C Primer Plus 读书笔记(更新中)
第一章:初识C语言
C的历史和特性
C语言的起源:Dennis Ritch 和 Ken Thompson 在开发UNIX操作系统时设计了C语言(基于B语言进行设计)。
C的高效性:C语言具有通常是汇编语言才具有的微调控制能力,可以根据具体情况微调程序以获得最大运行速度或最有效地使用内存。
C的可移植性:许多计算机体系结构都可以使用C编译器(C编译器是把C代码转换成计算机内部指令的程序)。
由于C语言和UNIX关系密切,UNIX系统通常会将C编译器作为软件包的一部分。安装Linux时,通常也会安装C编译器。供个人计算机使用的C编译器很多,运行各种版本的Windows和Macintosh的PC都能找到合适的C编译器。
计算机能做什么:现代计算机由多种部件构成。中央处理单元(CPU)承担大部分运算工作。随机存取内存(RAM)是存储程序和文件的工作区;永久内存存储设备(包括机械硬盘和固态硬盘等)即使在关闭计算机后,也不会丢失之前存储的程序和文件。还有各种外围设备提供人与计算机之间的交互。CPU负责处理程序。
CPU的工作非常简单,它从内存中获取并执行一条指令,然后再从内存中获取并执行下一条指令,诸如此类(CPU能以惊人的速度从事枯燥的工作)。且CPU能理解的指令有限(这些指令的集合叫作指令集)这里我在CA学的指令集(ISA)就是RISC-V 。
高级计算机语言和编译器:高级编程语言(如C)使我们不必再用数字码/机器码来表示指令,这样使用的指令能更贴近你如何想这个问题。这种高级语言人类可以理解,但对于计算机就是一堆无法理解的无用数据,所以编译器派上了用场,即将高级语言程序翻译成计算机能理解的机器语言指令集的程序。
对于同一个高级语言程序,可以使用相应的编译器翻译成不同CPU使用的机器语言。
编写程序的步骤
- 定义程序的目标
- 设计程序
- 编写代码
- 编译
- 运行程序
- 测试和调试程序
- 维护和修改程序
编译器和链接器的一些知识
编译就是将源代码如(.c)翻译成机器码。C编译采取分而治之的方法,即分开编译模块,最后用链接器合并已经编译好的模块。这样的好处就是如果只更改某个模块的话,不必因此重新编译其他模块。
对于我们编写的源代码,编译完成仅仅产生目标代码文件(.o),尽管由机器码组成,但是并不是完整的程序。一是缺少启动代码,二是缺少调用的库函数的代码。这些就体现了C编译器的分而治之,像一些库代码会预编译,然后最后由链接器将目标代码、系统的标准启动代码和库代码着3部分合并称为一个文件,这便是可执行文件(.exe)。
C标准
C89/C90 -> C11 -> C17 ->......
C标准制定遵循C精神
-
