
进入后端Java行业前明白个道理:程序员解决的问题,大多不是程序问题
前言
很多人都说,程序员很辛苦,与这个角色联系在一起的词儿,通常是忙碌、加班、熬夜等。作为程序员,我们将其看作一个值得全情投入的职业,希望能够把精力放在设计算法、改进设计、优化系统这些具有创造性与成就感的本职工作上。
但现实情况却是,许多人因为一些“意外”,陷入了无休止的忙碌,比如:
- 你辛辛苦苦写的代码还没上线,产品经理就告诉你需求变了;
- 你拼命加班只因错估了工作量,自己造的“孽”,含着泪也要搞定;
- 你累死累活做出来的东西和要求不符,只能从头再来;
- 你大面积地修改代码只是因为设计糟糕,无法适应新的需求变化;
……
诸如此类,不胜枚举。我们很辛苦,但耗费我们大量时间和精力去应付的工作,并不是技术工作,反而是这些看似很“不值当”的事儿。
为什么会这样?
在软件行业里有一本名著叫《人月神话》,其中提到两个非常重要的概念:本质复杂度(Essential Complexity)和偶然复杂度(Accident Complexity)。
简单来说,本质复杂度就是解决一个问题时,无论怎么做都必须要做的事,而偶然复杂度是因为选用的做事方法不当,而导致要多做的事。
比如你要做一个网站,网站的内容是你无论如何都要写的,这就是“本质复杂度”。而如果今天你还在用汇编写一个网站,效率是不可能高起来的,因为你选错了工具。这类选错方法或工具而引发的问题就是“偶然复杂度”。
这以至于我意识到一个事实:大部分程序员忙碌解决的问题,都不是程序问题,而是由偶然复杂度导致的问题。 换句话说,只要选择了正确的做事方法,减少偶然复杂度带来的工作量,就算是软件开发是可以有条不紊进行的。
不管是想转行做前端亦或者是毕业参加前端工作的小伙伴们,除了技术上的掌握,这方面的业务能力、问题解决能力也要加强。当然我们只有先面试通过了再去考虑这些问题,所以小编分享一份详细又全面的面试题,让你事半功倍
小编在此分享一份36W字的面试宝典,内容涵盖:基础&进阶篇字符串&集合面试题汇总、.Java并发编程、JVM、数据结构与算法、网络协议、数据库、MySQL、52条SQL性能优化策略、一千行SQL命令、Redis、MongoDB、Spring(共485页,36W字)点击这就可以领取完整版PDF后端Java全面面试题资料喔。
如果你觉得自己学习效率低,缺乏正确的指导,可以加入资源丰富,学习氛围浓厚的技术圈一起学习交流吧!
[JAVA进阶群]群内有许多来自一线的技术大牛,也有在小厂或外包公司奋斗的码农,我们致力打造一个平等,高质量的JAVA交流圈子,不一定能短期就让每个人的技术突飞猛进,但从长远来说,眼光,格局,长远发展的方向才是最重要的。
学习资料
Java必问知识点精华合集
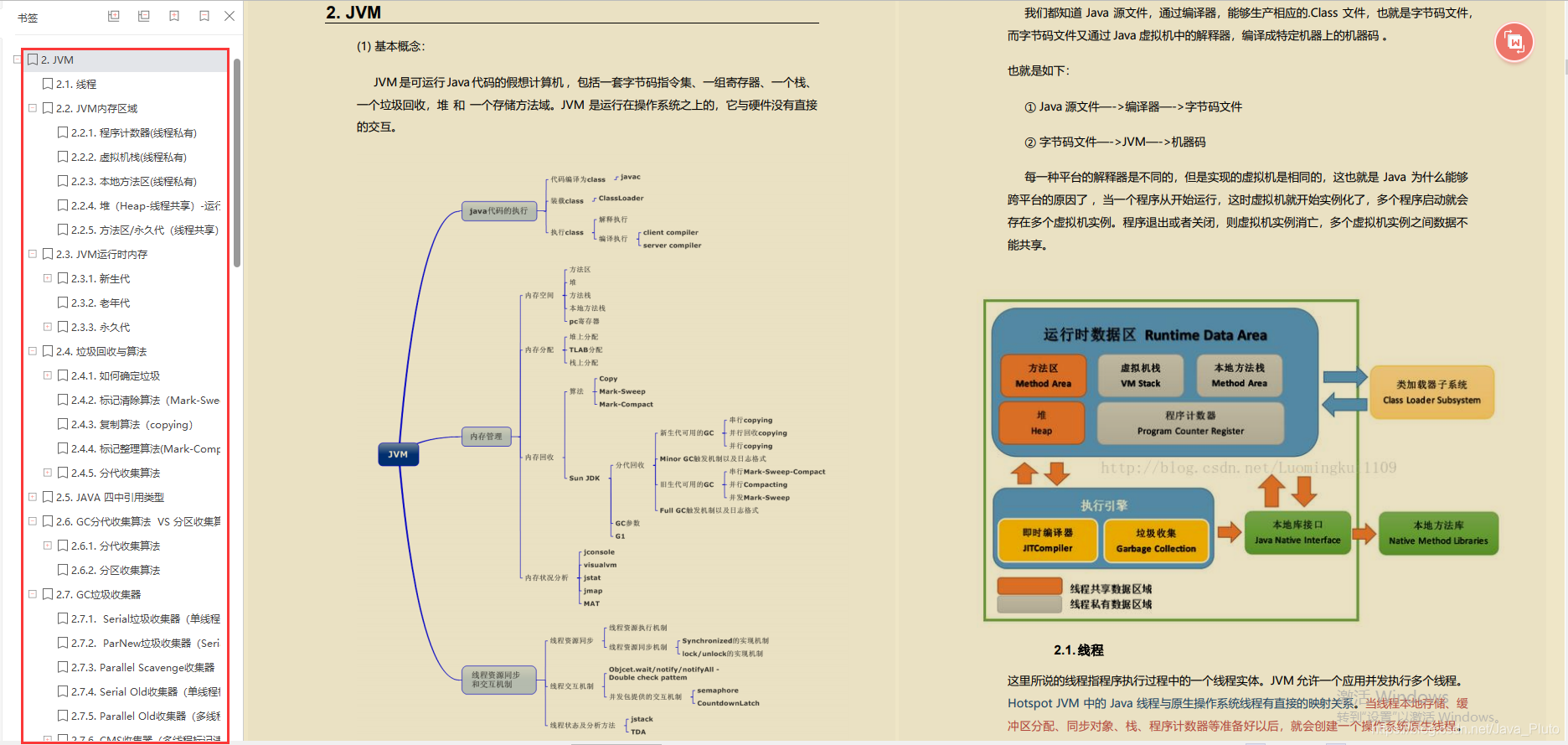
JVM
- 线程
- JVM内存区域
- JVM运行时内存
- 垃圾回收与算法
- JAVA四中引用类型
- GC分代收集算法VS分区收集算法
- GC垃圾收集器
- JAVA IO/NIO
- JVM类加载机制
![]()
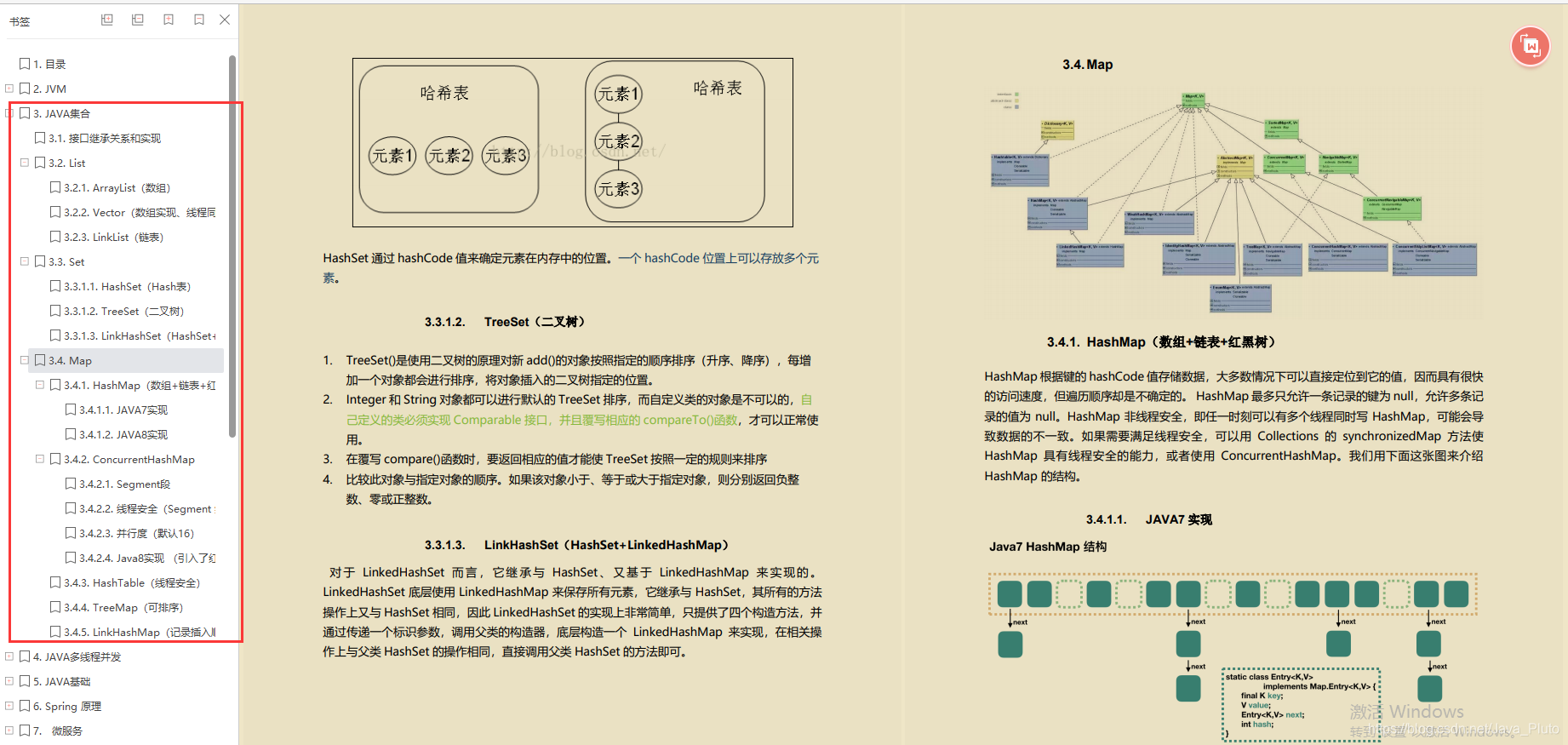
Java集合
-
接口继承关系和实现
-
List
Arayist (数组)
Vector (数组实现、线程同步)
Linklist (链表) -
set
HahSet Cah陶)
TreeSet (仁叉树)
LnkHashSet(HashSet+ LinkedHashMap) -
Map
HashMap (数组+链表+红黑树)
ConcurrentHashMap
HashTable (线程安全)
TreeMap (可排序)
LinkHashMap (记录插入顺序)
![]()
JAVA多线程并发
- JAVA并发知识库
- JAVA线程实现/创建方式
- 4种线程池
- 线程生命周期(状态)
- 终止线程4种方式
- sleep与wait区别
- start与run区别
- JAVA后台线程
- JAVA锁
- 线程基本方法
- 线程上下文切换
- 同步锁与死锁
- 线程池原理
- JAVA阻塞队列原理
- CyclicBarrier. CountDownlatch、 Semaphore的用法
- volatile关键字的作用 (变量可见性、禁止重排序)
- 如何在两个线程之间共享数据
- ThreadLocal作用(线程本地存储)
- synchronized和ReentrantLock的区别
- ConcurrentHashMap并发
- Java中用到的线程调度
- 进程调度算法
- 什么是CAS (比较并交换-乐观锁机制-锁自旋)
- 什么是AQS (抽象的队列同步器)
![]()

