可视化理解共识协议Raft
一、分布式共识协议引入
什么是分布式共识协议呢?让我们从一个简单的例子开始。
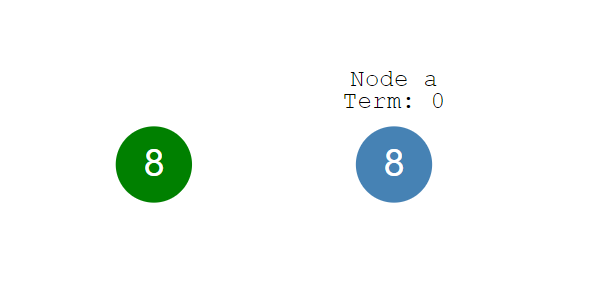
看看我们只有一个节点的系统,在这个系统中,你可以将节点想象为一个数据库系统,这个系统存储了一个值X。

我们有一个客户端(绿色圆圈)可以发送交易给这个系统。

例如客户端发送了值“8”给这个系统。我们很容易理解,由一个单独节点组成的系统要就某个值达成一致或共识很容易。
但如果我们的系统中有多个节点,应该如何达成共识呢?这就是分布式系统的共识问题,为了解决这个问题,科学家们提出了分布式共识协议。
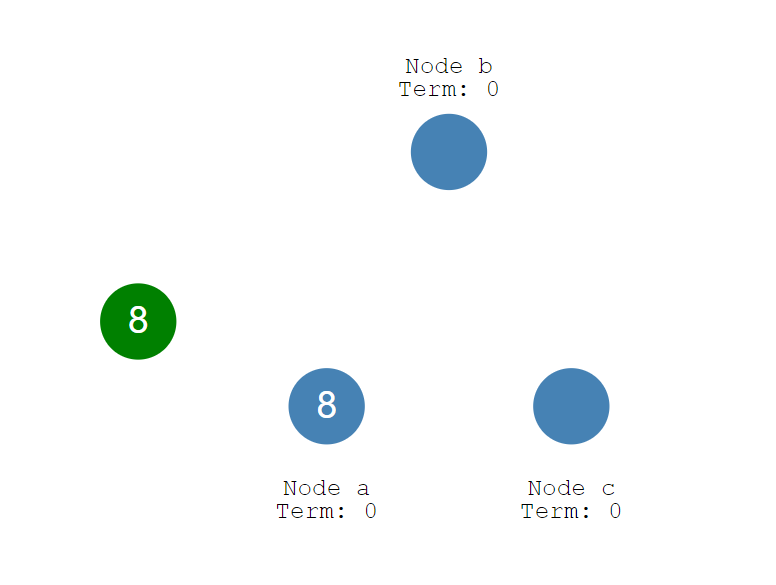
二、Raft分布式共识协议
(一)概述
Raft是一种分布式共识协议的实现,在Raft中,一个节点可以处于三种状态中的一种:Follower、Candidate、Leader,如下图所示。