信任程序员
-
不要妨碍程序员做需要做的事
-
保持语言精炼简单
-
只提供一种方法执行一项操作
-
让程序运行更快,即使不能保证其可移植性
关于最后一点,标准委员会的用意是:作为实现,应该针对目标计算机来定义最合适的某特定操作,而不是强加一个抽象、统一的定义。
本章小结
C是强大而简洁的编程语言。它之所以流行,在于自身提供大量的实用编程工具,能很好地控制硬件。而且,与大多数其他程序相比,C程序更容易从一个系统移植到另一个系统。
C是编译型语言。C编译器和链接器是把C语言源代码转换成可执行代码的程序。
用C语言编程可能费力、困难,让你感到沮丧,但是它也可以激发你的兴趣,让你兴奋、满意。我们希望你在愉快的学习过程中爱上C。
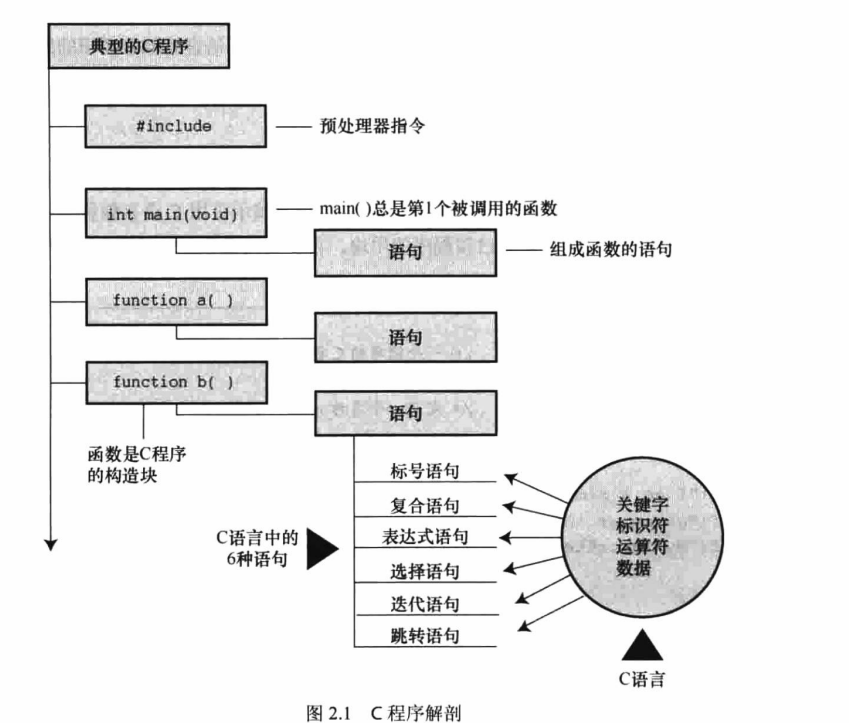
第二章:C语言概述
实例分析与引入
first.c实例
# include<stdio.h>
int main(void){
int num;
num = 1;
printf("I am a simple ");
printf("computer.\n");
printf("My favorite number is %d because it is first.\n" ,num);
getchar();
return 0;
}
快速概要
#include<stdio.h>:该行告诉编译器将 stdio.h 中的内容包含在当前程序中。 stdio.h 是 C 编译器软件包的标准部分,它提供键盘输入和屏幕输出的支持。
/* */ :注释能提高程序的可读性,编译器会忽略它们。
程序细节
#include指令和头文件
#include<stdio.h>:是一条C预处理器指令(通常,C编译器在编译前会对源代码做一些准备工作,即预处理 - prepocessing)
通常,在C程序顶部的信息集合被称为头文件(header),比如
stdio.h就是标准输入/输出头文件,而所有C编译器软件包都提供stdio.h文件。
ANSI/ISO C 规定了C编译器必须提供哪些头文件。
main()函数
main():除了main()函数,函数可以被任意命名,而且main()函数必须是开始的函数。
如果浏览旧式的C代码,会发现程序以如下形式开始:
main()C90 勉强接收这种形式,但是 C99 和 C11 标准不允许这样写。因此,即使你的编译器允许,也不要这样写。
注释
C99新增了另一种风格的注释,普遍用于C++和Java。这种新风格使用//符号创建注释,仅限于单行。
// 凑豆配腐掳,美食界中的博主。不管是腥还是臭,到我嘴里就是肉。奥利给,干了兄弟们!
花括号、函数体和块
{
...