Java基础
- JAVA异常分类及处理
- JAVA反射
- JAVA注解
- JAVA内部类
- JAVA泛型
- JAVA序列化创建可复用的Java对象
- JAVA复制
![]()

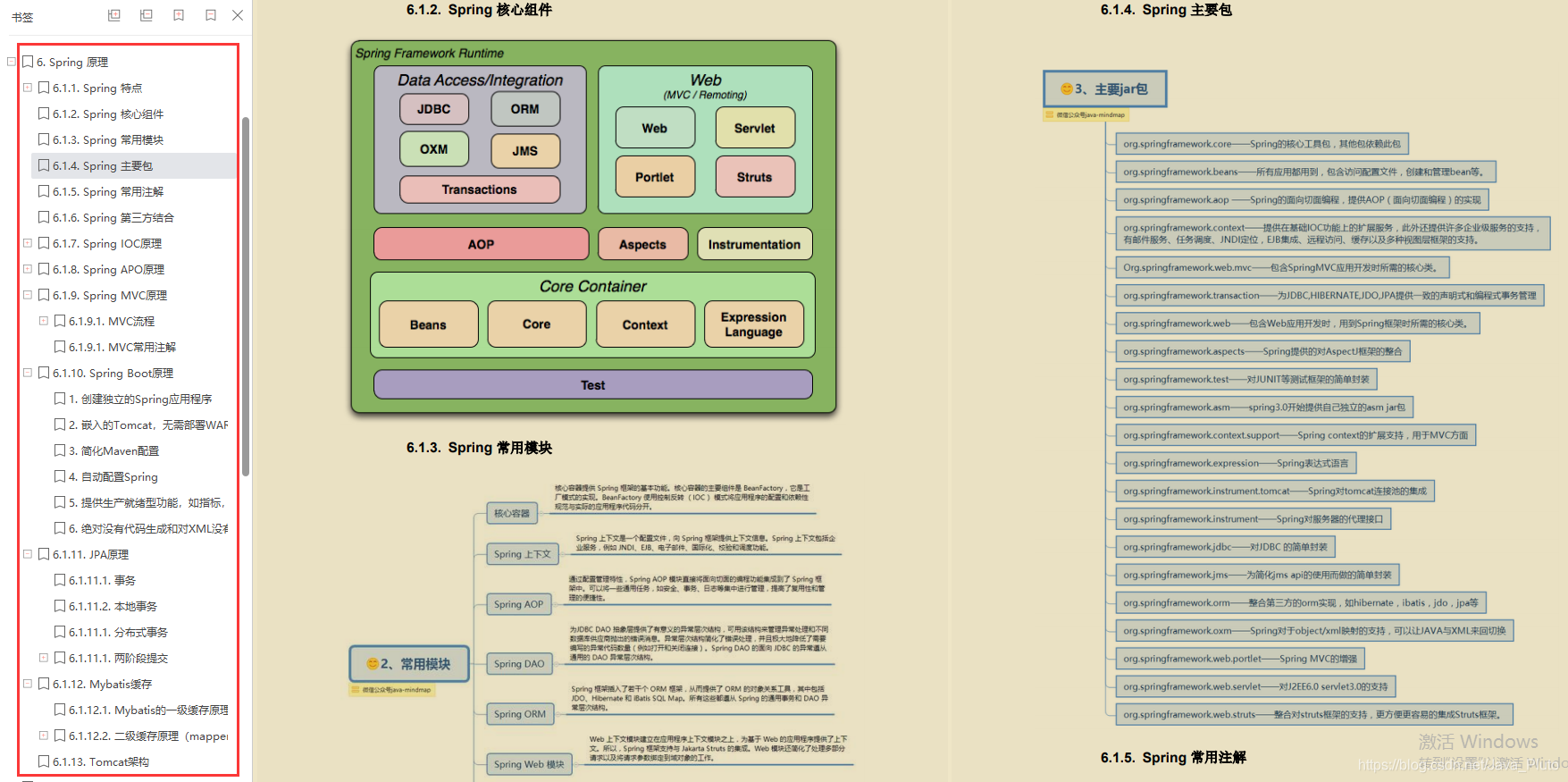
Spring原理
- Spring特点
- Spring核心组件
- Spring常用模块
- Spring主要包
- Spring常用注解
- Spring第三方结合
- Spring I0C原理
- Spring APO原理
- Spring MVC原理
- Spring Boot原理
- JPA原理
- Mybatis缓存
- Tomcat架构
![]()
如果你觉得自己学习效率低,缺乏正确的指导,可以加入资源丰富,学习氛围浓厚的技术圈一起学习交流吧!**
[JAVA进阶群]群内有许多来自一线的技术大牛,也有在小厂或外包公司奋斗的码农,我们致力打造一个平等,高质量的JAVA交流圈子,不一定能短期就让每个人的技术突飞猛进,但从长远来说,眼光,格局,长远发展的方向才是最重要的。
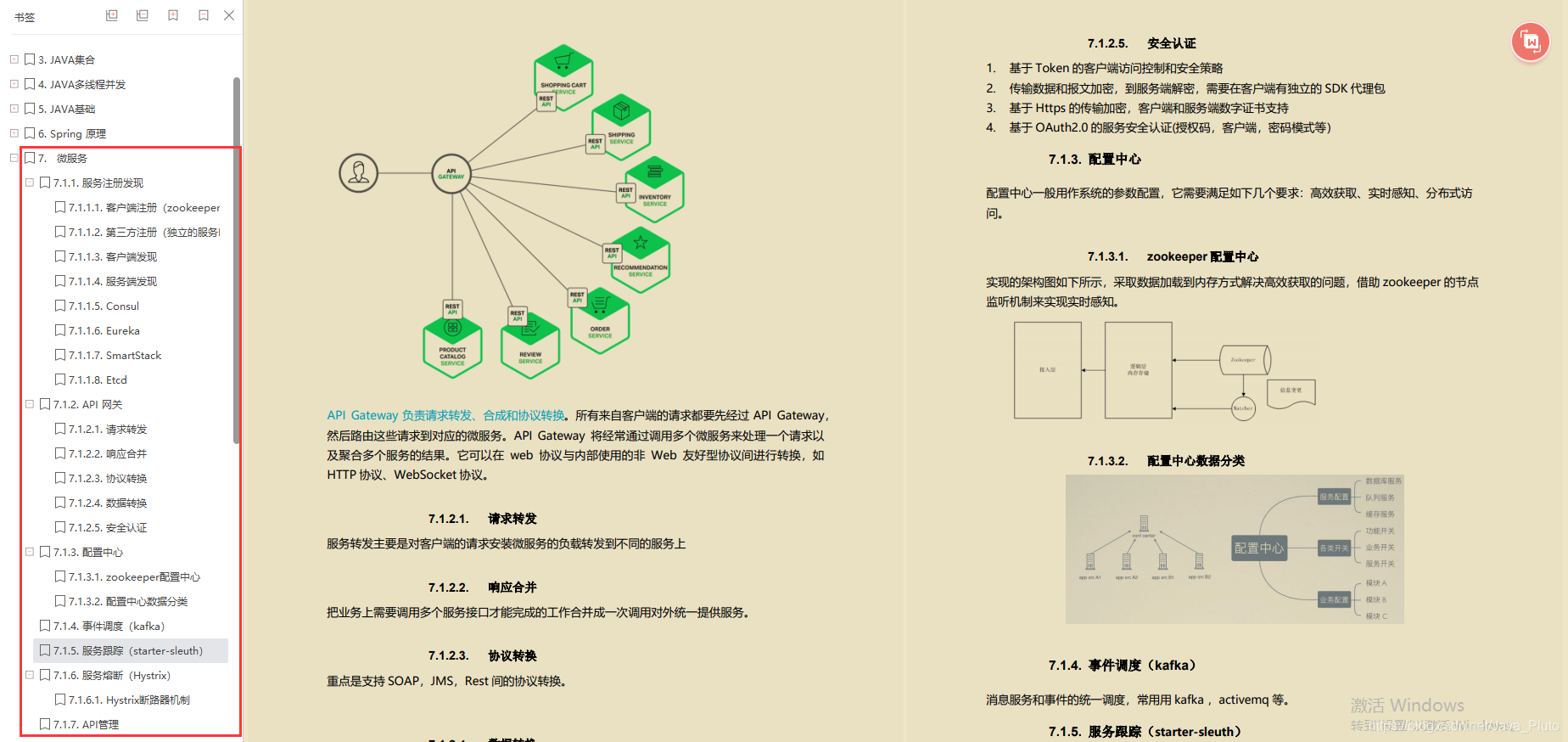
微服务
- 服务注册发现
客户端注册(zookeeper)
第三方注册(独立的服务Registrar)
客户端发现
服务端发现
Consul
Eureka
SmartStack
Etcd - API网关
请求转发
响应合并
协议转换
数据转换.
安全认证 - 配置中心
zookeeper配置中心
配置中心数据分类 - 事件调度(kafka)
- 服务跟踪(starter-sleuth)
Hystrix断路器机制 - 服务熔断(Hystrix)
- API管理
![]()
Netty与RPC
- Netty原理
- Netty高性能
多路复用通讯方式
异步通讯NIO
零拷贝(DIRECT BUFFERS使用堆外直接内存)
内存池(基于内存池的缓冲区重用机制) - Netty RPC实现
概念
关键技术
核心流程 - RMI实现方式
实现步骤 - Protoclol Buffer
特点 - Thrift
![]()

