
EF CodeFirst(三) 并发处理
2015-12-29 13:10 FelixShen 阅读(3600) 评论(0) 收藏 举报并发分为两种,一种叫做悲观并发,一种叫乐观并发。 名字挺文艺
悲观并发
我们先看一下不控制并发时的场景
![]()
![]()
![]()
之所以能捕捉到错误 是因为 EF这里的操作机制是将 被Timestamp标识的字段加入 where子句。
![]()
![]()
那如果捕捉到了异常,EF会怎么处理呢?使用Reload处理
针对单个字段的并发
悲观并发
悲观并发是什么呢? 就拿我们常用的代码版本控制来说。 有一个文档,A和B都要 获取这个文档并进行修改, 如果当A在读取这个文档数据时,就单独霸占了这个文档,B无法获取,只有当A读取修改完毕释放锁时,B才能获取这个文件,也就是一个人去的控制权的时候,其他人只能等待。这就是悲观锁。因为担心,多人同时操作造成的数据紊乱,大概是因为建立在这样的心态上,取名 “悲观锁”的。
悲观锁 通常用在频繁发生数据竞争的激烈环境下,以及 通过锁来保护数据所需的成本小于回滚事务的成本的时候。
乐观并发
乐观并发显然,“心理”上是反过来的,就是 “我不担心A和B同时取得控制权,A和B可以同时读取 同时修改,但是A修改保存后,B再修改保存,这时候系统会发现,当前文档和B进入系统时不一样了,就会报错。这显然也是一种不错的处理方式。
乐观锁 应用场景一般是 数据竞争并不是特别激烈,且 偶尔的数据争执所需的回滚事务的成本小于读取数据时锁定数据所需要的成本。乐观并发的初衷在于,不希望经常性的看到数据争执。
悲观并发如果加锁的成本较高的话,会很明显的降低效率,降低系统的并发性。
乐观并发 通常分为 三个阶段 读取阶段--校验阶段--写入阶段
在读取阶段,A和B分别将数据读入各自机器缓冲,此时并没有校验,在校验阶段,系统事务会对文件进行同步校验,如果不出现问题,则进入第三阶段写入,数据最终被提交,否则报错。
悲观锁还有一个常见的问题就是“死锁”,比如文档T1 和T2是内容相关的,但是不巧 T1被A锁住了 T2有被B锁住了, 那就会卡在这直到有一方先取消锁。
我们先看一下不控制并发时的场景
//未进行并发处理 User user = new User { UserName="shenwei" ,certID= "11111"}; using (BlogContext ctx= new BlogContext()) { ctx.Users.Add(user); ctx.SaveChanges(); } //首先插入一条数据 并提交 //定义两个context同时进行操作 BlogContext firContext = new BlogContext (); User u1 = firContext.Users.FirstOrDefault(); BlogContext secContext = new BlogContext (); User u2 = secContext.Users.FirstOrDefault(); u2.UserName = "zhangxiaomao" ; //改变名字 并提交 secContext.SaveChanges(); u1.UserName = "xxxxxx" ; u1.certID = "22222" ; //另一个操作改变certid,也提交 firContext.SaveChanges();
数据库 查询select * from Users ;

回到我们的EF codefirst . EntityFramework只支持乐观并发,也就是说EF其实并不希望经常性的看到数据冲突。
针对整条记录的并发
EF实现并发控制 需要借助 TimeStamp 标示 ,并且一个类只能有 一个此标示,标示的必须是byte[]类型
public class Blog { public string ID { get; set; } public string BlogName { get; set; } public string BlogAuthor { get; set; } public virtual List <Post> Posts { get; set ; } //导航属性 public BlogDetails Detail { get; set; } [ Timestamp] public byte [] version { get; set; } }
测试如下
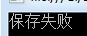
//并发模拟 Blog b = new Blog { ID = "24", BlogName = "Gaea", BlogAuthor = "shenwei", Detail = new BlogDetails { } }; //先通过一个ctx插入数据并提交 using(BlogContext context=new BlogContext()) { context.Blogs.Add(b); context.SaveChanges(); } //创建一个ctx取的第一条数据,修改 但是不提交 BlogContext fircontext = new BlogContext(); Blog firstblog = fircontext.Blogs.FirstOrDefault(); firstblog.BlogName = "哈哈,被改掉了" ; //创建另一个ctx还是取第一条数据,修改并提交 BlogContext secContext = new BlogContext(); Blog secondBlog = secContext.Blogs.FirstOrDefault(); secondBlog.BlogAuthor = "JasonShen"; secContext.SaveChanges(); //这个时候再提交第一个ctx所做的修改 try { //这是后会发现现在的数据,已经和刚进入时发生了变化,故报错 fircontext.SaveChanges(); Console.WriteLine("保存成功" ); } catch(Exception e) { Console.WriteLine("保存失败" ); } Console.ReadKey(); }
结果如下
select * from Blogs;