}
声明
int num;
int 是C语言的一个关键字(keyword),表示一种基本的C语言数据类型。
num 是一个标识符(identifier),也就是一个变量、函数或其他实体的名称。
因此,声明把特定标识符与计算机内存中的特定位置联系起来,同时也确定了存储在某位置的信息类型或数据类型。
在C语言中,所有变量都必须先声明后使用。
数据类型
我们通过声明,让计算机能够正确地存储、读取和解释数据。在下一章将详细介绍C语言中的各种数据结构。
命名
C99 和 C11 允许使用更长的标识符名,但是编译器只识别前63个字符。对于外部标识符(参阅第12章),只允许使用31个字符。(以前 C90 只允许6个字符,这是一个很大的进步。旧式编译器通常只允许使用8个字符。)实际上,你可以使用更长的字符,但是编译器会忽略超出的字符。
对于超出63个字符之外不同,而前63个字符都相同的两个标识符,标准并未定义在这种情况下会发生什么。
命名使用小写字母、大写字母、数字和下划线(_)来命名,而且名称的第一个字符必须是字母或下划线,不能是数字。C语言名称区分大小写。
操作系统和C库经常使用一个或两个下划线字符开始的标识符(如 _kcab),因此最好避免在自己的程序中使用这种名称。
声明变量的四个理由
- 汇总变量,提高程序可读性
- 便于在编写程序前做计划
- 有助于发现隐藏在程序中的小错误,如变量名拼写错误
- 不声明,C程序将无法通过编译
赋值
num = 1;
👉赋值到👈,把值存储在之前声明时,编译器在计算机内存中为变量 num 预留的空间。
printf() 函数
C语言的一个标准函数,声明于stdio.h中。
运行到printf()时,程序控制权转给已命名的函数,即printf(),函数执行结束后,控制权返回至主调函数(calling function),该例中为main()
对于\n这种换行符(newline character),为啥不直接用Enter呢?
因为这是在编辑器中按Enter,编辑器就会以为这是直接的命令,在我们编辑代码的时候就换行了,而我们实际想要的是输出时换行。
换行符时一个转义序列(escape sequence)。转义序列用于代表难以标识或无法输入的字符。每个转义序列都以反斜杠字符(\)开始。我们在第3章中再来讨论相关内容。
关于printf()中%d,它相当于是个占位符,其作用是指明输出num的位置。在第3章会详细介绍相关内容。
return语句
事实上,如果遗漏main()函数中的return 0;,在程序运行到语句块结束即(})时也会返回0。但我们应该养成良好的代码习惯,可以看作是统一代码风格。
但对于某些操作系统(包括 Linux 和 UNIX),return语句有实际的用途。第11章将详细讨论。
不得不说,这按照书上每个小章节总结实在时太费劲了。
接下来,即从2.3开始,我都只写下之前不理解或理解得不清楚的重点部分。
提高程序可读性的技巧
- 选择有意义的函数名
- 写注释
- 在函数中用空行分隔概念上的多个部分(示例代码就是这样)
- 每个语句各占一行
进一步使用C
多条声明
程序可以在一条声明中进行多个同类型变量的声明,记住变量要用逗号隔开。
int feet, fathoms;
打印多个值
printf()中用俩占位符,后面的变量用逗号隔开。
printf("There are %d feet in %d fathoms!\n", feet, fathoms);
这个用逗号隔开各个实参,确实符合正常函数的调用。
多个函数
C 标准建议,要为程序中用到的所有函数提供函数原型(prototype)。标准include文件为标准库函数提供了函数原型。之后如第9章将会更详细全面地介绍函数。
调试程序
语法错误
编译器也会有出错的时候。也许某处隐藏的语法错误会导致编译器误判。
编译器另一个常见的毛病是,报错的位置比真正的错误位置滞后一行。例如,编译器在编译下一行时才会发现上一行缺少分号。因此,如果编译器报错某行缺少分号,请检查上一行。
语义错误
就是自己编写有问题,实际代码与意图不符合。
当然这也是debug很常见的问题,这个时候就要把自己想象成计算机,跟着程序的步骤一步一步地执行。