网络
-
网络7层架构
-
TCP/IP原理.
网络访问层(Network Access Layer)
网络层(Internet Layer)
传输层(Tramsport Layer-TCP/UDP)
应用层(Application Layer) -
TCP三次握手/四次挥手
数据包说明
三次握手
四次挥手 -
HTTP原理
传输流程
HTTP状态
HTTPS -
CDN原理
分发服务系统
负裁均衡系统:
管理系统:
![]()

日志
- SIf4j
- Log4j
- LogBack
LogBack优点 - ELK
![]()

Zookeeper
- Zookeeper概念
- Zookeeper角色
- Zookeeper工作原理(原子广播)
- Znode有四种形式的目录节点
![]()

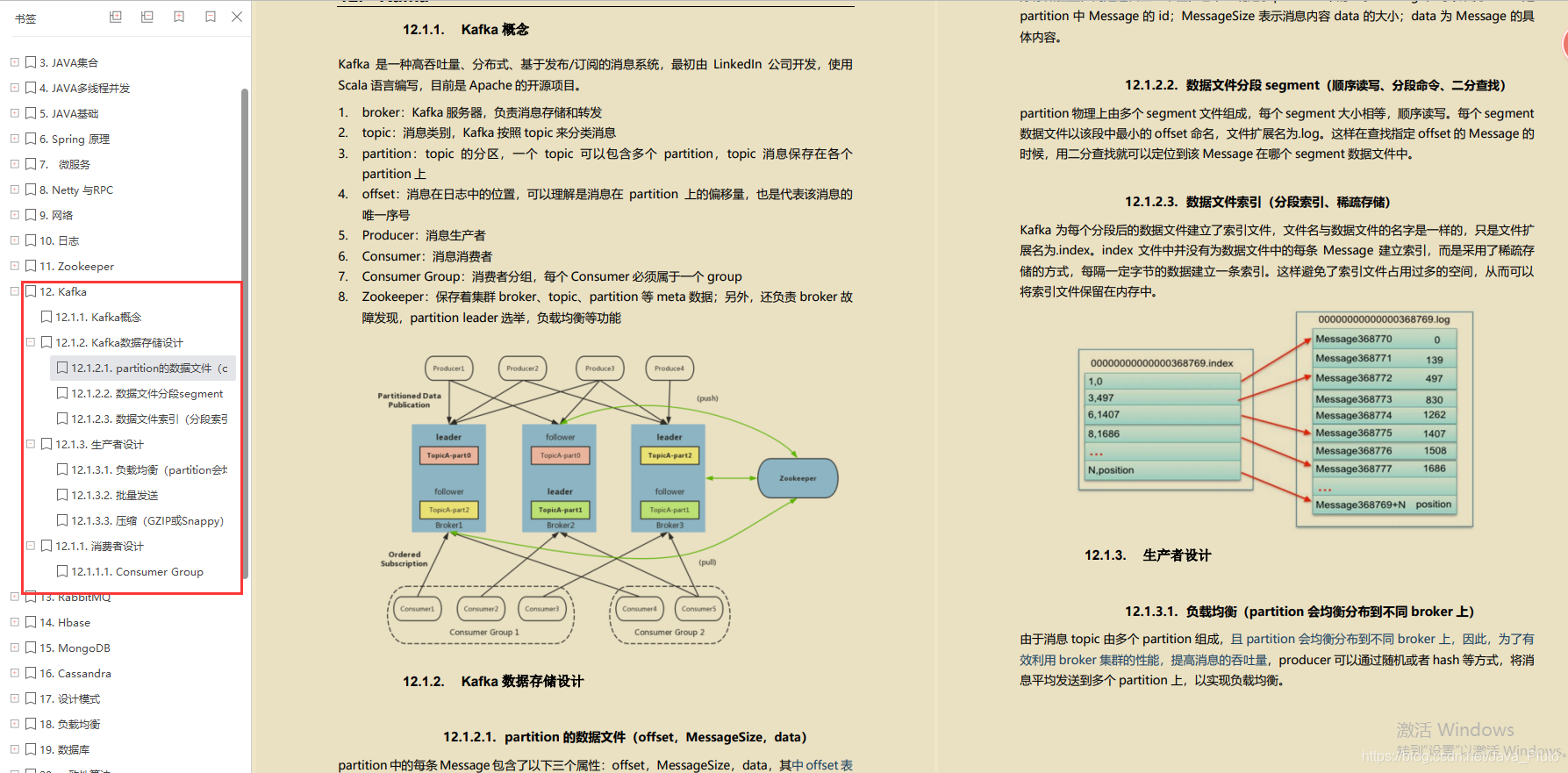
Kafka
- Kafka概念
- Kafka数据存储设计
- 生产者设计
- 消费者设计
![]()
RabbitMQ
- 概念
- RabbitMQ架构
- Exchange类塑
![]()

