

写在开头
面试官:小伙子,JMM了解吗?
我:JMM(Java Memory Model),Java内存模型呀,学过的!
面试官:那能给我详细的聊一聊吗,越详细越好!
我:嗯~,确定越详细越好?起码得说一万字,您有时间听完?
面试官:你要是真能说一万字全是干货的话,我当场拍板要你,给你SSP!
我:这可是您说的,瞧好吧!
为了拿到一个SSP级别的Offer,我开始疯狂运转我的大脑,将过去背的八股文与自我理解总结相结合,展开了对JMM(Java内存模型)漫长的介绍,内容有点长,同志们保持耐心看完哈。
JMM诞生的背景
在这篇文章《关于Java并发多线程的一点思考》中我们提到过Java多线程存在的问题,其中有一个关于多线程的原子性、可见性、有序性问题,当时针对这个问题我们给出过如下解释:
“在一个Java程序或者说进程运行的过程中,会涉及到CPU、内存、IO设备,这三者在读写速度上存在着巨大差异:CPU速度-优于-内存的速度-优于-IO设备的速度。
为了平衡这三者之间的速度差异,达到程序响应最大化,计算机、操作系统、编译器都做出了自己的努力。
- 计算机体系结构:给 CPU 增加了缓存,均衡 CPU 和内存的速度差异;
- 操作系统:增加了进程与线程,分时复用 CPU,均衡 CPU 和 IO 设备的速度差异;
- 编译器:增加了指令执行重排序(这个也会带来另外的问题,我们在后面的学习中会提到),更好地利用缓存,提高程序的执行速度。
这种优化是充分必要的,但这种优化同时会给多线程程序带来原子性、可见性和有序性的问题。”
为了解决以上问题Java内存模型(JMM)应运而生,当然,早期的JMM存在着很多问题,比如非常容易消弱编译器的优化能力,但从JDK5开始,提出了JSR-133(Java Memory Model and Thread Specification Revision),用以规范和修订Java内存模型与线程,我们接下来所提及的JMM都是基于新规范的。
JMM如何解决问题
对于 Java 来说,你可以把 JMM 看作是 Java 定义的并发编程相关的一组规范,除了抽象了线程和主内存之间的关系之外,其还规定了从 Java 源代码到 CPU 可执行指令的这个转化过程要遵守哪些和并发相关的原则和规范,其主要目的是为了简化多线程编程,增强程序可移植性的。
开发者们可以利用这些规范,方便安全的使用多线程,甚至于不需要在乎它底层的原理,直接使用一些关键字和类(例如:volatile、synchronized、final,各种 Lock)就可以使多线程变得安全。
深刻理解JMM
为了更深刻的理解JMM,我们需要理解几个概念:Java内存区域、CPU缓存、指令重排序
Java内存模型与Java内存区域的区别?
这个问题是很多Java初学者容易搞混淆的,也是很多面试官在面试时喜欢考察的小知识点,虽然名字很相似,但它们的区别却很大。
Java内存模型: 主要针对的是多线程环境下,如何在主内存与工作内存之间安全地执行操作,包括变量的可见性、指令重排、原子操作等,旨在解决由于多线程并发编程带来的一些问题,它是一种规范或者说约束。
