MySQL:DQL操作单表
1 创建数据库,复制表
1) 创建一个新的数据库 db2
CREATE DATABASE db2 CHARACTER SET utf8;
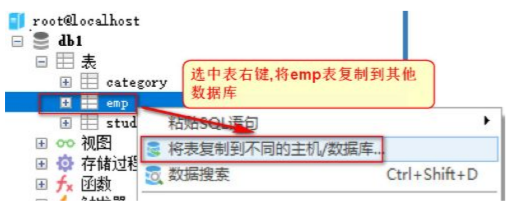
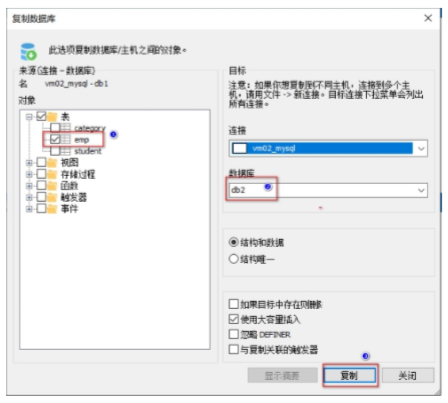
2) 将db1数据库中的 emp表 复制到当前 db2数据库
2 排序
通过 ORDER BY 子句,可以将查询出的结果进行排序(排序只是显示效果,不会影响真实数据)
语法结构
SELECT 字段名 FROM 表名 [WHERE 字段 = 值] ORDER BY 字段名 [ASC / DESC]
ASC 表示升序排序(默认)
DESC 表示降序排序
排序方式
1) 单列排序
只按照某一个字段进行排序, 就是单列排序
需求1:
使用 salary 字段,对emp 表数据进行排序 (升序/降序)
-- 默认升序排序 ASC
SELECT * FROM emp ORDER BY salary; -- 降序排序 SELECT * FROM emp ORDER BY salary DESC;
2) 组合排序
同时对多个字段进行排序, 如果第一个字段相同 就按照第二个字段进行排序,以此类推
需求2:
在薪水排序的基础上,再使用id进行排序, 如果薪水相同就以id 做降序排序
-- 组合排序 SELECT * FROM emp ORDER BY salary DESC, eid DESC;
3 聚合函数
之前我们做的查询都是横向查询,它们都是根据条件一行一行的进行判断,
而使用聚合函数查询:是纵向 查询,它是对某一列的值进行计算,然后返回一个单一的值(另外,聚合函数会忽略null空值。);
语法结构
SELECT 聚合函数(字段名) FROM 表名;
我们来学习5个聚合函数
| 聚合函数 |
作用 |
| count(计数字段) |
统计指定列不为NULL的记录行数 |
| sum(求和字段) | 计算指定列的数值和 |
| max(字段) |
计算指定列的最大值 |
| min(字段) |
计算指定列的最小值 |
| avg(字段) |
计算指定列的平均值 |
需求1:
#1 查询员工的总数 #2 查看员工总薪水、最高薪水、最小薪水、薪水的平均值 #3 查询薪水大于4000员工的个数 #4 查询部门为'教学部'的所有员工的个数 #5 查询部门为'市场部'所有员工的平均薪水
SQL实现
#1 查询员工的总数 -- 统计表中的记录条数 使用 count() SELECT COUNT(eid) FROM emp; -- 使用某一个字段 SELECT COUNT(*) FROM emp; -- 使用 * , 表示所有列 SELECT COUNT(1) FROM emp; -- 使用 1,与 * 效果一样 -- 下面这条SQL 得到的总条数不准确,因为count函数忽略了空值 -- 所以使用时注意不要使用带有null的列进行统计 SELECT COUNT(dept_name) FROM emp;