Hbase
- 概念
- 列式存储
- Hbase核心概念
- Hbase核心架构
- Hbase的写逻辑
- HBase vs Cassandra
![]()

MongoDB
- 概念
- 特点
![]()

Cassandra
- 概念
- 数据模型
- Cassandra- 致Hash和虚拟节点)
- Gossip协议
- 数据复制
- 数据写请求和协调者
- 数据读请求和后台修复
- 数据存储(CommitLog. MemTable、 SSTable)
- 二级索引(对要索引的value 摘要,生成RowKey)
- 数据读写

设计模式
- 设计原则
- 厂方法模式
- 抽象工厂模式
- 单例模式
- 建造者模式
- 原型模式
- 适配器模式
- 装饰器模式
- 代理模式
- 外观模式
- 桥接模式
- 组合模式
- 享元模式
- 模板方法模式
- 观察者模式
- 迭代子模式
- 责任链模式
- 命令模式
- 备忘录模式
- 状态模式
- 访问者模式
- 中介者模式
- 解释器模式
负载均衡
- 四层负载均衡vs七层负载均横
- 负载均衡算法/策略 LVS
- Keepalive
- Nginx反向代理负载均衡
- HAProxy
![]()

数据库
- 存储引擎
- 索引
- 数据库三范式.
- 数据库是事务.
- 存储过程(特定功能的SQL语句集)
- 触发器(-段能自动执行的程序)
- 数据库并发策略
- 数据库锁
- 基于Redis分布式锁
- 分区分表
- 两阶段提交协议
- 三阶段提交协议
- 柔性事务
- CAP
![]()

一致性算法
- Paxos
- Zab
- Raft
- NWR
- Gossip
- -致性Hash
![]()