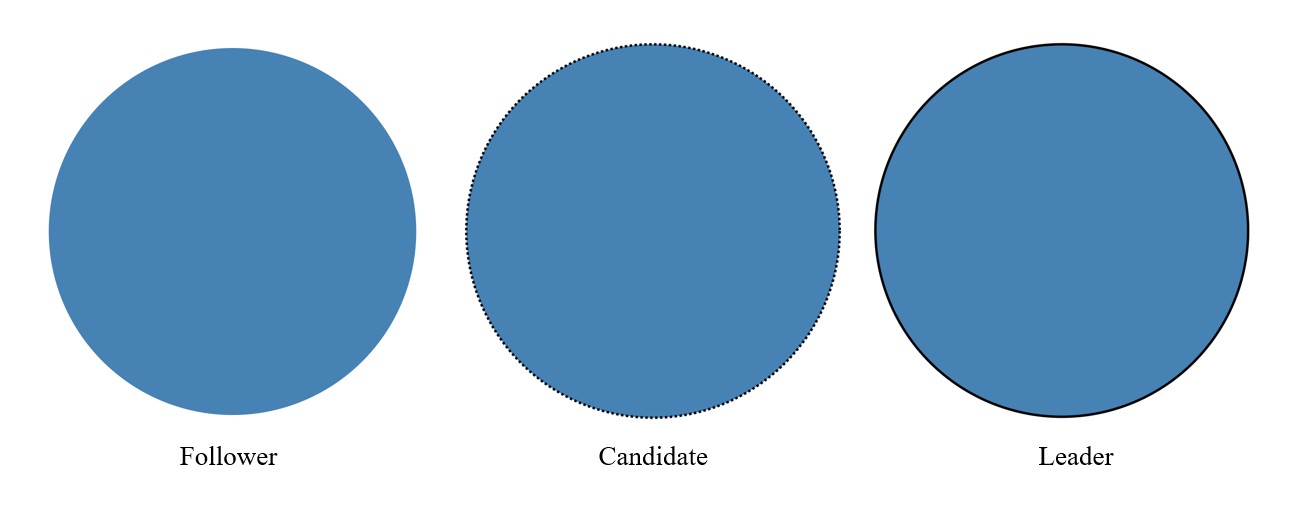
所有节点在最开始都处于Follower状态。

(二)Leader选举
Leader选举是分布式共识协议的核心功能,它是确保分布式共识协议能够有效处理外部请求的关键。
1、Leader选举之首次选举
在Raft中,有两个控制节点选举的超时机制。第一个是选举超时,这是Follower节点变为Candidate节点的时间,这个时间被随机设置为150ms~300ms之间。在一个选举超时时间周期后,Follower节点成为Candidate节点并进入一个新的选举周期,如下图所示。
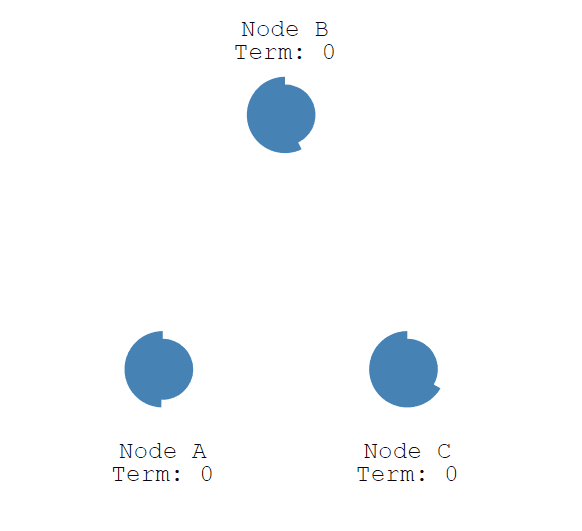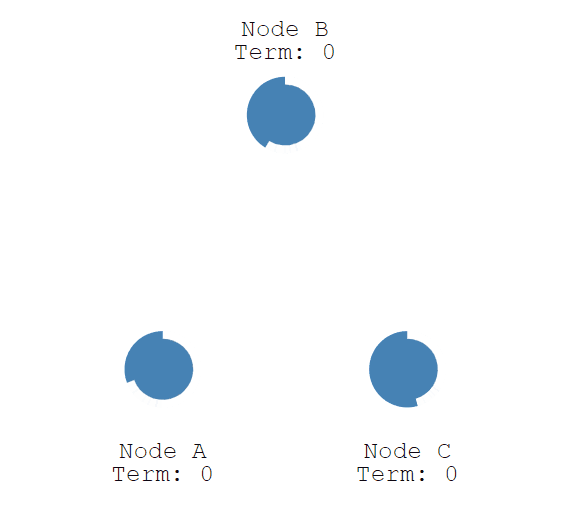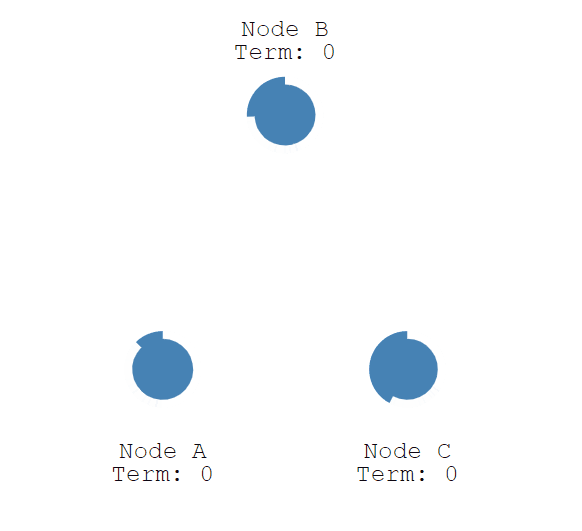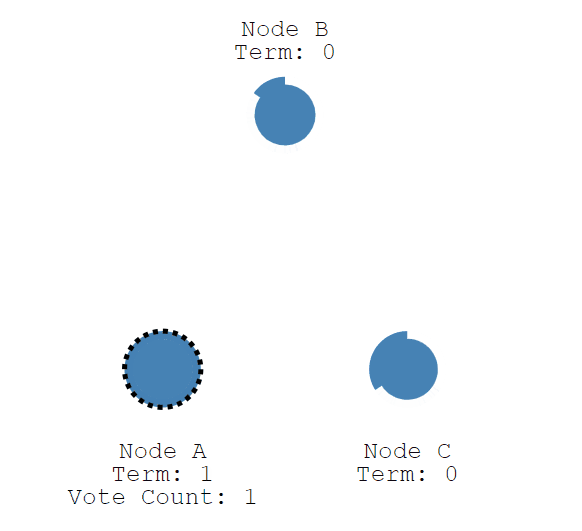
