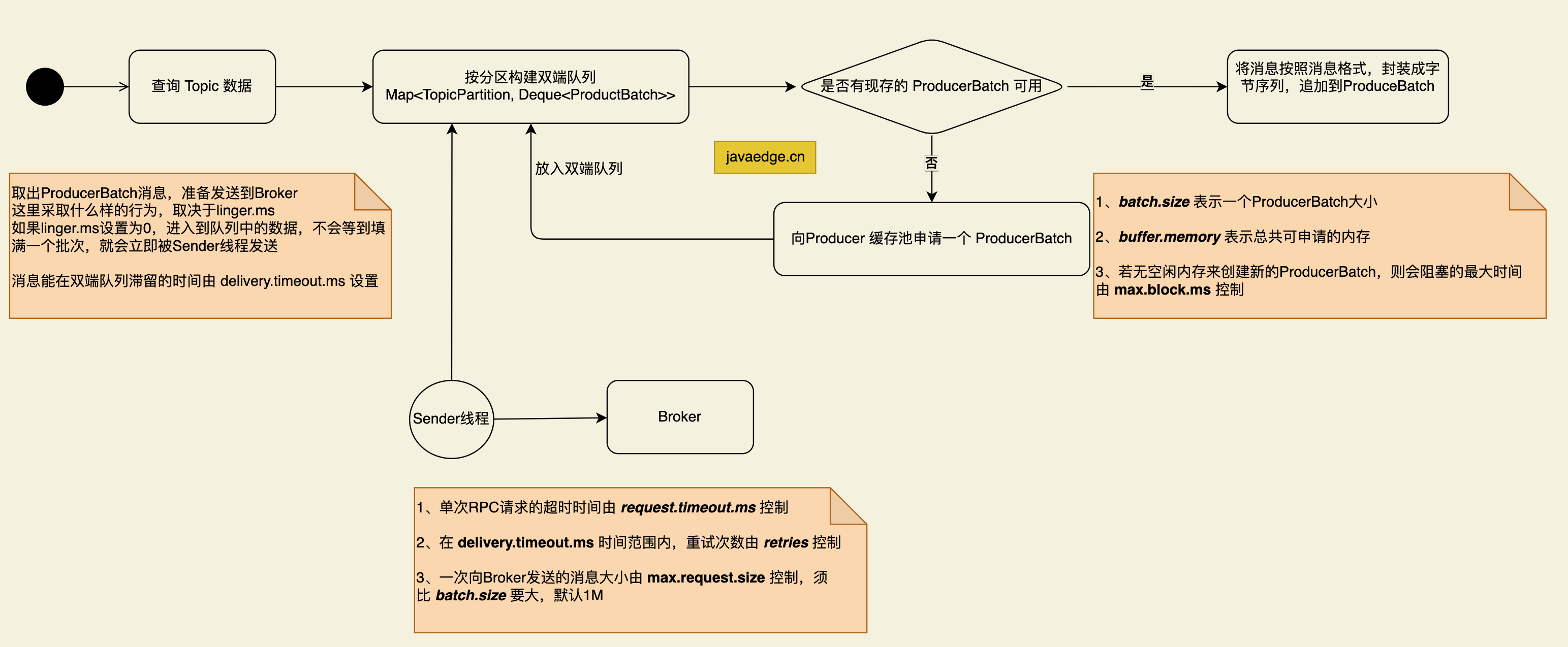
- buffer.memory
用于设置一个生产者(KafkaProducer)中缓存池的内存大小,默认为32M。 - max.block.ms
当消息发送者申请空闲内存时,如果可用内存不足的等待时长,默认为60s,如果在指定时间内未申请到内存,消息发送端会直接报TimeoutException,这个时间包含了发送端用于查找元信息的时间。 - retries
重试次数,Kafka Sender线程从缓存区尝试发送到Broker端的重试次数,默认为Integer.MAX_VALUE,为了避免无限重试,只针对可恢复的异常,例如Leader选举中这种异常就是可恢复的,重试最终是能解决问题的。 - acks
用来定义消息“已提交”的条件(标准),就是 Broker 端向客户端承偌已提交的条件,可选值如下: - 0
表示生产者不关心该条消息在 broker 端的处理结果,只要调用 KafkaProducer 的 send 方法返回后即认为成功,显然这种方式是最不安全的,因为 Broker 端可能压根都没有收到该条消息或存储失败。 - all 或 -1
表示消息不仅需要 Leader 节点已存储该消息,并且要求其副本(准确的来说是 ISR 中的节点)全部存储才认为已提交,才向客户端返回提交成功。这是最严格的持久化保障,当然性能也最低。 - 1
表示消息只需要写入 Leader 节点后就可以向客户端返回提交成功。 - batch.size
在消息发送端Kafka引入了批的概念,发送到服务端的消息通常不是一条一条发送,而是一批一批发送,该值用于设置每一个批次的内存大小,一个批次对应源码层级为ProducerBatch对象,默认为16K。 - linger.ms
该参数与batch.size配合使用。Kafka希望一个批次一个批次去发送到Broker,应用程序往KafkaProducer中发送一条消息,首先会进入到内部缓冲区,具体是会进入到某一个批次中(ProducerBatch),等待该批次堆满后一次发送到Broker,这样能提高消息的吞吐量,但其消息发送的延迟也会相应提高,试想一下,如果在某一个时间端,应用端发送到broker的消息太少,不足以填满一个批次,那岂不是消息一直无法发送到Broker端吗?
为了解决该问题,linger.ms参数应运而生。它的作用是控制在缓存区中未积满时来控制消息发送线程的行为。如果linger.ms 设置为 0表示立即发送,如果设置为大于0,则消息发送线程会等待这个值后才会向broker发送。有点类似于 TCP 领域的 Nagle 算法。 - delivery.timeout.ms
消息在客户端缓存中的过期时间,在Kafka的消息发送模型中,消息先进入到消息发送端的双端缓存队列中,然后单独一个线程将缓存区中的消息发送到Broker,该参数控制在双端队列中的过期时间,默认为120s,从进入双端队列开始计时,超过该值后会返回超时异常(TimeoutException)。 - request.timeout.ms
请求的超时时间,主要是Kafka消息发送线程(Sender)与Broker端的网络通讯的请求超时时间。 - max.request.size
Send线程一次发送的最大字节数量,也就是Send线程向服务端一次消息发送请求的最大传输数据,默认为1M。 - max.in.flight.requests.per.connection
设置每一个客户端与服务端连接,在应用层一个通道的积压消息数量,默认为5,有点类似Netty用高低水位线控制发送缓冲区中积压的多少,避免内存溢出。
3 图解核心数据结构
4 图解参数的作用时机
到底如何指导实际业务的性能优化参数,该调哪些参数?咱们下篇文章再叙。
文章转载自公众号:JavaEdge
参考:
本文由博客一文多发平台 OpenWrite 发布!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号