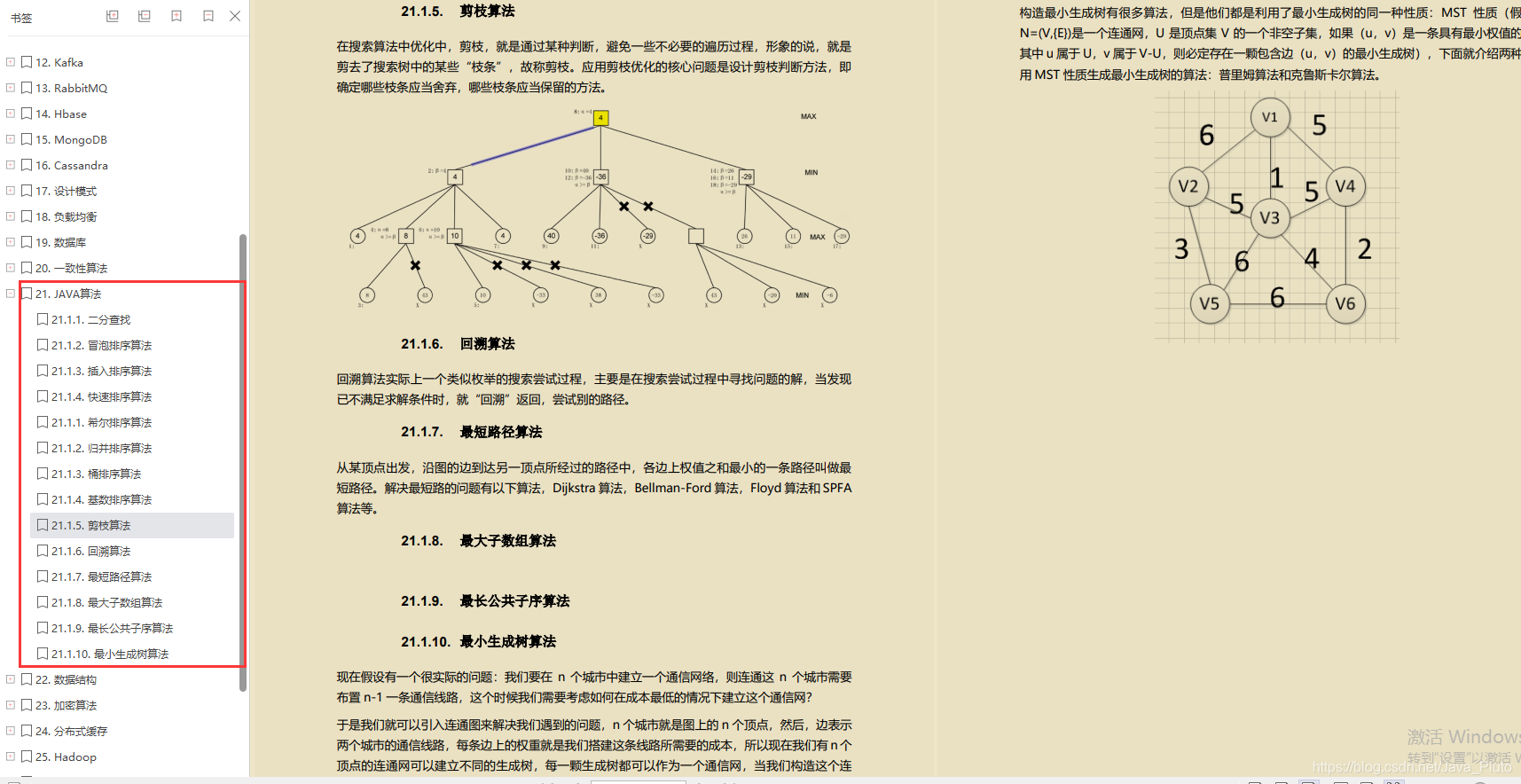
JAVA算法
- 二分查找
- 冒泡排序算法
- 插入排序算法
- 快速排序算法
- 希尔排序算法
- 归并排序算法
- 桶排序算法
- 基数排序算法
- 剪枝算法
- 回溯算法
- 最短路径算法
- 最大子数组算法
- 最长公共子序算法
- 最小生成树算法
![]()
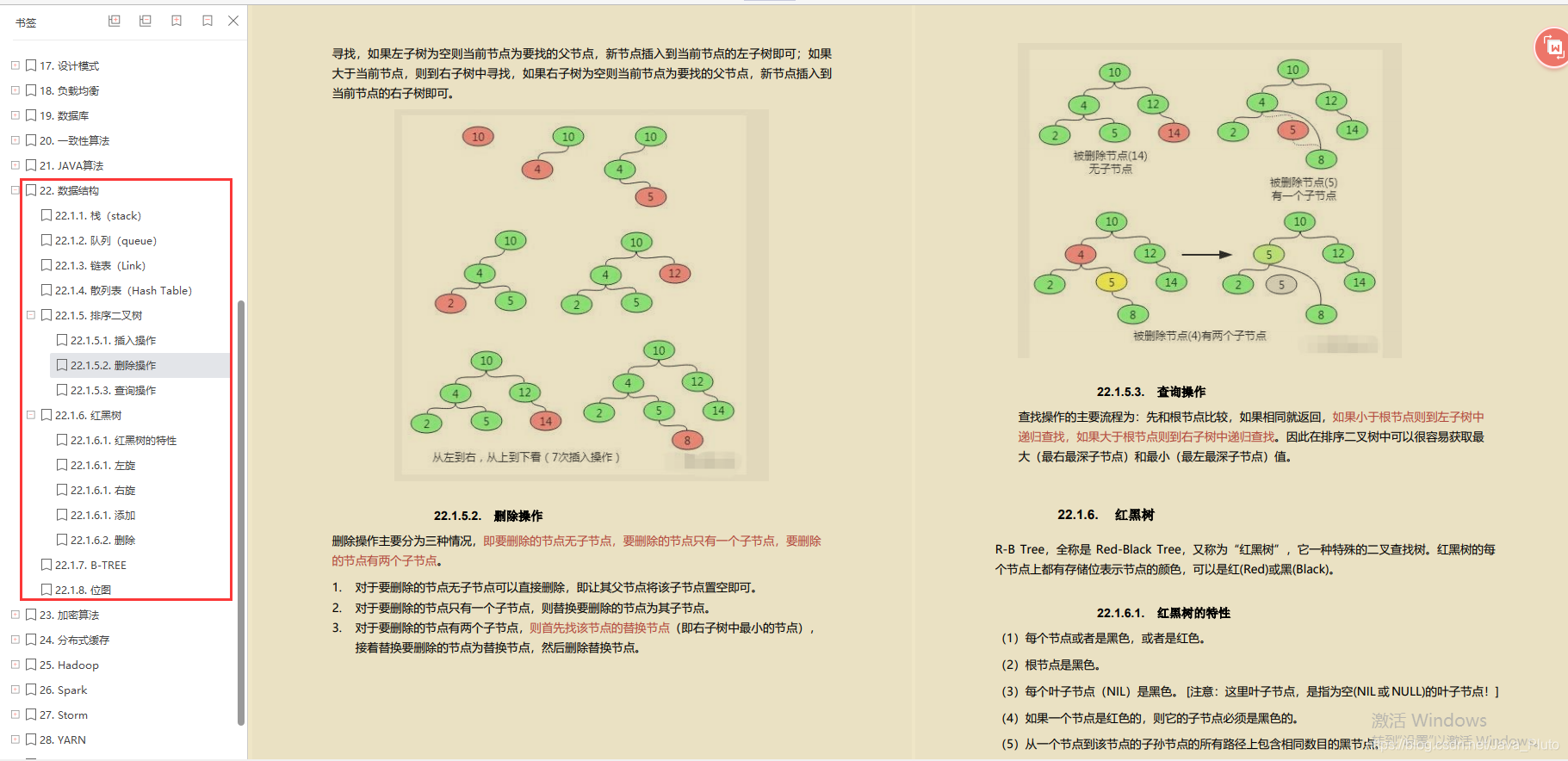
数据结构
- 栈(stack)
- 队列(queue)