Candidate节点首先给自己投一票,并将请求vote投票的Request请求发送给其他节点。
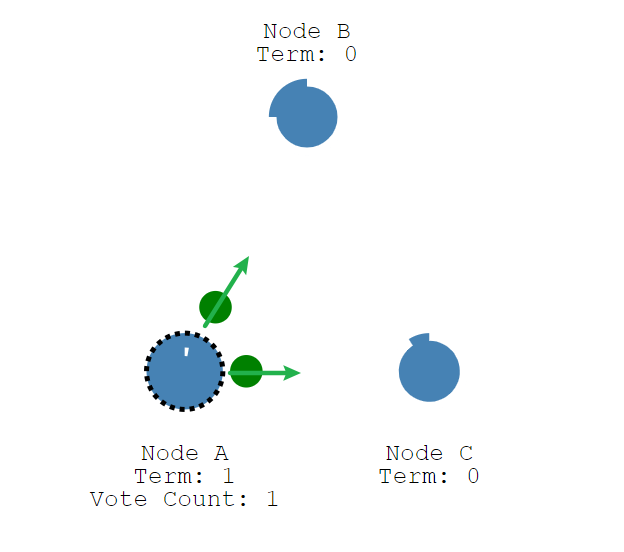
如果接受到请求的节点在这一轮中还没有投票,则为该candidate节点vote投票,并重置选举超时时间。
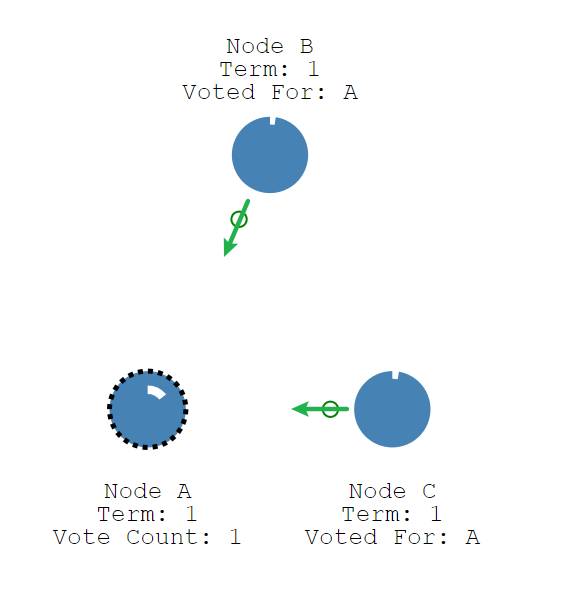
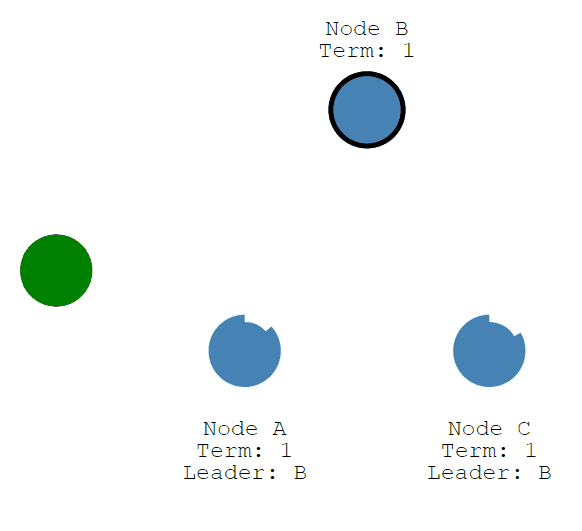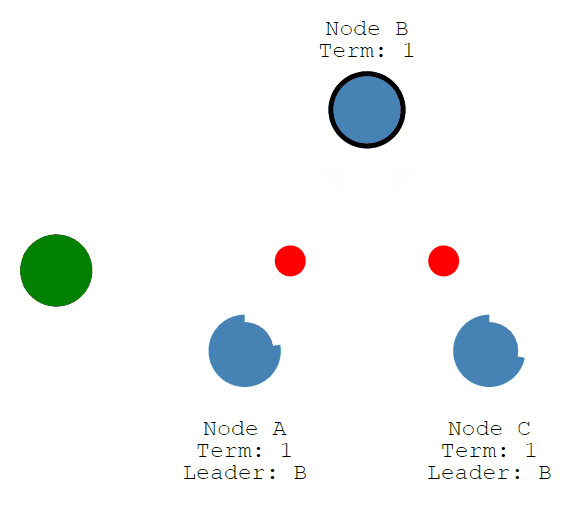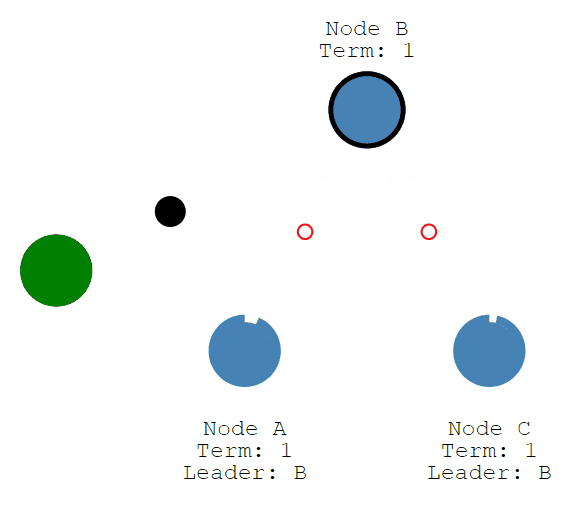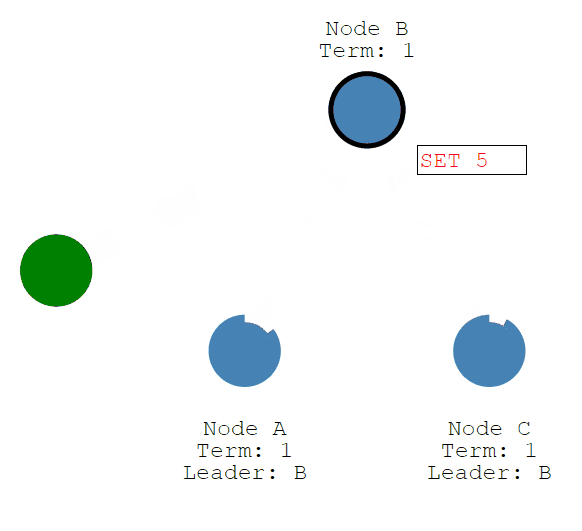
当Canditate节点收到大多数votes投票,它便成为Leader节点。
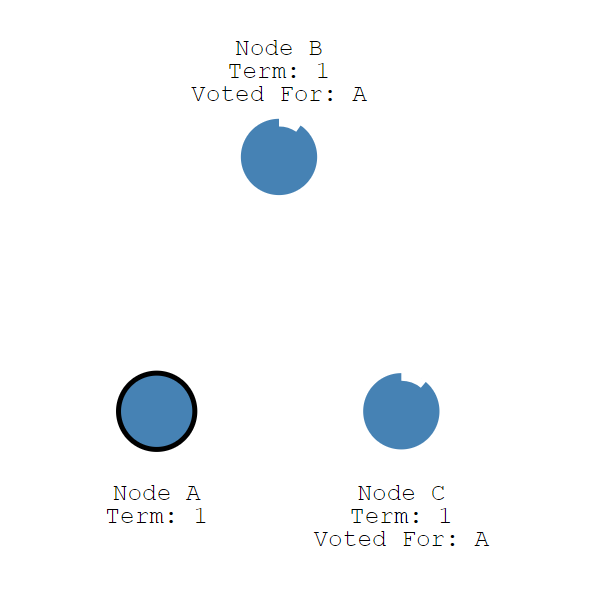
Leader节点开始向Follower节点发送追加条目消息,这些消息按照心跳超时的指定时间发送。