程序状态
(program state):是在程序地执行过程中,某给定点上所有变量值的集合。它是计算机当前状态的一个快照。
关键概念
由于编译器不具有真正的智能,所以你必须用编译器能理解的术语表达你的意图,这些术语就是C语言标准规定的形式规则(尽管有些约束,但总比直接用机器语言方便的多)。
第三章:数据和C
#include <stdio.h>
int main(void){
float weight;
float value;
printf("Are you wroth your weight in platinum?\n");
printf("Let's check it out!\n");
printf("Please enter your weight in pounds: ");
scanf("%f", &weight); // 假设输入156
value = 1700.0 * weight *14.5833;
printf("Your weight in platinum is worth $%.2f\n", value);
printf("You are easily worth that! If platinum prices drop, \n");
printf("eat more to maintain your value!\n");
getchar();
getchar();
return 0;
}
key point:
getchar()函数读取下一个输入字符,因此程序会等待用户输入。在这种情况下,键入156并按下Enter(或Return)键(发送一个换行符),然后scnaf()读取键入的数字,第一个getchar()读取换行符,第二个getchar()让程序暂停,等待输入。
变量与常量数据
要完成一些列任务,程序需要使用数据,即承载信息的数字和字符。有些数据类型在程序使用之前就已经预设好了,在整个程序的运行过程中没有变化,这些称为常量。其他数据类型在程序运行期间可能会被改变或者赋值,这些称为变量。
数据:数据类型关键字
数据既可以是数字也可以是字符,而C通过识别一些基本的数据类型来区分和使用这些不同的数据类型
如果数据是常量,编译器一般通过用户书写的形式来识别类型;但对于变量而言,要在声明的时候指定其类型。而这就要用到数据类型关键字了。
| 最初K&R给出的关键字 | C90标准添加的关键字 | C99标准添加的关键字 |
|---|---|---|
| int | signed | _Bool |
| long | void | _Complex |
| short | _Imaginary | |
| unsigned | ||
| char | ||
| float | ||
| double |
关于字(word)是设计计算机时给定的自然存储单位,这个和具体计算机挂钩,但总的来说,计算机的字长越长,其数据转移越快,允许的内存访问也更多。
整数与浮点数
对于我们而言,整数和浮点数的区别是它们的书写方式不同。对计算机而言,他们的区别是存储方式不同。
- 整数
- 计算机以二进制数字存储整数
- 浮点数 (注意,在一个值后面加上一个小数点,该值即称为一个浮点值。)
- 计算机把浮点数分成小数部分和指数部分来表示,而且分开存储这两部分(to be covered in 15章)
两者的主要区别:
- 整数没有小数部分,浮点数有小数部分。
- 浮点数可以表示的范围比整数大。
- 对于一些算数运算(如,两个很大的数相减),浮点数损失的精度更多
- 因为在任何区间内(如,1.0到2.0之间)都存在无穷多个实数,所以计算机的浮点数不能表示区间内的所有值。浮点数通常只是实际值的近似值。
- 过去,浮点运算比整数运算慢。不过现在许多CPU都包含浮点处理器,缩小了速度上的差距。
C语言基本数据类型
int类型
一般而言,存储一个int要占用一个机器字长(word)。
即如int eggs;一样声明,效果就是为一个int大小的变量赋予名称并分配内存空间。这创建了变量,但是并没有给它们提供值。而变量在程序中获取值有以下的方法:
-
赋值:
eggs = 2; -