- 链表(Link)
- 散列表(Hash Table)
- 排序二叉树
- 红黑树
- B-TREE
- 位图
![]()
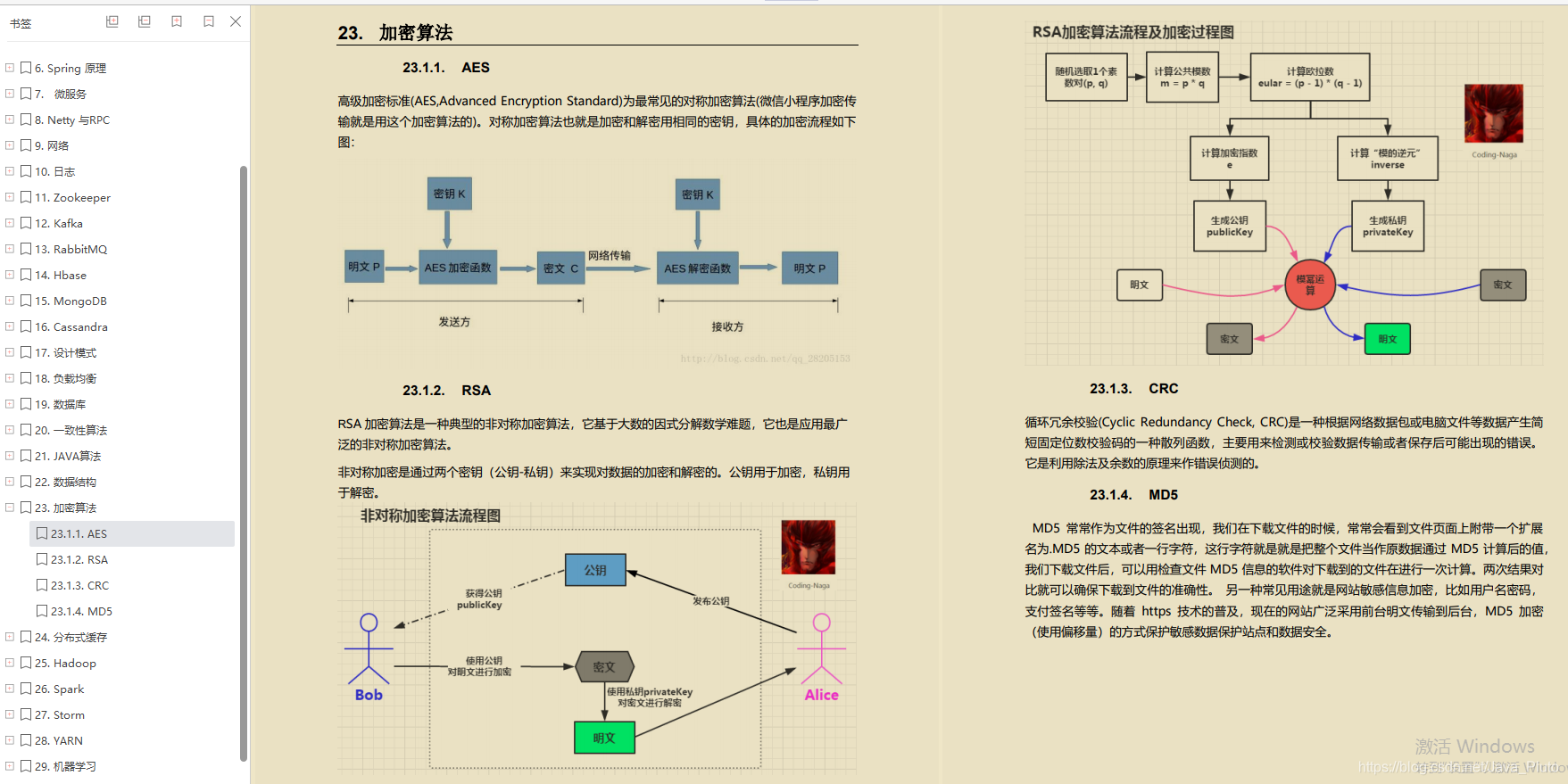
加密算法
- AES
- RSA
- CRC
- MD5
![]()
分布式缓存
- 缓存雪崩
- 缓存穿透
- 缓存预热
- 缓存更新
- 缓存降级
Hadoop
- 概念
- HDFS
- MapReduce
- Hadoop
- MapReduce作业的生命周期
![]()