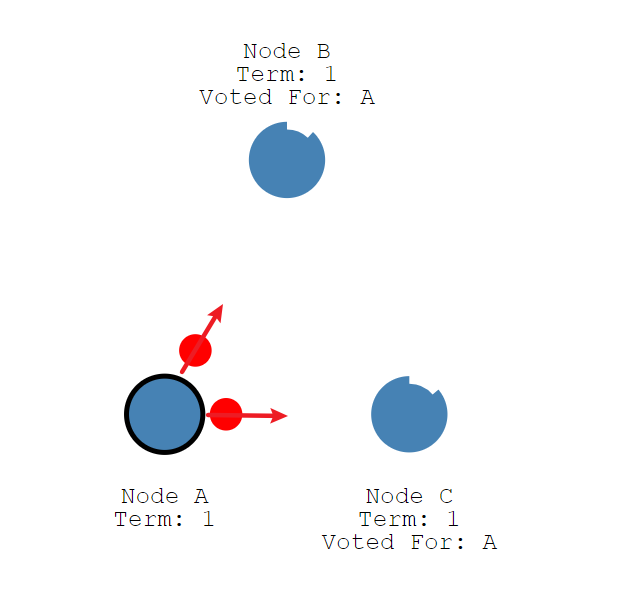
Follower节点随后响应每条追加条目信息。
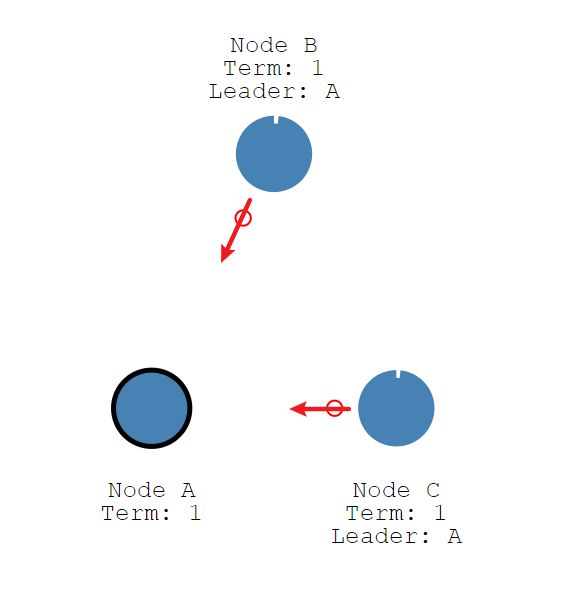
这个选举期限将持续到Follower节点停止接收来自Leader节点的心跳并成为候选人为止。
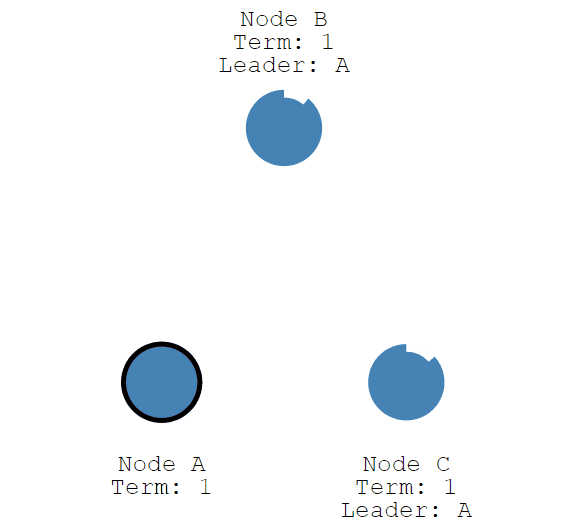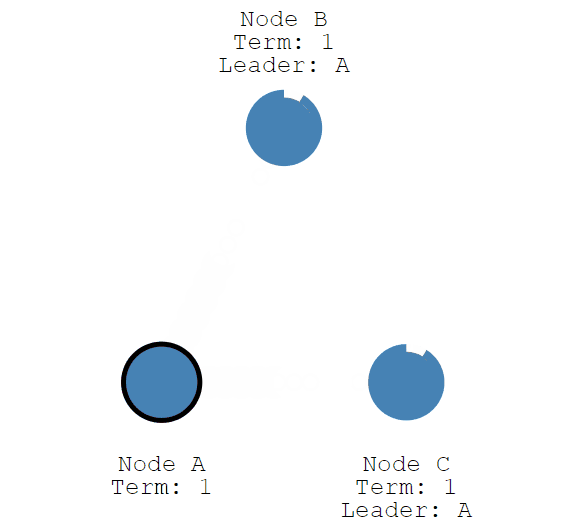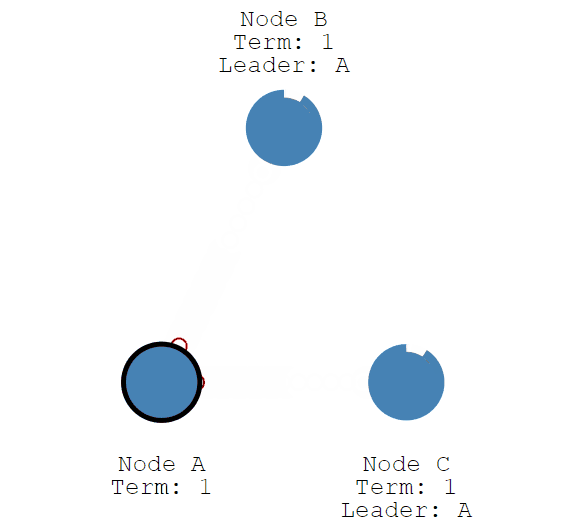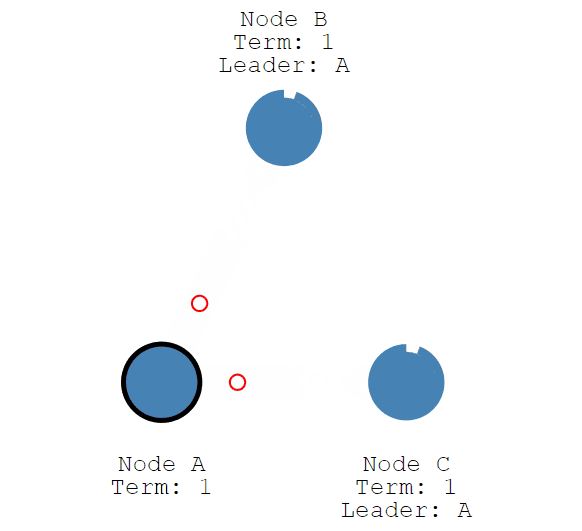
2、Leader选举之重新选举
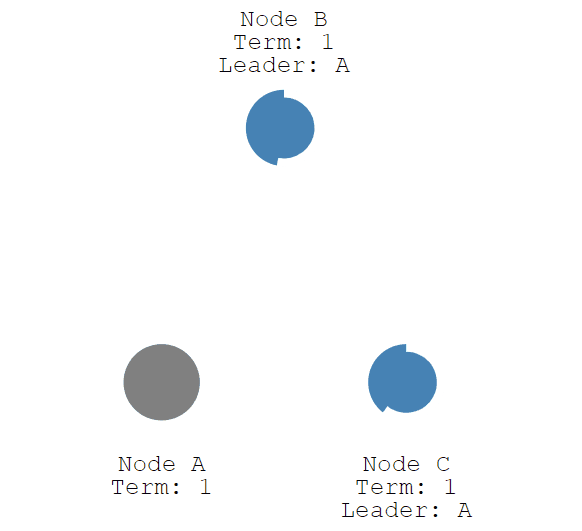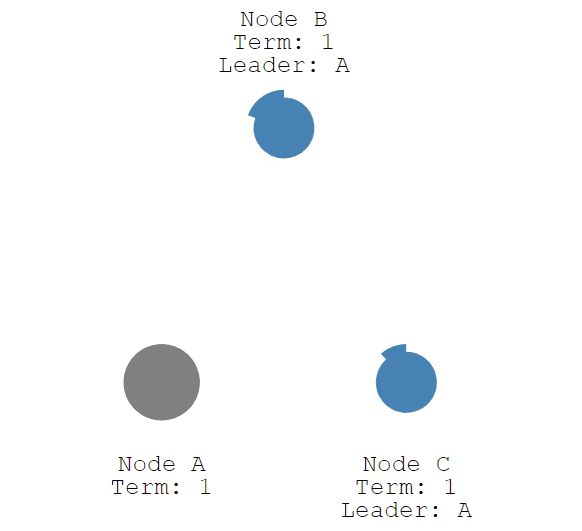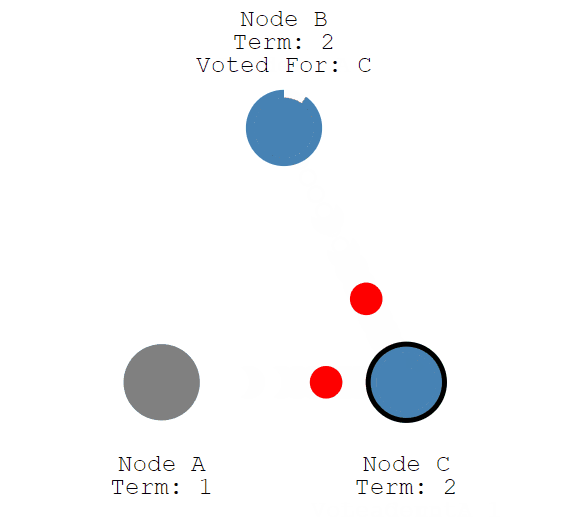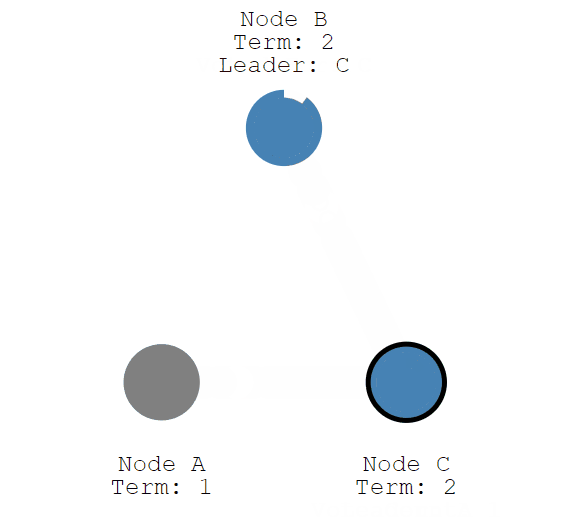
