XML:XML的解析 - xpath方式读取xml
1 xpath介绍
XPath 是一门在 XML 文档中查找信息的语言。 可以是使用xpath查找xml中的内容
XPath 的好处
由于DOM4J在解析XML时只能一层一层解析,所以当XML文件层数过多时使用会很不方便,结合 XPATH就可以直接获取到某个元素
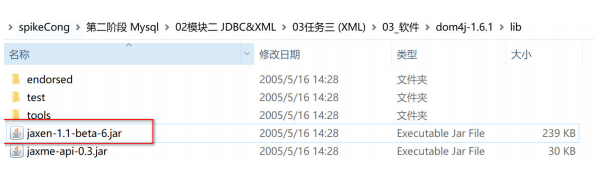
需要再导入 jaxen-1.1-beta-6.jar
2 XPath基本语法介绍
使用dom4j支持xpath的操作的几种主要形式
| 语法 | 说明 |
| /AAA/DDD/BBB | 表示一层一层的,AAA下面 DDD下面的BBB |
| //BBB | 表示和这个名称相同,表示只要名称是BBB,都得到 |
| //* | 所有元素 |
| BBB[1] , BBB[last()] | 第一种表示第一个BBB元素, 第二种表示最后一个BBB元素 |
| //BBB[@id] | 表示只要BBB元素上面有id属性,都得到 |
| //BBB[@id='b1'] | 表示元素名称是BBB,在BBB上面有id属性,并且id的属性值是b1 |



3 API介绍
常用方法
1.selectSingleNode(query): 查找和 XPath 查询匹配的一个节点
参数是Xpath 查询串
2.selectNodes(query): 得到的是xml根节点下的所有满足 xpath 的节点
参数是Xpath 查询串
3.Node: 节点对象
4 Xpath读取XML
数据准备 book.xml
<?xml version="1.0" encoding="UTF-8" ?> <bookstore> <book id="book1"> <name>Java从入门到跑路</name> <author>金圣叹</author> <price>99</price> </book> <book id="book2"> <name>红楼梦</name> <author>曹雪芹</author> <price>69</price> </book> <book id="book3"> <name>Java编程思想</name> <author>埃克尔</author> <price>59</price> </book> </bookstore>
代码示例
1. 使用selectSingleNode方法 查询指定节点中的内容
/*
* 1. 使用selectSingleNode方法 查询指定节点中的内容
* */
@Test
public void test1() throws DocumentException {
//1.创建解析器对象
SAXReader sr = new SAXReader();
//2.获取文档对象
Document document =
sr.read("H:\\jdbc_work\\xml_task03\\src\\com\\lagou\\xml03\\book.xml");
//3.调用 selectSingleNode() 方法,获取name节点对象
Node node1 = document.selectSingleNode("/bookstore/book/name");
System.out.println("节点: " + node1.getName());
System.out.println("书名: " + node1.getText());
//4.获取第二本书的名称
Node node2 = document.selectSingleNode("/bookstore/book[2]/name");
System.out.println("第二本书的书名为: " + node2.getText());
}
2.使用selectSingleNode方法 获取属性值,或者属性值对应的节点
/*
* 2.使用selectSingleNode方法 获取属性值,或者属性值对应的节点
* */
@Test
public void test2() throws DocumentException {
//1.创建解析器对象
SAXReader sr = new SAXReader();
//2.获取文档对象
Document document =
sr.read("H:\\jdbc_work\\xml_task03\\src\\com\\lagou\\xml03\\book.xml");
//3.获取第一个book节点的 id属性的值
Node node1 = document.selectSingleNode("/bookstore/book/attribute::id");
System.out.println("第一个book的id值为: " + node1.getText());
//4.获取最后一个book节点的 id属性的值
Node node2 =
document.selectSingleNode("/bookstore/book[last()]/attribute::id");
System.out.println("最后一个book节点的id值为: " + node2.getText());
//5.获取id属性值为 book2的 书名
Node node3 = document.selectSingleNode("/bookstore/book[@id='book2']");
String name = node3.selectSingleNode("name").getText();
System.out.println("id为book2的书名是: " + name);
}
3. 使用 selectNodes()方法 获取对应名称的所有节点
/* * 3.使用 selectNodes()方法 获取对应名称的所有节点 * * */ @Test public void test3() throws DocumentException { //1.创建解析器对象 SAXReader sr = new SAXReader(); //2.获取文档对象 Document document = sr.read("H:\\jdbc_work\\xml_task03\\src\\com\\lagou\\xml03\\book.xml"); //3.获取所有节点,打印节点名 List<Node> list = document.selectNodes("//*"); for (Node node : list) { System.out.println("节点名: " + node.getName()); } //4.获取所有的书名 List<Node> names = document.selectNodes("//name"); for (Node name : names) { System.out.println(name.getText()); } //5.获取指定 id值为book1的节点的所有 内容 List<Node> book1 = document.selectNodes("/bookstore/book[@id='book1']//*"); for (Node node : book1) { System.out.println(node.getName()+" = " + node.getText()); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号