原子性:一个或者多个操作在 CPU 执行的过程中不被中断的特性;
可见性:一个线程对共享变量的修改,另外一个线程能够立刻看到;
有序性:程序执行的顺序按照代码的先后顺序执行;
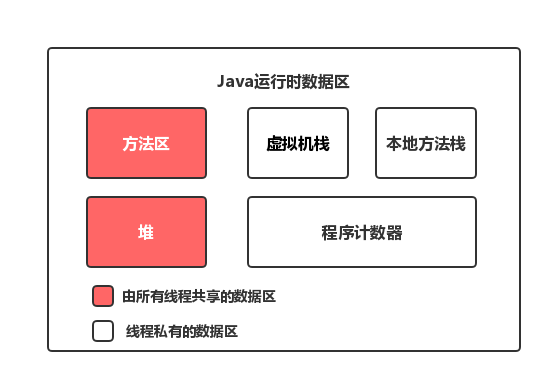
Java内存区域: 是指Java程序在JVM上运行时所流转的区域,因此也叫"Java运行时内存区域",主要包括以下几个部分(这里指JDK1.7,在1.8后方法区被元空间替代,在后面的JVM学习中会详细讲述):
方法区:存储了每一个类的结构信息,如运行时常量池、字段和方法数据、构造方法和普通方法的字节码内容。堆:几乎所有的对象实例以及数组都在这里分配内存。这是 Java 内存管理的主要区域。栈:每一个线程有一个私有的栈,每一次方法调用都会创建一个新的栈帧,用于存储局部变量、操作数栈、动态链接、方法出口等信息。所有的栈帧都是在方法调用和方法执行完成之后创建和销毁的。本地方法栈:与栈类似,不过本地方法栈为 JVM 使用到的 native 方法服务。程序计数器:每个线程都有一个独立的程序计数器,用于指示当前线程执行到了字节码的哪一行。
![image]()
CPU缓存
在上文中我们提到过CPU、内存、IO设备,这三者在读写速度存在差异,而CPU 缓存就是为了解决 CPU 处理速度和内存处理速度不对等的问题。

如上图为一个4核CPU的缓存架构图,在CPU缓存中一般分为3级,越靠近CPU的缓存,速度越快,价格越高,L1与L2为CPU私有,L3为多CPU共用缓存。
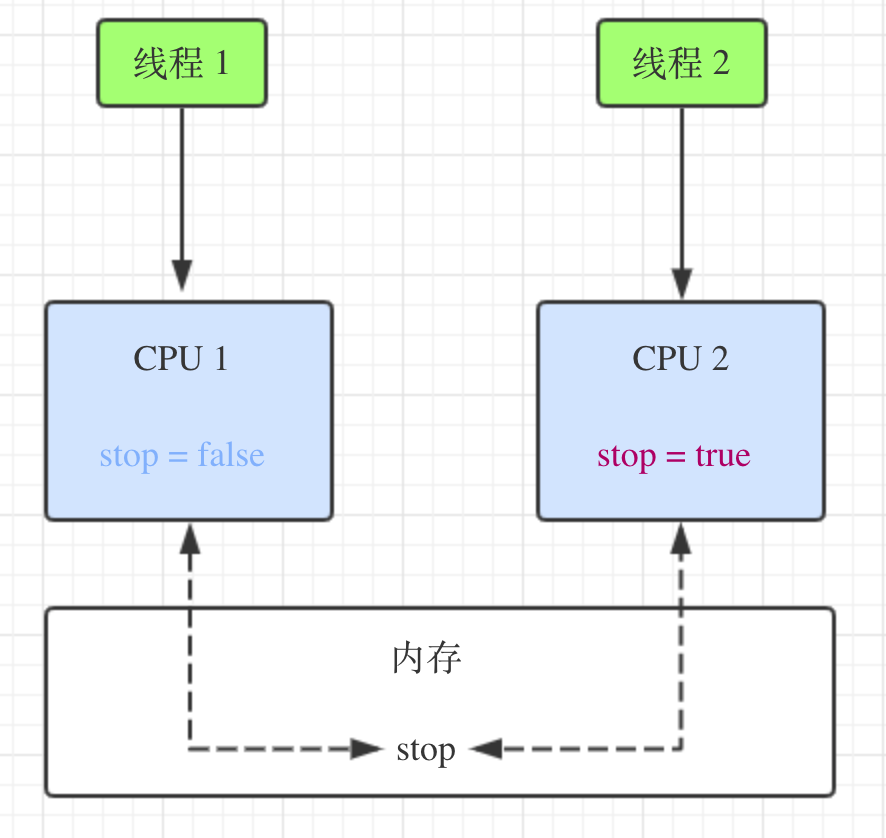
CPU缓存的工作方式:先将数据复制到CPU缓存中,查询时一级级向下查找,一旦找到结果就返回,不再向下遍历,若三级缓存都没查到,才会去主存(内存)中去查,然后开始运算,并将运算结果写回主存中,这时若发生多线程同时读写的话,就会存在可见性(内存缓存不一致)问题,我们写个小demo模拟一下。
【代码示例1】
public class Test {
//是否停止 变量
private static boolean stop = false;
public static void main(String[] args) throws InterruptedException {
//启动线程 1,当 stop 为 true,结束循环
new Thread(() -> {
System.out.println("线程 1 正在运行...");
while (!stop) ;
System.out.println("线程 1 终止");
}).start();
//休眠 1 秒
Thread.sleep(1000);
//启动线程 2, 设置 stop = true
new Thread(() -> {
System.out.println("线程 2 正在运行...");
stop = true;
System.out.println("设置 stop 变量为 true.");
}).start();
}
}
输出:
线程 1 正在运行...
线程 2 正在运行...
设置 stop 变量为 true.