#2 查看员工总薪水、最高薪水、最小薪水、薪水的平均值 -- sum函数求和, max函数求最大, min函数求最小, avg函数求平均值 SELECT SUM(salary) AS '总薪水', MAX(salary) AS '最高薪水', MIN(salary) AS '最低薪水', AVG(salary) AS '平均薪水' FROM emp;
#3 查询薪水大于4000员工的个数
SELECT COUNT(*) FROM emp WHERE salary > 4000;
#4 查询部门为'教学部'的所有员工的个数 SELECT COUNT(*) FROM emp WHERE dept_name = '教学部';
#5 查询部门为'市场部'所有员工的平均薪水 SELECT AVG(salary) AS '市场部平均薪资' FROM emp WHERE dept_name = '市场部';
4 分组
分组查询指的是使用 GROUP BY 语句,对查询的信息进行分组,相同数据作为一组
语法格式
SELECT 分组字段/聚合函数 FROM 表名 GROUP BY 分组字段 [HAVING 条件];
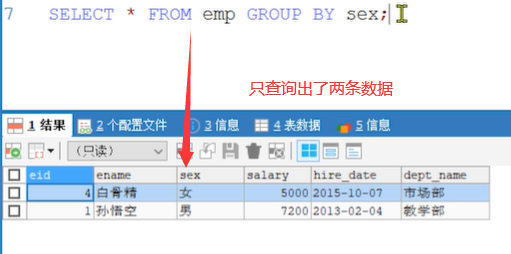
需求1: 通过性别字段 进行分组
-- 按照性别进行分组操作 SELECT * FROM emp GROUP BY sex; -- 注意 这样写没有意义
分析: GROUP BY 分组过程
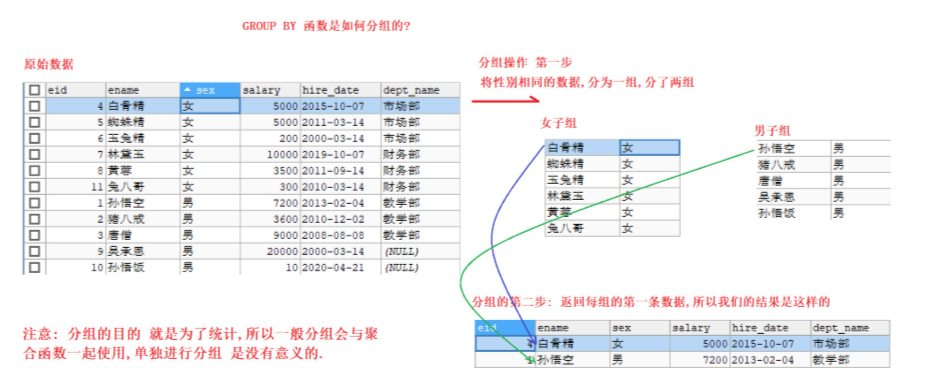
注意:
分组时 可以查询 要分组的字段, 或者使用 聚合函数 进行统计操作. * 查询其他字段没有意义
需求: 通过性别字段 进行分组,求各组的平均薪资
SELECT sex, AVG(salary) FROM emp GROUP BY sex;
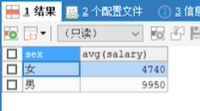
需求2:
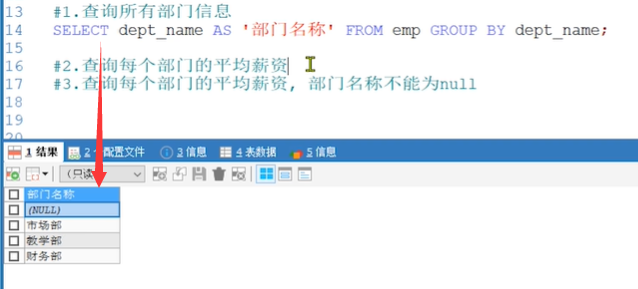
#1.查询所有部门信息 #2.查询每个部门的平均薪资 #3.查询每个部门的平均薪资, 部门名称不能为null
SQL实现
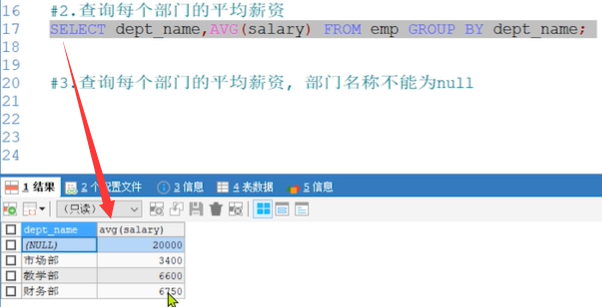
#1. 查询有几个部门 SELECT dept_name AS '部门名称' FROM emp GROUP BY dept_name; #2.查询每个部门的平均薪资 SELECT dept_name AS '部门名称', AVG(salary) AS '平均薪资' FROM emp GROUP BY dept_name;
#3.查询每个部门的平均薪资, 部门名称不能为null
SELECT
dept_name AS '部门名称',
AVG(salary) AS '平均薪资'
FROM emp WHERE dept_name IS NOT NULL GROUP BY dept_name;
需求3:
# 查询平均薪资大于6000的部门.
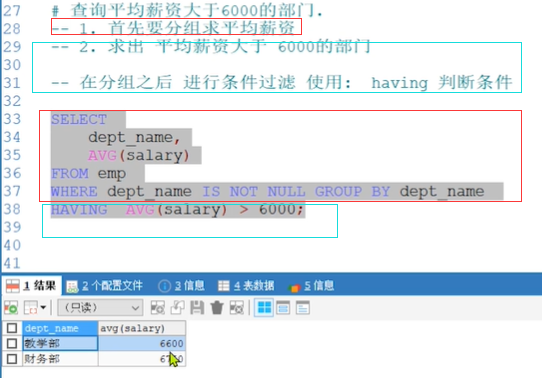
分析:
1) 需要在分组后,对数据进行过滤,使用 关键字 having
2) 分组操作中的having子语句,是用于在分组后对数据进行过滤的,作用类似于where条件。
SQL实现:
# 查询平均薪资大于6000的部门 -- 需要在分组后再次进行过滤,使用 having SELECT dept_name , AVG(salary) FROM emp WHERE dept_name IS NOT NULL GROUP BY dept_name HAVING AVG(salary) > 6000 ;
where 与 having的区别
| 过滤方式 |
特点 |
| where |
where 进行分组前的过滤 where 后面不能跟 聚合函数 |
| having |
having 是分组后的过滤 having 后面可以写 聚合函数 |
5 limit关键字
limit 关键字的作用
limit是限制的意思,用于 限制返回的查询结果的(条数)行数 (可以通过limit指定查询多少行数据)
limit 语法是 MySql的方言,用来完成分页
语法结构
SELECT 字段1,字段2... FROM 表名 LIMIT offset , length;
参数说明
offset , length 关键字可以接受一个 或者两个 为0 或者正整数的参数 offset 起始行数, 默认从0开始记数 length 返回的行数 (要查询几条数据)
需求1:
# 查询emp表中的前 5条数据
# 查询emp表中 从第4条开始,查询6条
SQL实现
# 查询emp表中的前 5条数据 -- 参数1 起始值,默认是0 , 参数2 要查询的条数 SELECT * FROM emp LIMIT 5; SELECT * FROM emp LIMIT 0 , 5; # 查询emp表中 从第4条开始,查询6条 -- 起始值默认是从0开始的. SELECT * FROM emp LIMIT 3 , 6;
需求2: 分页操作 每页显示3条数
SQL实现
-- 分页操作 每页显示3条数据 SELECT * FROM emp LIMIT 0,3; -- 第1页 SELECT * FROM emp LIMIT 3,3; -- 第2页 2-1=1 1*3=3 SELECT * FROM emp LIMIT 6,3; -- 第三页 -- 分页公式: 起始行数 = (当前页码 - 1) * 每页显示条数 -- limit是MySql中的方言

 浙公网安备 33010602011771号
浙公网安备 33010602011771号