接下来我们停止leader节点(节点A)并观察一下重新选举leader的过程。
节点C从Follower变为Canditate的随机时间比节点B短,率先发起了投票,所以抢得了Leader节点。
现在,节点C成为第二轮选举期限的Leader节点。
3、Leader选举之分裂投票
需要多数投票才能保证每个任期只能选举一名领导人,如果两个节点同时成为领导人,可能会发生分裂投票。
让我们来看看分裂投票的例子。如下图所示,节点A和节点D两个节点同时成为Canditate并开始了新一轮选举,并且每个节点都先于另一个节点到达单个Follower节点,所以每个Canditate都收到了同等数量的投票,且均不超过半数节点。
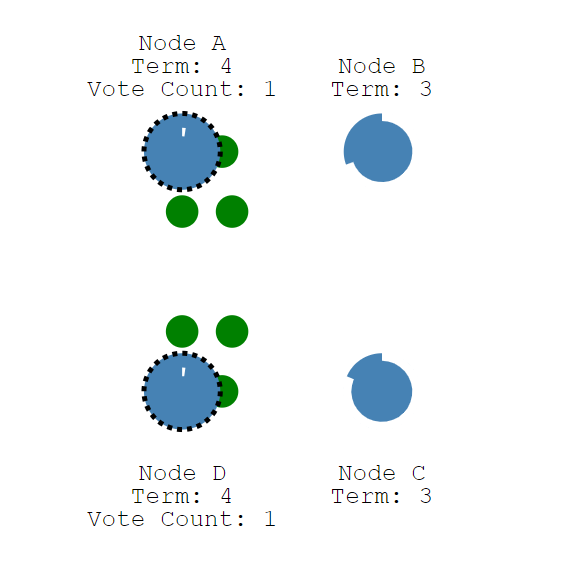

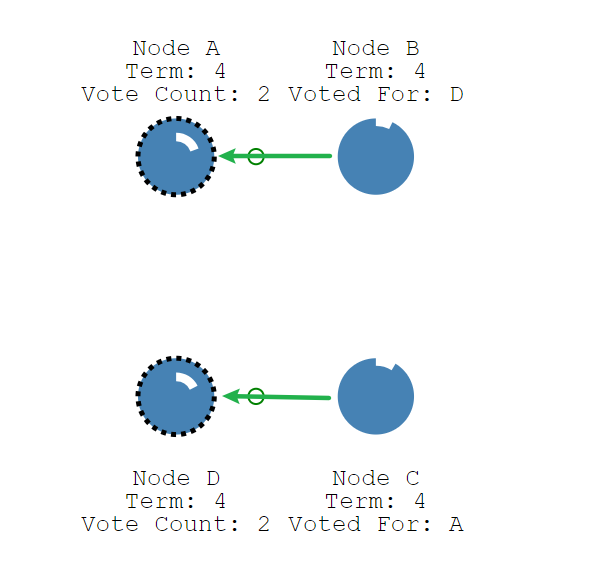