原因:
我们会发现,线程1运行起来后,休眠1秒,启动线程2,可即便线程2把stop设置为true了,线程1仍然没有停止,这个就是因为 CPU 缓存导致的可见性导致的问题。线程 2 设置 stop 变量为 true,线程 1 在 CPU 1上执行,读取的 CPU 1 缓存中的 stop 变量仍然为 false,线程 1 一直在循环执行。
解决办法:
JMM告诉我们可以通过 volatile、synchronized、Lock接口、Atomic 类型保障可见性;还有一种就是在缓存与主存之间增加缓存一致性协议,如MSI,MESI等协议,协议包括CPU 高速缓存与主内存交互的时候需要遵守的原则和规范!
这个协议今天就不展开了,后面找时间再单独更新一篇,毕竟在把它整出来,面试官没耐心听下去了。😄
指令重排序
啥是指令重排序呢?我们在给出概念之前,先举个小例子
a = b + c;
d = e - f ;
现在有一个求和与一个求差操作,理论上,我们按照顺序执行的话,代码需要先将b、c加载进来,然后执行add(b,c)进行求和,然后在加载e、f,再执行sub(e,f)进行求差,但这样会有个问题,不管是求和还是求差,都需要等参数装载完成才能进行,这样的话,后续的操作均会停顿,对于高速运行的CPU来说,停顿意味着浪费,意味着低性能。
那么我们可以在执行顺序上进行优化,在加载b、c时将e、f加载进来,这样后面的求和求差就减少了停顿时间,提升了效率,而这,就是指令重排序的意思所在!
因此,我们结合这个小例子给出指令重排序的概念:为了充分利用资源,提升程序运行的速度。
指令重排一般分为以下三种:
- 编译器优化重排:编译器在不改变单线程程序语义的前提下,重新安排语句的执行顺序。
- 指令并行重排:现代处理器采用了指令级并行技术来将多条指令重叠执行。如果不存在数据依赖性(即后一个执行的语句无需依赖前面执行的语句的结果),处理器可以改变语句对应的机器指令的执行顺序。
- 内存系统重排:由于处理器使用缓存和读写缓存冲区,这使得加载(load)和存储(store)操作看上去可能是在乱序执行,因为三级缓存的存在,导致内存与缓存的数据同步存在时间差。
Java 源代码会经历 编译器优化重排 —> 指令并行重排 —> 内存系统重排 的过程,最终才变成操作系统可执行的指令序列。在单线程串行下,指令重排序能够保证语义一致性,但在多线程下就会出现意想不到的问题,我们同样写个小demo去复现一下。
【代码示例2】
public class Test {
static int x;//静态变量 x
static int y;//静态变量 y
public static void main(String[] args) throws InterruptedException {
Set<String> valueSet = new HashSet<String>();//记录出现的结果的情况
Map<String, Integer> valueMap = new HashMap<String, Integer>();//存储结果的键值对
//循环 1万次,记录可能出现的 v1 和 v2 的情况
for (int i = 0; i <10000; i++) {
//给 x y 赋值为 0
x = 0;
y = 0;
valueMap.clear();//清除之前记录的键值对
Thread t1 = new Thread(() -> {
int v1 = y;//将 y 赋值给 v1 ----> Step1
x = 1;//设置 x 为 1 ----> Step2
valueMap.put("v1", v1);//v1 值存入 valueMap 中 ----> Step3
}) ;
Thread t2 = new Thread(() -> {
int v2 = x;//将 x 赋值给 v2 ----> Step4
y = 1;//设置 y 为 1 ----> Step5
valueMap.put("v2", v2);//v2 值存入 valueMap 中 ----> Step6
});
//启动线程 t1 t2
t1.start();
t2.start();
//等待线程 t1 t2 执行完成
t1.join();
t2.join();
//利用 Set 记录并打印 v1 和 v2 可能出现的不同结果
valueSet.add("(v1=" + valueMap.get("v1") + ",v2=" + valueMap.get("v2") + ")");
System.out.println(valueSet);
}
}
}
输出:
...
[(v1=1,v2=0), (v1=0,v2=0), (v1=0,v2=1)]
[(v1=1,v2=0), (v1=0,v2=0), (v1=0,v2=1)]
[(v1=1,v2=0), (v1=0,v2=0), (v1=0,v2=1)]
[(v1=1,v2=0), (v1=0,v2=0), (v1=0,v2=1)]
...
v1=0,v2=0 的执行顺序是 Step1 和 Step 4 先执行
v1=1,v2=0 的执行顺序是 Step5 先于 Step1 执行
v1=0,v2=1 的执行顺序是 Step2 先于 Step4 执行
v1=1,v2=1 出现的概率极低,就是因为 CPU 指令重排序造成的。Step2 被优化到 Step1 前,Step5 被优化到 Step4 前,至少需要成立一个。
解决办法:
在 Java 中,volatile 关键字可以禁止指令进行重排序优化。Happens-Before同样也可以,接下来,我们就走进JMM的世界,是探索Happens-Before的奥秘!