Spark
- 概念
- 核心架构
- 核心组件
- SPARK编程模型
- SPARK计算模型
- SPARK运行流程
- SPARK
- RDD流程
- SPARK
- RDD
![]()
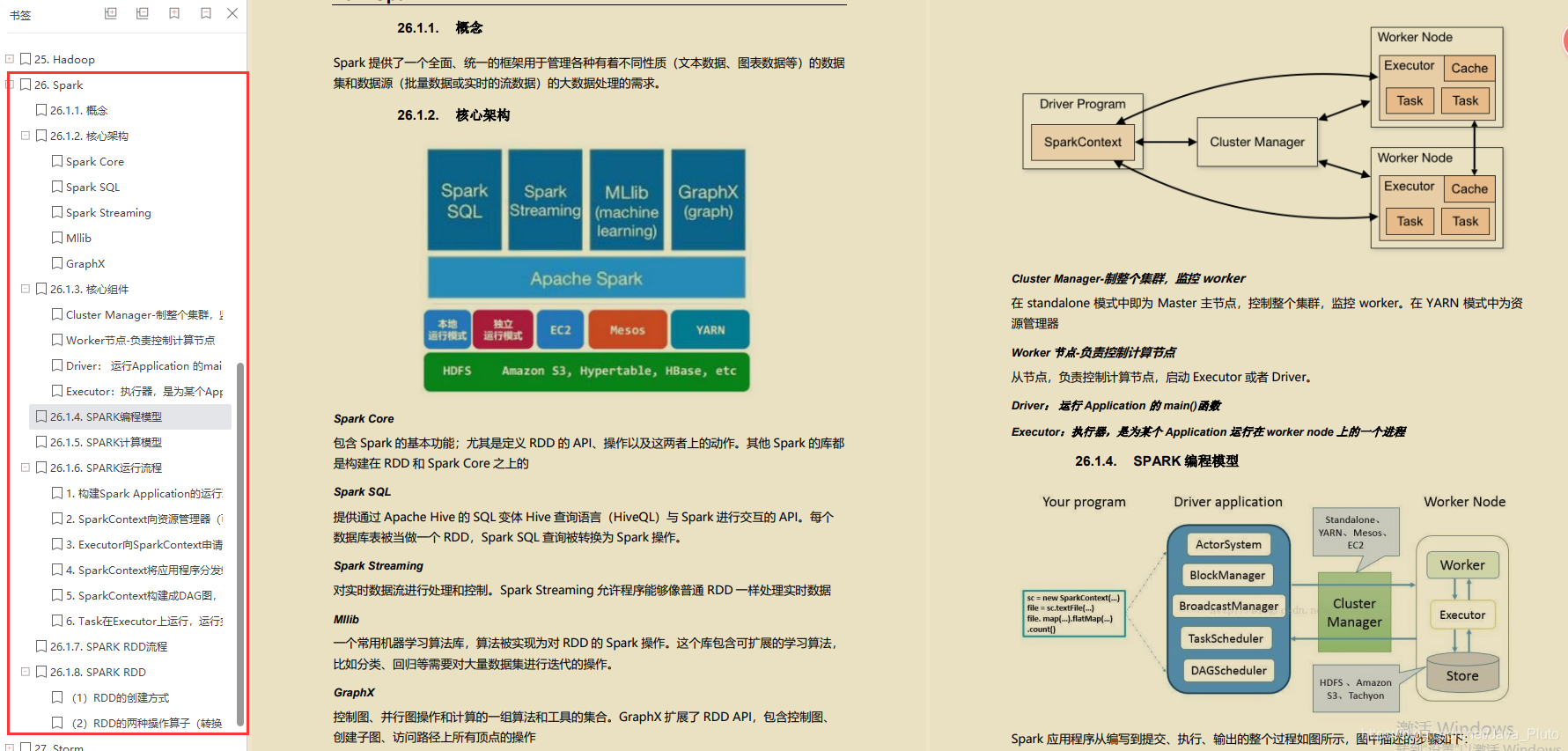
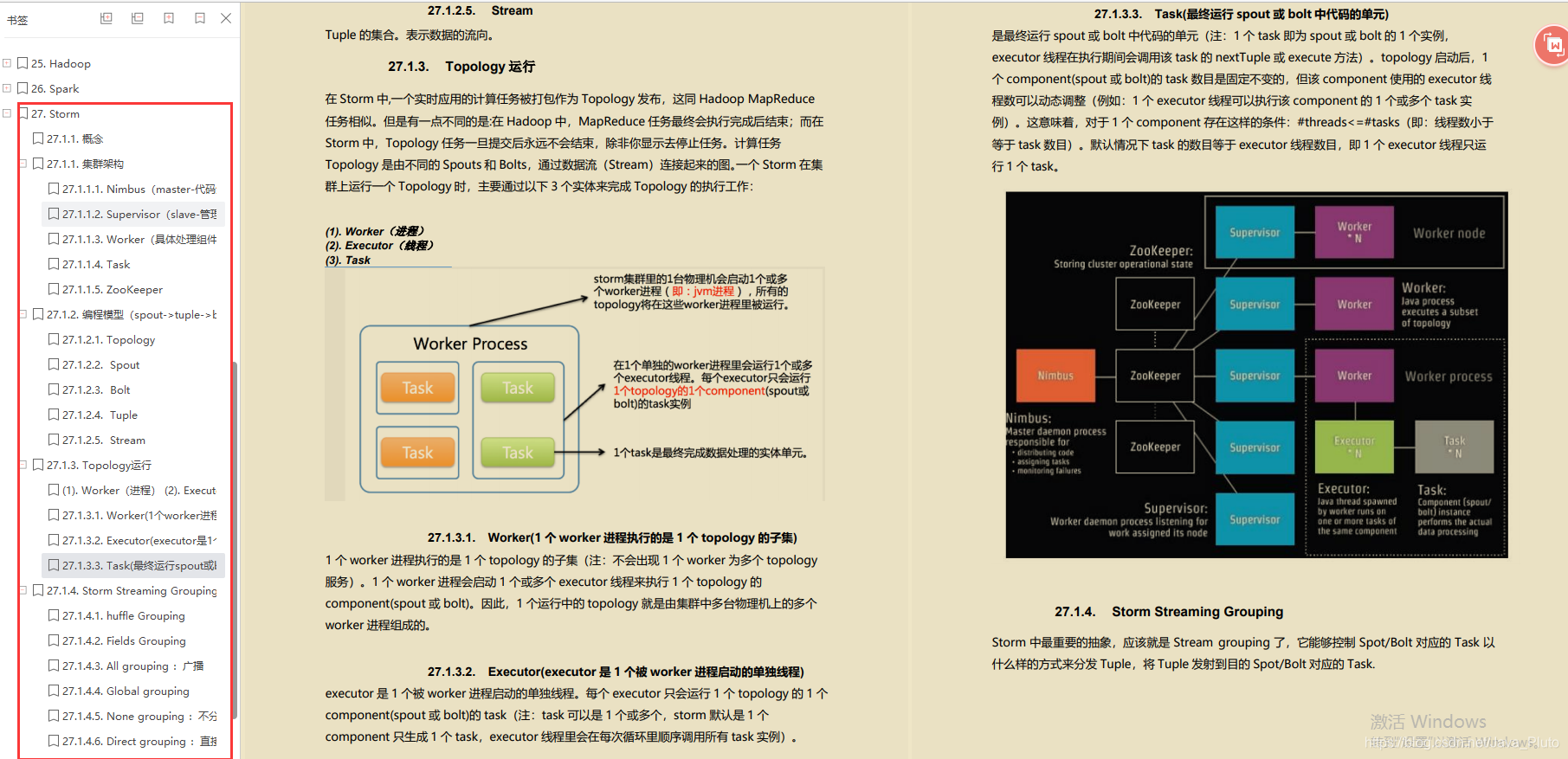
Storm
- 概念
- 集群架构
- 编程模型(spout->tuple->bolt)
- Topology运行
- Storm Streaming Grouping
![]()
YARN
- 概念
- ResourceManager
- NodeManager
- ApplicationMaster
- YARN运行流程
![]()