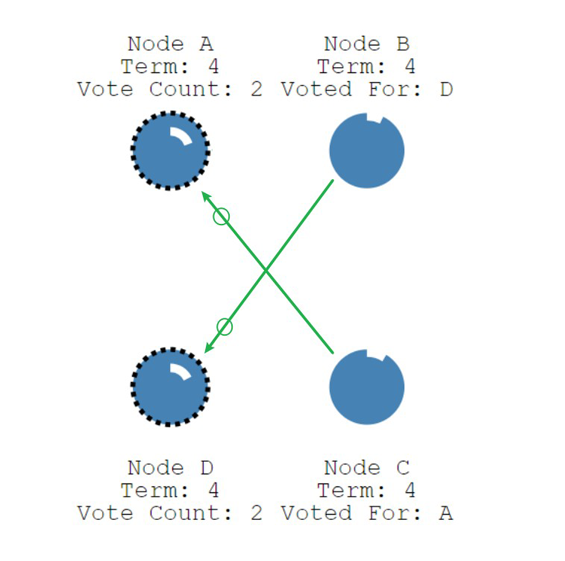

每个Canditate在无法成为Leader节点后,会重新成为Follower节点,并重置竞选超时时间,该超时时间是随机的,这使得不同的节点不会总是同时成为Canditate节点,使得选出唯一Leader成为可能。
(三)日志复制Log Replication
日志复制是Raft共识算法中的另一个核心实现,它是确保所有节点能够他同步数据的关键。
一旦我们选出了领导者,我们需要将对系统的所有更改复制到所有节点。这是通过使用用于heartbeats的相同Append Entries消息来完成的。

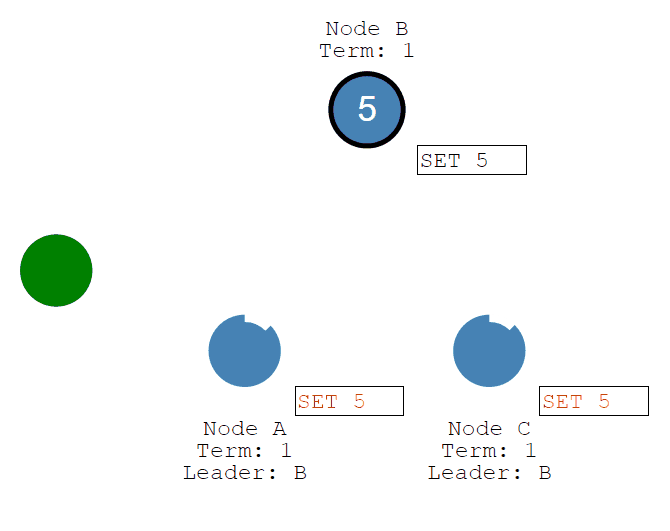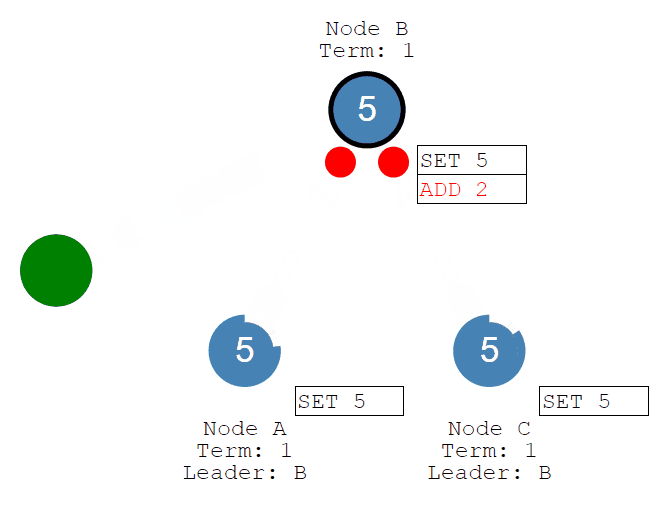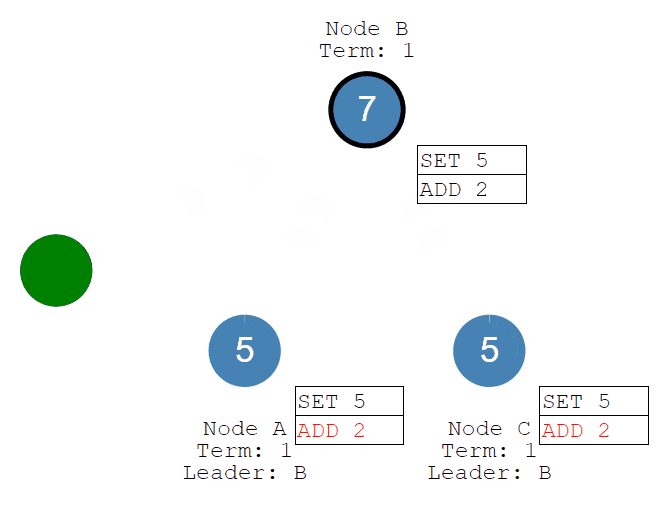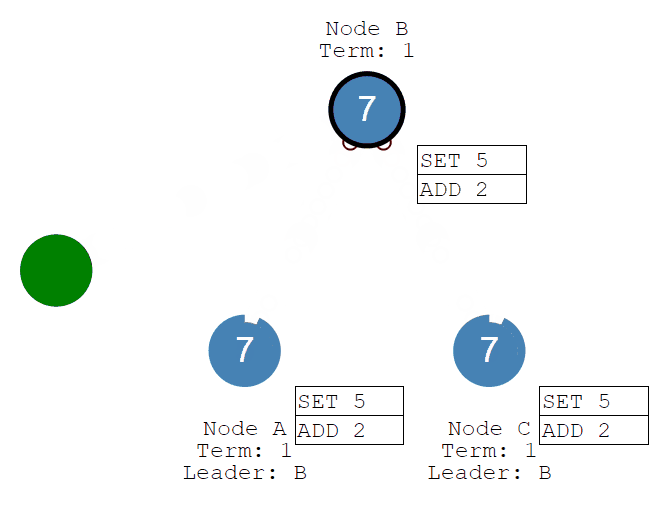
