并查集
并查集
并查集主要用于解决一些元素分组的问题。它管理一系列不相交的集合,主要由一个整型数组pre[ ]和两个函数find( )、join( )构成:
-
pre[ ]:记录了每个点的前驱节点是谁
-
find(x):用于查找指定节点 x 属于哪个集合
-
join(x,y):用于合并两个节点 x 和 y
find函数:
int find(int x) //查找x的根节点
{
while(pre[x] != x) //如果x的上级不是自己(则说明找到的点不是根节点)
x = pre[x]; //x继续找他的上级,直到找到根节点为止
return x; //返回根节点
}
join函数:
执行逻辑:
- 寻找 x 的根节点;
- 寻找 y 的根节点;
- 如果 x 和 y 不相等,则随便选一个作为另一个的上级,如此一来就完成了 x 和 y 的合并。
void join(int x,int y)
{
int fx=find(x), fy=find(y);
if(fx != fy)
pre[fx]=fy;
}
路径压缩算法之一(优化find( )函数)
前面介绍的 join(x,y) 实际上为我们提供了一个将不同节点进行合并的方法。通常情况下,我们可以结合着循环来将给定的大量数据合并成为若干个更大的集合(即并查集)。但是问题也随之产生,我们来看这段代码:
if(fx != fy)
pre[fx]=fy;
这里并没有明确谁是谁的前驱的规则,而是我直接指定后面的数据作为前面数据的前驱。那么这样就导致了最终的树状结构无法预计,即有可能是良好的 n 叉树,也有可能是单支树结构。试想,如果最后真的形成单支树结构,那么它的效率就会及其低下(树的深度过深,那么查询过程就必然耗时)。
实现:
从上面的查询过程中不难看出,当从某个节点出发去寻找它的根节点时,我们会途径一系列的节点,在这些节点中,除了根节点外,其余所有节点都需要更改直接前驱为根节点。
因此,基于这样的思路,我们可以通过递归的方法来逐层修改返回时的某个节点的直接前驱(即pre[x]的值)。简单说来就是将x到根节点路径上的所有点的pre(上级)都设为根节点。下面给出具体的实现代码:
int find(int x) //查找结点 x的根结点
{
if(pre[x] == x) return x; //递归出口:x的上级为 x本身,即 x为根结点
return pre[x] = find(pre[x]); //此代码相当于先找到根结点 rootx,然后pre[x]=rootx
}
该算法存在一个缺陷:只有当查找了某个节点的根节点后,才能对该查找路径上的各节点进行路径压缩。换言之,第一次执行查找操作的时候是实现没有压缩效果的,只有在之后才有效。
路径压缩算法之二(加权标记法)
主要思路:
加权标记法需要将树中所有节点都增设一个权值,用以表示该节点所在树中的高度(比如用rank[x]=3表示 x 节点所在树的高度为3)。这样一来,在合并操作的时候就能通过这个权值的大小来决定谁当谁的上级。
在合并操作的时候,假设需要合并的两个集合的代表元分别为 x 和 y,则只需要令pre[x] = y 或者pre[y] = x 即可。但我们为了使合并后的树不产生退化(即:使树中左右子树的深度差尽可能小),那么对于每一个元素 x ,增设一个rank[x]数组,用以表达子树 x 的高度。在合并时,如果rank[x] < rank[y],则令pre[x] = y;否则令pre[y] = x。
举个例子,我们对以A,F为代表元的集合进行合并操作(如下图所示):
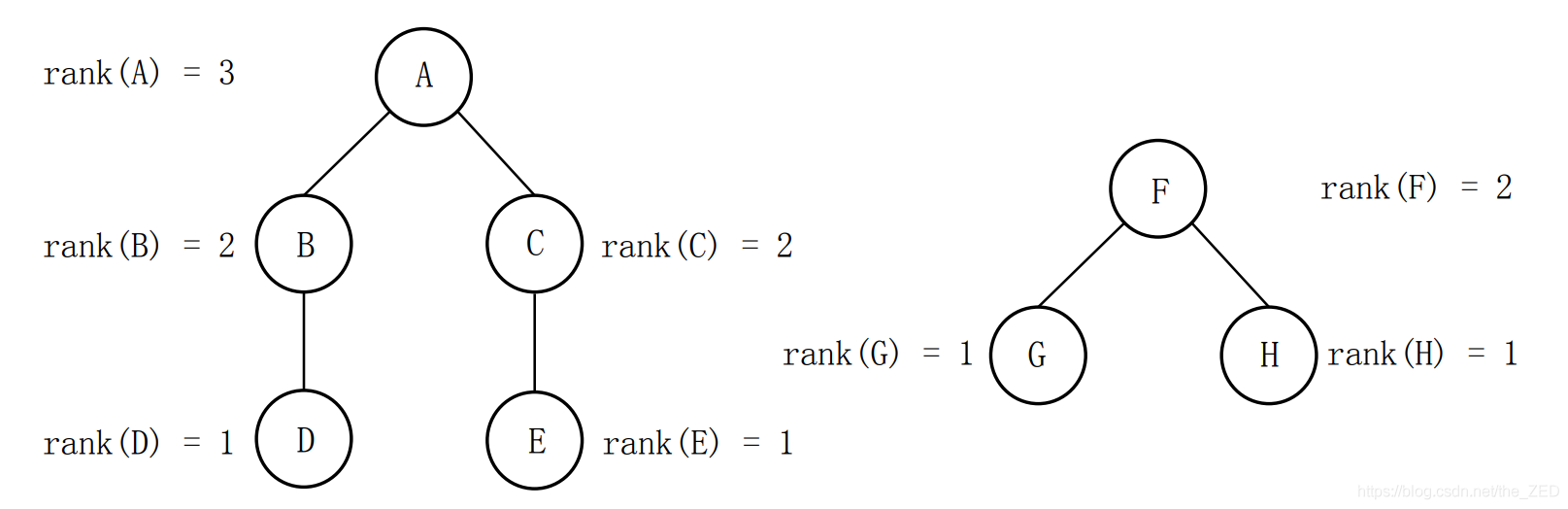
由于rank(A) > rank(F) ,因此令pre[F]= A。合并后的图形如下图所示:
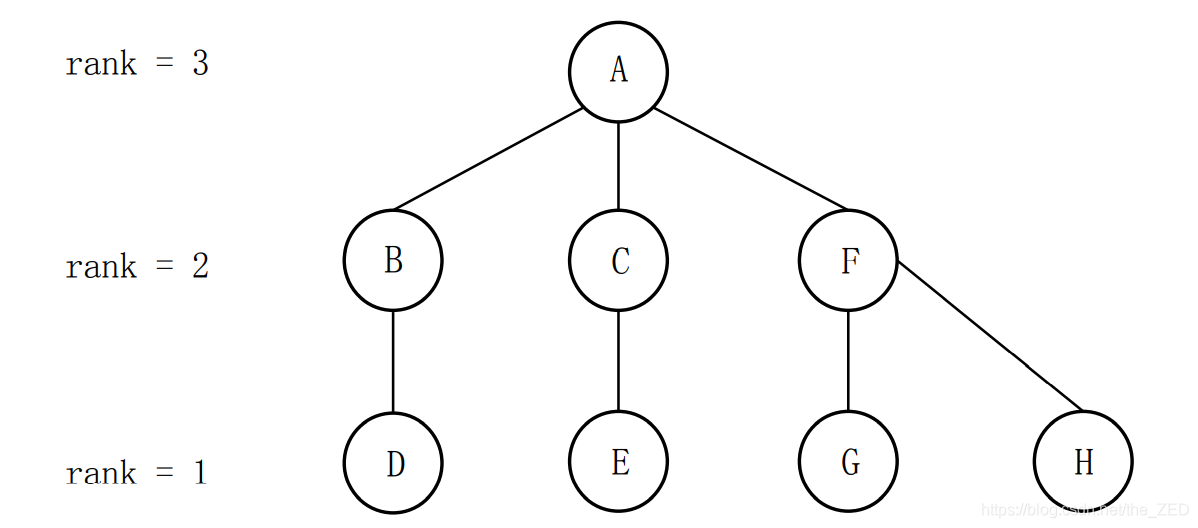