机器学习
- 决策树
- 随机森林算法
- 逻辑回归
- SVM
- 朴素贝叶斯
- K最近邻算法
- K均值算法
- Adaboost算法
- 神经网络
- 马尔可夫
云计算
- Saas
- Paas
- laaS
- Docker
- Openstack
![]()


Tip:本来这一栏有很多我准备的资料的,但是都是外链,或者不合适的分享方式,博客的运营小姐姐提醒了我,请直接点击这里领取资料哦。
结束语
对于面试,说几句个人观点。
面试,说到底是一种考试。正如我们一直批判应试教育脱离教育的本质,为了面试学习技术也脱离了技术的初心。但考试对于人才选拔的有效性是毋庸置疑的,几千年来一直如此。除非你有实力向公司证明你足够优秀,否则,还是得乖乖准备面试。这也并不妨碍你在通过面试之后按自己的方式学习。
其实在面试准备阶段,个人的收获是很大的,我也认为这是一种不错的学习方式。首先,面试问题大部分基础而且深入,这些是平时工作的基础。就好像我们之前一直不明白学习语文的意义,但它的意义就在每天的谈话间。
所谓面试造火箭,工作拧螺丝。面试往往有更高的要求,也迫使我们更专心更深入地去学习一些知识,也何尝不是一种好事。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号