JMM & Happens-Before
在JSR-133(新版Java内存模型)中,定义了Happens-Before(先行发生)原则,用于保证程序在执行过程中的可见性和有序性。
那么它具体的编程思想是什么呢?简单两句话就可以概括!
- 为了性能最大化,在不改变程序执行结果的前提下,对编译器和处理器的约束越少越好,在这个维度上他们可以任意重排序;
- 对于会改变程序执行结果的重排序,JMM 要求编译器和处理器必须禁止这种重排序。
在之前推荐阅读《Java并发编程的艺术》这本书中,有这样的一个示意图,个人感觉非常形象!
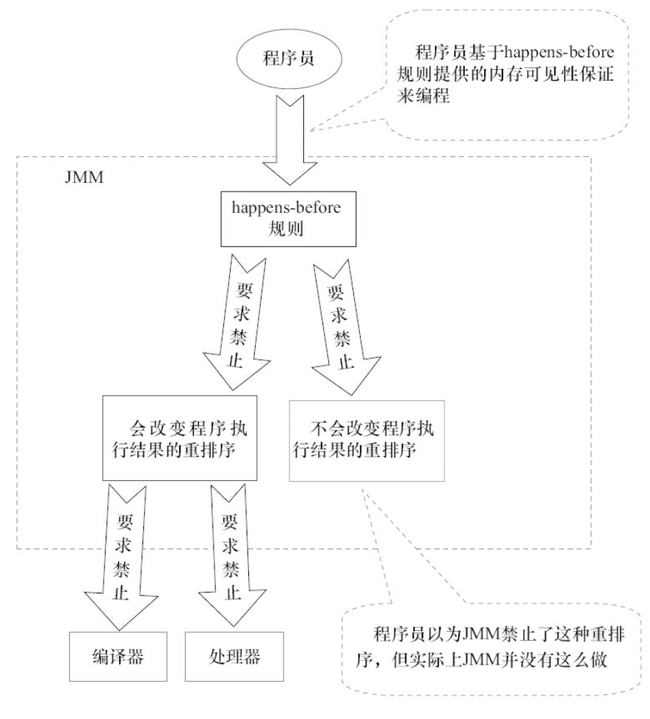
在JMM中对Happens-Before规则进行了定义,我们还是先用一张图(同样是上图的书籍中示意图)展开描述。

所谓的排序规则是指 ① 如果一个操作 happens-before 另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前;② 两个操作之间存在 happens-before 关系,并不意味着 Java 平台的具体实现必须要按照 happens-before 关系指定的顺序来执行。如果重排序之后的执行结果,与按 happens-before 关系来执行的结果一致,那么 JMM 也允许这样的重排序。
知识点补充:happens-before 重要规则
1、程序顺序规则:一个线程内,按照代码顺序,书写在前面的操作 happens-before 于书写在后面的操作;
2、监视器锁规则:对一个锁的解锁,happens-before 于随后对这个锁的加锁。
3、volatile 变量规则:对一个 volatile 变量的写操作 happens-before 于后面对这个 volatile 变量的读操作。说白了就是对 volatile 变量的写操作的结果对于发生于其后的任何操作都是可见的。
4、传递规则:如果 A happens-before B,且 B happens-before C,那么 A happens-before C;
5、start 规则:如果线程 A 执行操作 ThreadB.start()启动线程 B,那么 A 线程的 ThreadB.start()操作 happens-before 于线程 B 中的任意操作。
6、join 规则:如果线程 A 执行操作 ThreadB.join()并成功返回,那么线程 B 中的任意操作 happens-before 于线程 A 从 ThreadB.join()操作成功返回。
总结
Java内存模型讲到这里,也就差不多讲完了,其实中间还有缓存一致性协议、JSR-133文档 、volatile等关键字可以展开说一说,但那样篇幅太长,而且内容多乏味,就一笔带过了,感兴趣的小伙伴自己去网上搜一些博文看看吧。
结尾彩蛋
如果本篇博客对您有一定的帮助,大家记得留言+点赞+收藏呀。原创不易,转载请联系Build哥!

如果您想与Build哥的关系更近一步,还可以关注“JavaBuild888”,在这里除了看到《Java成长计划》系列博文,还有提升工作效率的小笔记、读书心得、大厂面经、人生感悟等等,欢迎您的加入!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号