实现:
加权标记法的核心在于对rank数组的逻辑控制,其主要的情况有:
1、如果rank[x] < rank[y],则令pre[x] = y;
2、如果rank[x] == rank[y],则可任意指定上级;
3、如果rank[x] > rank[y],则令pre[y] = x;
在实际写代码时,为了使代码尽可能简洁,我们可以将第1点单独作为一个逻辑选择,然后将2、3点作为另一个选择(反正第2点任意指定上级嘛),所以具体的代码如下:
void union(int x,int y)
{
x=find(x); //寻找 x的代表元
y=find(y); //寻找 y的代表元
if(x==y) return ; //如果 x和 y的代表元一致,说明他们共属同一集合,则不需要合并,直接返回;否则,执行下面的逻辑
if(rank[x]>rank[y]) pre[y]=x; //如果 x的高度大于 y,则令 y的上级为 x
else //否则
{
if(rank[x]==rank[y]) rank[y]++; //如果 x的高度和 y的高度相同,则令 y的高度加1
pre[x]=y; //让 x的上级为 y
}
}
一般来说,一个并查集对应三个操作:
1、初始化( Init()函数 )
2、查找函数( Find()函数 )
3、合并集合函数( Join()函数 )
汇总:
const int N=1005 //指定并查集所能包含元素的个数(由题意决定)
int pre[N]; //存储每个结点的前驱结点
int rank[N]; //树的高度
void init(int n) //初始化函数,对录入的 n个结点进行初始化
{
for(int i = 0; i < n; i++){
pre[i] = i; //每个结点的上级都是自己
rank[i] = 1; //每个结点构成的树的高度为 1
}
}
int find(int x) //查找结点 x的根结点
{
if(pre[x] == x) return x; //递归出口:x的上级为 x本身,则 x为根结点
return find(pre[x]); //递归查找
}
int find(int x) //改进查找算法:完成路径压缩,将 x的上级直接变为根结点,那么树的高度就会大大降低
{
if(pre[x] == x) return x; //递归出口:x的上级为 x本身,即 x为根结点
return pre[x] = find(pre[x]); //此代码相当于先找到根结点 rootx,然后 pre[x]=rootx
}
bool isSame(int x, int y) //判断两个结点是否连通
{
return find(x) == find(y); //判断两个结点的根结点(即代表元)是否相同
}
bool join(int x,int y)
{
x = find(x); //寻找 x的代表元
y = find(y); //寻找 y的代表元
if(x == y) return false; //如果 x和 y的代表元一致,说明他们共属同一集合,则不需要合并,返回 false,表示合并失败;否则,执行下面的逻辑
if(rank[x] > rank[y]) pre[y]=x; //如果 x的高度大于 y,则令 y的上级为 x
else //否则
{
if(rank[x]==rank[y]) rank[y]++; //如果 x的高度和 y的高度相同,则令 y的高度加1
pre[x]=y; //让 x的上级为 y
}
return true; //返回 true,表示合并成功
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· winform 绘制太阳,地球,月球 运作规律
· 上周热点回顾(3.3-3.9)