通过函数如scanf()获得值
-
初始化变量:为变量赋一个初始值
在C中,初始化可以在声明中直接完成
key point
int hogs = 21; int cows = 32, goats = 14; int dogs, cats = 94; // 有效但这种格式很糟糕,它仅仅初始化了cats,dogs仅仅是被声明了所以最好不要把初始化的变量和未初始化的变量放在同一条声明中。
C语言大多数整形常量视为int类型,但非常大的整数除外。
八进制和十六进制
通常,C语言都假定整型常量是十进制数。然而许多程序员很喜欢使用八进制和十六进制数。但是计算机如何知道10000是十进制、十六进制还是二进制。
在C语言中用特定的前缀表示使用那种进制。
0x或0X前缀表示十六进制
0前缀表示八进制
要清楚,使用不同的进制数是为了方便,并不会影响数被存储的方式。也就是说,无论把数字写成16、020还是0x10,计算机存储该数的方式都相同,因为计算机内部都以二进制进行编码。
用printf()显示八进制和十六进制
| 占位符 | 进制 |
|---|---|
| %d | 以十进制显示 |
| %o | 以八进制显示 |
| %x | 以十六进制显示 |
| %#o | 以八进制显示,并显示前缀0 |
| %#x | 以十六进制显示,并显示前缀0x |
| %#X | 以十六进制显示,并显示前缀0X |
提示 匹配printf()说明符的类型
在使用printf()函数时,切记检查每个待打印值都有对应的转换说明,还要检查转换说明的类型是否与待打印值得类型相匹配。
使用字符:char类型
char类型用于存储字符(如,字母或标点符号),但从技术层面看,char是整数类型。因为char类型实际上存储的是 整数 而不是字符。
计算机使用数字编码来处理字符,即用特点得整数表示特定的字符。
美国最常用的编码是ASCII编码,本书也使用此编码。
标准ASCII码的范围是0~127,只用7位二进制数就能表示。通常char类型被定义为8位的存储单元,因此容纳标准ASCII码绰绰有余。
许多字符集都超过了127,甚至多于255。例如,日本汉字(kanji)字符集。商用的统一码(Unicode)创建了一个能表示世界范围内多种字符集的系统,目前包含的字符已超过110000个。
char的声明和int一样
char类型的初始化要用到字符常量(character constant):用单引号括起来的单个字符就被称为字符常量。
我们并不必背下ASCII码,用计算机语言可以轻松做到。因为编译器一旦发现'A'(字符常量),就会将其转换成相应的代码值。
注意是单引号,双引号就是字符串了(第四章会讲字符串)
非打印字符
单引号只适用于字符、数字和标点符号,浏览ASCII表会发现,有些ASCII字符打印不出来。例如一些代表行为的字符(如:退格、换行、终端响铃或蜂鸣)。C语言提供了3种方法来表示这些字符:
- 前面介绍过——使用ASCII码。例如,蜂鸣字符的ASCII值是7,因此可以这样写:
char beep = 7;
- 使用特殊的符号序列来表示一些特殊的字符。这些符号序列叫作转义序列(escape sequence)。如下表
| 转义序列 | 含义 |
|---|---|
| \a | 警报(ANSI C) |
| \b | 退格 |
| \f | 换页 |
| \n | 换行 |
| \r | 回车 |
| \t | 水平制表符 |
| \v | 垂直制表符 |
| \\ | 反斜杠(\) |
| \' | 单引号 |
| \'' | 双引号 |
| \? | 问号 |
| \0oo | 八进制数值(oo必须是有效的八进制数) |
| \xhh | 十六进制值(hh必须是有效的十六进制数) |
使用ASCII码时,注意数字和数字字符的区别。如使用ASCII码是52,’4‘表示字符4,而不是数值4。
那么可能就会有个问题了,为什么用printf的时候转义序列和普通字符没用单引号括起来?
无论是普通字符还是转义序列,只要是双引号括起来的字符集合,就无需用单引号括起来。双引号的字符集合叫做字符串(详见第4章)
打印字符