首先客户端发送修改给leader,这个修改将被追加到leader的log中。
然后修改将随着Leader的心跳发送给Followers。
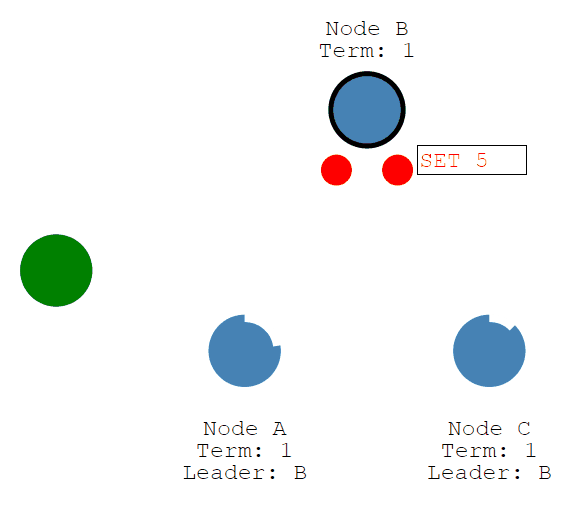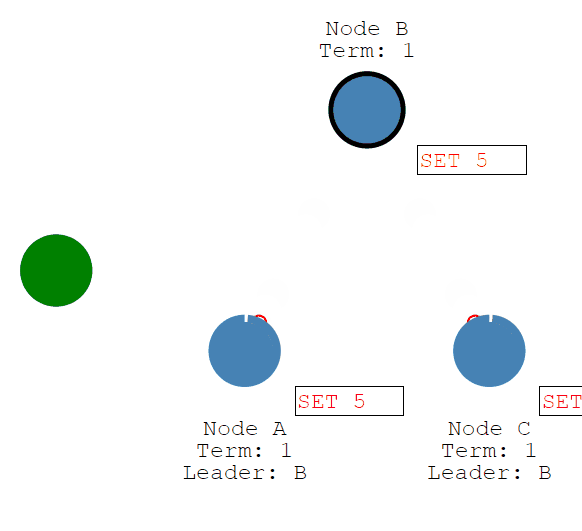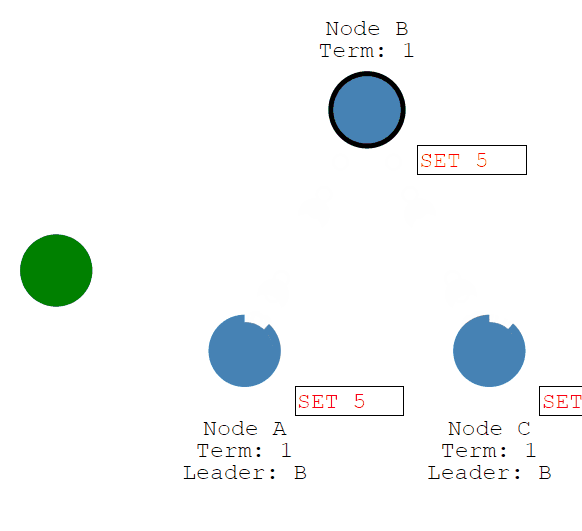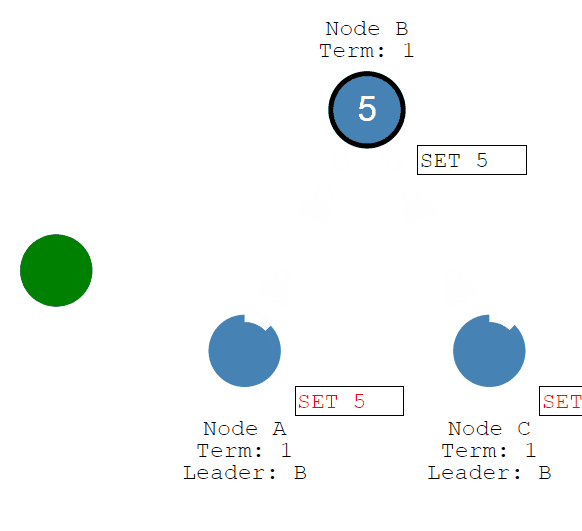
一旦大多数Follower承认它,Leader就会提交一个条目......然后提交一个响应给客户端。
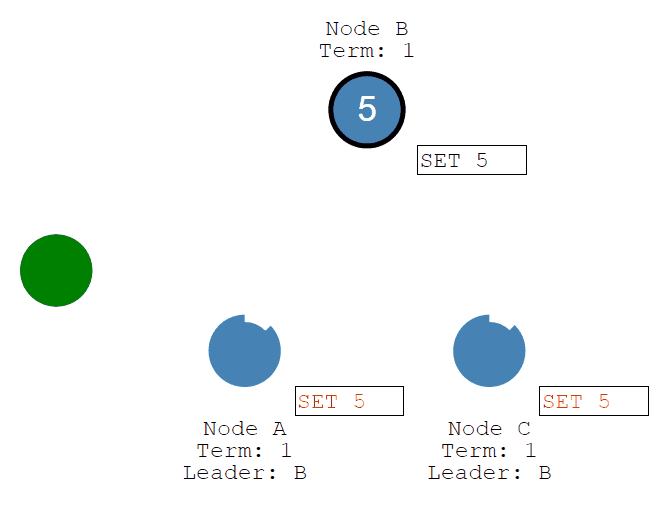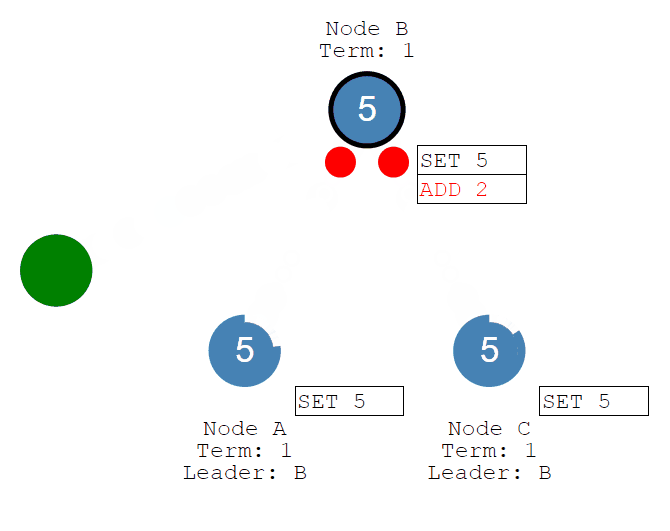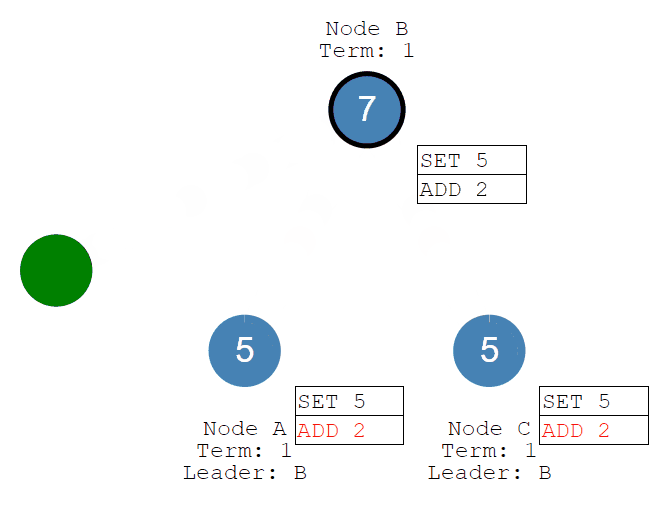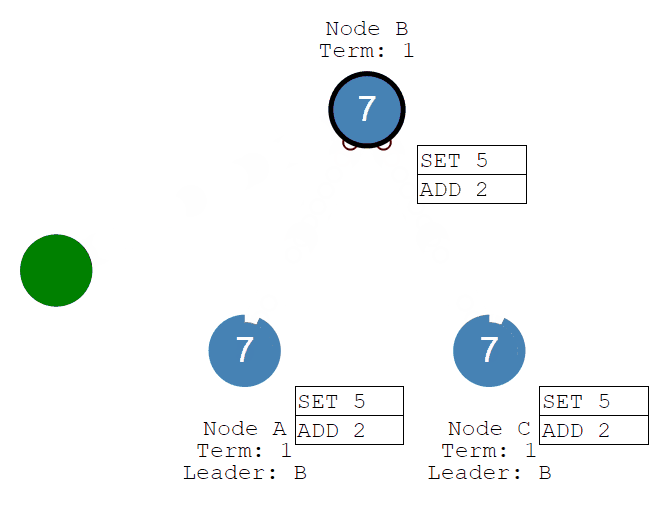
随后客户端发送add 2的命令,经过Leader接收、Followers同步commit,系统的值将被更新为7。
(四)网络分区一致性
Raft甚至可以在出现网络分区时维持一致性。
现在我们在A&B、C&D&E之间增加一个分区,因为分区的存在,现在我们在不同的terms中拥有两个Leaders。
现在我们尝试增加另外一个客户端来尝试更新两个Leaders,客户端1将尝试更新Node B的值为3,node B无法复制到多数节点,因此其日志条目保持未提交状态。
另一个客户端2尝试更新Node D的值为8,这个操作将成功,因为它可以复制到多数节点。
现在我们尝试恢复网络分区,Node B将看到更高的选举term并下台,Node A&B都将回滚他们未提交的entries并同步新Leader的log。因此我们的log实现了跨集群一致性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号