
钉钉消息已读、未读咋实现的嘞?
前言
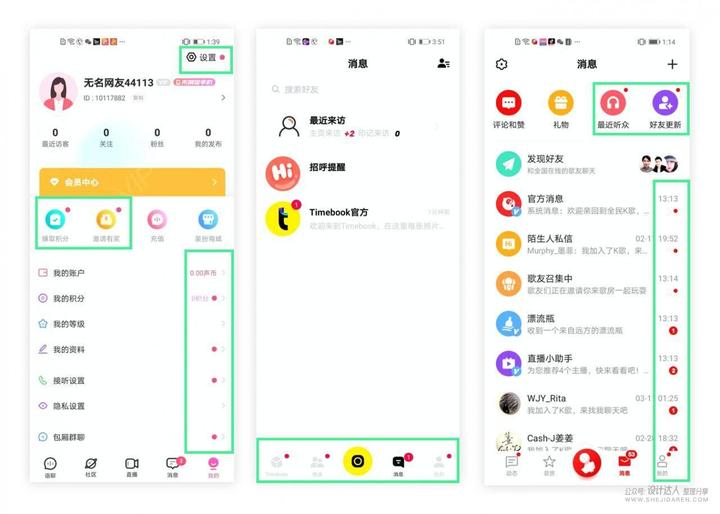
一款app,消息页面有:钱包通知、最近访客等各种通知类别,每个类别可能有新的通知消息,实现已读、未读功能,包括多少个未读,这个是怎么实现的呢?比如用户A访问了用户B的主页,难道用rabitmq给B发通知消息吗?量大了成本受得了吗?有没有成本低的方案呢
小谈
挺好的一个问题,可惜其他的回答要么是大而化之想当然,要么是顾左而言他,没有一个正经的回答。
这个是很常见的需求,在做这类需求的时候,首先要做的是,设计一个合适的业务模型,那么这个模型就是“对话模型”,
将问题中的"设置",“赚钱积分”,"最近听众","好友跟新","最近来访"当做一个“虚拟人”来处理,你跟"虚拟人"组成了一个"对话列表(msg_group)"
“虚拟人”与正常人的区别就是,虚拟人与你的对话是单向的,只能他向你发消息,你无法回复。
所有,判断有没有小红点,或者小红点的数字是多少,就是简单的获取你与虚拟人的对话的未读的消息的数量。
“最近来访”标签
当有人访问你主页的时候,后端会以这个“最近来访”虚拟人的身份给你发一条消息,不过消息里还有一个特殊标记,标明了来源。我们除了要拉取总量,还有不同来源消息的数量。当然,一个动作不一定只发一条消息,比如,图中下方有个金刚键"消息",它是所有消息的总和,所以,投递其他消息的时候,也要给它投递一次,不过它只展示一个未读数字,所以这个消息只需要一个msg_id即可,不需要消息payload。
前端怎么展示
看具体产品需求。
每个对话可以看作一个msg_group,它是一个消息的队列(注意,不是我们常说的消息队列),每条msg的msg_id都是有序递增的,至于msg_id只是队列内有序还是全局有序,就看你选择了,一般数据10亿以内没必要优化,发号器全局有序即可。这个队列有基本的信息:参与人(图中的例子只有2个,你和“虚拟人”),maximal_msg_id。
你只需要保存一个last_pull_msg_id或last_read_msg_id即可,在拉取信息的时候,带上这个last_msg_id即可。
当然,消息列表的存储,读取,就比较多样了。可以是MySQL,nosql,hbase,redis。一般我们是混合存储,特别老的存hbase,比较老的存mysq或nosql,新数据存redis。云厂商也有专门针对这类场景的存储产品。大多数情况,我们只需要一个数量,固定从maximal_id往前取,如果取到100条还没完,直接返回99+完事了。
实际上,图中的需求,比如“设置”,"隐私设置",是整个产品全局的,所以可以弄个简单的"广播消息模式",广播模式就是维持一个单向的消息的队列,所有的人都可以拉取这个队列的消息,只需要他们各位维护自己的last_id即可。
"已读和未读"。它包含两层意思,一个判否,即内容你是否读过,二是计数,即这个内容有多少人读过。
长尾原因
如果你用Redis存储,成本非常高,浪费非常严重。如果不用redis,一旦刷到历史数据,会非常非常慢。在这里bitmap肯定是搞不定的,因为bitmao需要加载全部数据,显然不可行。
这个时候,通常的策略是"[log record]"和"comb", 我们每产生一个动作,比如读,赞,收藏,就会产生一个log record( 取关,取消赞...也是一条独立的log record),我们由专门的大数据系统统一收集这些record,然后对多个维度的数据统计,将统计结果存起来,前端获取数据的时候,先从缓存取,取不到再到comb取。comb的数据规模是远远小于log record的,查询速度非常快。
log record因为不涉及查询,所以没必要用数据库,一般直接存hbase或cassandra这类廉价存储介质。
热门内容
用户互动非常活跃,所以在写入log record的时候,会直接同步更新缓存,但是缓存的数据并不保证十分准确,它只是迷惑用户的,准确的数据是以log record为准的,你在wb经常可以看热门内容的点赞数跟实际的数量不符。因为wb的缓存,独立的counter,实际的数据不同步。
本文由博客一文多发平台 OpenWrite 发布!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号