printf()函数用%c指明待打印的字符。前面介绍过,一个字符变量实际上被存储为1个字节的整数值。因此,如果用%d转换说明打印 char 类型变量的值,打印的是一个整数。而 %c 转换说明告诉printf()打印该整数值对应的字符。
printf()函数中的转换说明决定了数据的显示方式,而不是数据的存储方式。
_Bool类型
C99标准添加了_Bool类型,用于表示布尔值,即逻辑值 true(1) 和 false(0)。原则上仅仅占用一位存储空间。
可移植类型:stdint.h和inttypes.h
C99新增了两个头文件 stdint.h 和 inttypes.h,以确保C语言的类型在各系统中的功能相同。
float、double 和 long double
对于浮点型常量:
-1.56E+12
2.87e-3
// 两个有效的小数表示,其中后一个有符号数时表示10的指数
默认情况下,编译器假定浮点型常量是double类型的精度。
而在浮点数后面加上 f 或 F 后缀可覆盖默认设置,编译器会将浮点型常量看作float类型。使用 l 或 L 后缀舍得数字称为 long double 的类型。
打印浮点值
printf()函数使用%f转换说明打印十进制计数法的float和double类型浮点数。
用 %e 打印指数计数法的浮点数。
如果系统支持十六进制格式的浮点数,可用a和A分别代替e和E。
打印long double类型要使用 %Lf、%Le或La转换说明。
浮点数的上溢和下溢
等用到的时候再查
复数和虚数类型
用到再查
其他类型
上面已经说完了C语言的所有基本数据类型。而C语言还有一些从基本类型衍生的其他类型,包括数组、指针、结构和联合等等。
类型大小
实例程序:
#include<stdio.h>
int main(void){
// C99 为类型大小提供 %zd 转换说明(而这实际上是size_t类型)
printf("Type int has a size of %zd bytes.\n", sizeof(int)); // 4
printf("Type char has a size of %zd bytes.\n", sizeof(char)); // 1
printf("Type long has a size of %zd bytes.\n", sizeof(long)); // 8
printf("Type long long has a size of %zd bytes.\n", sizeof(long long)); // 8
printf("Type double has a size of %zd bytes.\n", sizeof(double)); // 8
printf("Type long double has a size of %zd bytes.\n", sizeof(long double)); // 16
return 0;
}
使用数据类型
C 再检查类型匹配方面不太严格,C 编译器甚至允许二次初始化,但在激活了较高级别的警告时,会给出警告。最好不要养成这样的习惯。
把一个类型的数值初始化给不同类型的变量时,编译器会把值转换成与变量匹配的类型,这将导致部分数据丢失。下面是一个例子
int cost = 12.99; // 使用double类型的值初始化int类型的变量
float pi = 3.1415926535; // 使用double类型的值初始化float类型的变量
这实际上会导致如cost = 12(因为C编译器把浮点数转换成整数时,会直接丢弃小数部分,而不进行四舍五入。)
第二个声明则会损失一些精度,因为C只保证了float类型前6位的精度。
参数和陷阱
printf()和scanf()函数与一般函数不同,它们的参数个数是可变的。
printf()和scanf()函数用第1个参数表明后续有多少个参数,即第1个字符串种的转换说明与后面的参数一一对应。
这两个函数的参数个数或类型不匹配可能不会被编译器检测出来,但结果一定会出大问题。
转义序列实例
#include<stdio.h>
int main(void){
float salary;