之所以能捕捉到错误 是因为 EF这里的操作机制是将 被Timestamp标识的字段加入 where子句。
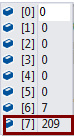
一开始插入一条数据之后,时间戳是这样的,初始版本的对象也就是这个样子
后来两个context 各自获取这个对象,其中一个进行修改,并提交,这个时候数据库中的时间戳标示的字段已经发生了改变。
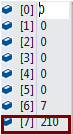
这个时候 ,另一个context提交的时候 执行update .... where version=‘初始版本的version’ 然后会发现找不到,于是就报错!
也就是说依靠 timespan标示的字段来确认是否与初始版本发生了改动,若发生了,就报错,进行错误处理。
那如果捕捉到了异常,EF会怎么处理呢?使用Reload处理
Resolving optimistic concurrency exceptions with Reload
使用Reload数据作为解决乐观并发异常的策略之一,除了Reload外,还有其他几种冲突解决策略,这里只讲下常用的Reload
微软Entity Framework 团队 推荐处理乐观并发冲突的策略之一是Reload数据,也就是EF检测到并发冲突时会抛出DbupdateConcurrencyException,这时解决冲突分为Client Wins或者Store Wins ,而Reload处理也就是Store Wins,意味着放弃当前内存中的实体,重新到数据库中加载当前实体,EF官方团队给出来的示例代码如下
捕捉到异常的时候
try { //这是后会发现现在的数据,已经和刚进入时发生了变化,故报错 fircontext.SaveChanges(); Console .WriteLine("保存成功" ); } catch (DbUpdateConcurrencyException e) { Console .WriteLine("保存失败" ); Console .WriteLine("Reload" ); e.Entries.Single().Reload(); Console .WriteLine(firstblog.BlogName); //会发现 变成了初始从数据库里加载的数据值 }
针对单个字段的并发
有些时候并不需要控制针对整条记录的并发,只需要控制某个列的数据 不会出现脏操作就ok
这个时候 就使用ConcurrencyCheck 标示
public class User { [Key ,DatabaseGenerated (DatabaseGeneratedOption .Identity)] public Guid UserGuid { get; set; } public string UserName { get; set; } [ ConcurrencyCheck ] public string certID { get; set; } }
//针对单个字段 标示的ConcurrencyCheck 的并发 User user = new User { UserName = "shenwei" , certID = "11111" }; using (BlogContext ctx = new BlogContext ()) { ctx.Users.Add(user); ctx.SaveChanges(); } //首先插入一条数据 并提交 //定义两个context同时进行操作 BlogContext firContext = new BlogContext (); User u1 = firContext.Users.FirstOrDefault(); BlogContext secContext = new BlogContext (); User u2 = secContext.Users.FirstOrDefault(); u2.certID= "22222" ; //改变名字 并提交 secContext.SaveChanges(); try { u1.certID = "33333" ; //另一个操作改变certid,也提交 firContext.SaveChanges(); } catch (Exception e) { Console .WriteLine("并发报错" ); }
当然可以同时用concurrentCheck标示多个字段,那被标示的每个都不能被同时修改了。这里背后的机制同样是where将被标示的字段作为了筛选条件。
总结
经过分析乐观锁 并不适合处理高并发的场景,少量的数据冲突才是乐观并发的初衷。 悲观锁同样也不适合处理高并发,特别在加锁成本比较大的时候。
如果项目并发量确实大, 那就可以考虑采用其他技术实现,比如 消息队列等。
如果您喜欢这篇文章,欢迎推荐!
如果你喜欢~就请推荐一下吧O(∩_∩)O

 浙公网安备 33010602011771号
浙公网安备 33010602011771号