printf("\aEnter your desired monthly salary:");
printf(" $_______\b\b\b\b\b\b\b");
scanf("%f",&salary);
printf("\n\t$%.2f a month is $%.2f a year.", salary,
salary * 12.0);
printf("\rGee!\n");
getchar();
getchar();
return 0;
}
刷新输出
最初,printf()语句把输出发送到一个叫作缓冲区(buffer)的中间存储区域,然后缓冲区中的内容再不断被发送到屏幕上。C 标准明确规定了何时把缓冲区中的内容发送到屏幕:
当缓冲区满、遇到换行字符、或需要输入的时候(从缓冲区把数据发送到屏幕或文件被称为刷新缓冲区)
WOW! 这我以前真的没有注意到噢!
第四章:字符串和格式化输入/输出
字符串简介
字符串(character string)是一个或多个字符的序列。如
"Zing went the strings of my heart!"
双引号不是字符串的一部分,它仅仅是用来告知编译器它括起来的是字符串。
char类型数组和null字符
因为C没有专门存储字符串的变量类型,所以字符串都被存储在char类型的数组中。
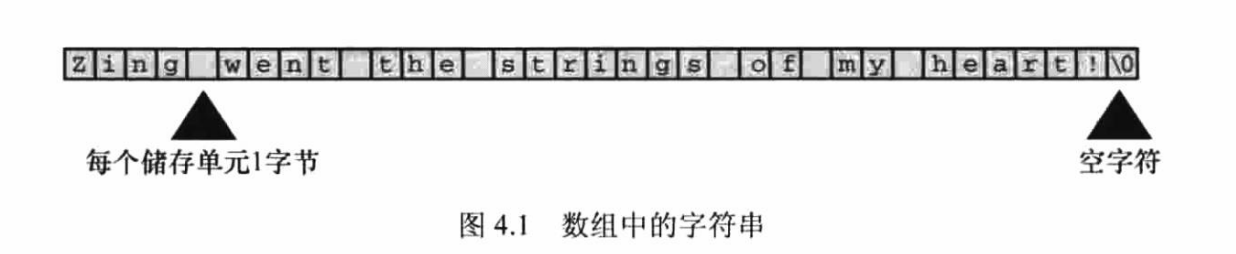
图4.1中数组末尾位置的字符'\0',是空字符(null character),是C语言用来标记字符串的结束的。
空字符不是数字0,它是非打印字符,其ASCII码是(或等价于)0。
因此,比如,一个有40个存储单元的字符串,只能存储39个字符,剩下一个字节留给空字符。
声明方式:
char name[40];
使用字符串
#include<stdio.h>
#define PRAISE "You are an extraordinary being"
int main(void){
char name[40];
printf("What's your name? ");
scanf("%s", name);
printf("Hello, %s. %s\n", name, PRAISE);
system("pause");
return 0;
}
- PRAISE后面用双引号括起来的文本是一个字符串,编译器会在末尾自动加上空字符。
- scanf()在遇到第一个空白(空格、制表符或换行符)时就不再读取输入。
字符串和字符的主要区别在于字符是基本类型,而字符串是派生类型,它是字符数组而且末尾有空字符。
strlen()函数 (之后会在第11章中涉及)
strlen()包含在头文件string.h中,其他一些于字符串相关的函数也都包含在这个头文件中。strlen()将不会计算字符串中最后的空字符\0,而sizeof()在计算字符串大小的时候会把空字符\0也计算进去。
常量和C预处理器
明示常量(manifest constant)/ 符号变量(symbolic constant),即在程序顶部加一行:
#define NAME value
编译程序时,程序中所有的NAME都会被替换成value。这一过程被称为编译时替换(compile-time substitution)(在预处理的时候就已经完成)。在运行程序时,程序中所有的替换均已完成。
const限定符
C90标准新增了 const 关键字,用于限定一个变量为只读。其声明如下:
const int MONTHS = 12; // MONTHS在程序中不可更改,值为12
将在第12章讨论与const相关的内容
printf()和scanf()
printf()
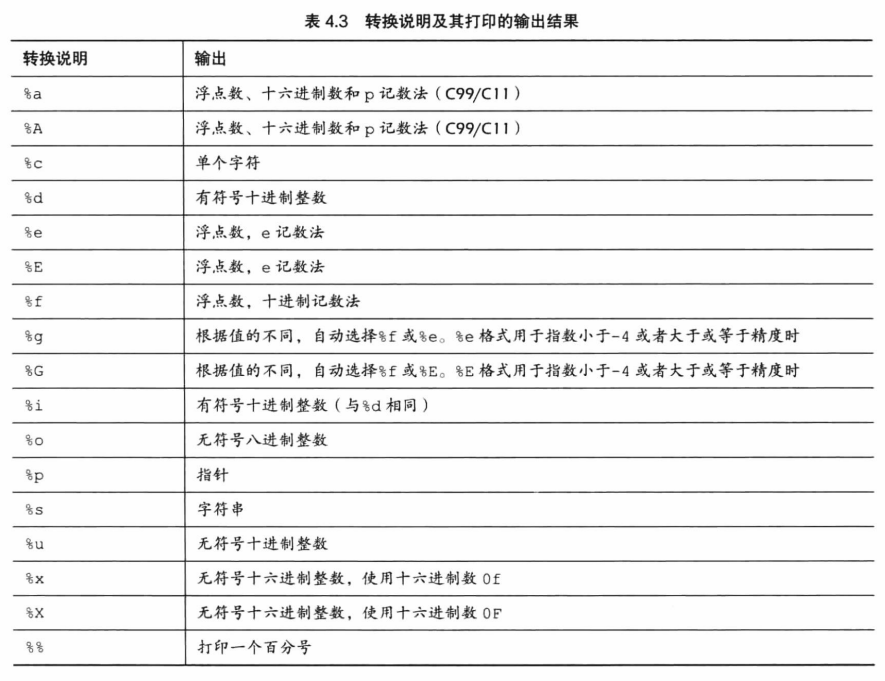
格式为printf(格式字符串, 待打印项1, 待打印项2,...);
其中格式字符串由实际要打印的字符和转换说明组成。
printf()的转换说明修饰符
在%和转换字符之间插入修饰符可以修饰基本的转换说明。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号