注意力机制 Non-local Neural Networks
Non-local Neural Networks
注意力机制之前常用于语言处理,这篇文章是自注意力机制在视觉处理领域的核心之作。
Motivation
卷积运算和循环运算被用于捕捉局部关系,进行特征的处理,但是存在以下问题:
- 处理远距离关系时依靠层数的堆叠增大感受野,效率不高
- 基础块的堆叠会导致层数过深,前面网络微小参数变化将对后面网络的输出影响很大,这使得参数优化困难
- 处理远距离之间的相互关系还是相当困难
Contribution
作者基于图片滤波领域的非局部均值滤波操作思想,提出了一个泛化、简单、可直接嵌入到当前网络的非局部操作算子,具有以下优点:
- 能够处理远距离关系(包括了时间,空间,时空)
- 模块结构简单,只有几层参数
- 结合resnet做成了基础模块,具有很强的适用性
Approach
这个非局部算子的作用是:计算当前位置与其他所有位置的相似性,得到其他所有位置对当前位置的贡献度,然后通过乘法与加发,将其他位置的值 * 权重累加到当前位置,达到参考所有位置,传递远距离信息的目的。
相较于卷积操作进行局部卷积,非局部算子可以“卷积全局”,通过分配不同的权重调整卷积后的feature。
非局部算子泛化公式
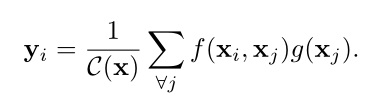
x
i
x_i
xi: 位置i的feature,位置i是泛化的表达,可以是序列的位置,图片上的点,视频的帧。
y
i
y_i
yi: 经过非局部运算后i位置的feature
g
(
x
j
)
:
g(x_j):
g(xj): x的变换函数,可以更好提取特征
f
(
x
i
,
x
j
)
:
f(x_i, x_j):
f(xi,xj): 计算i位置与j位置的相似度
C
(
x
)
:
C(x):
C(x): 归一化函数
相似度度量函数:

- 对两个位置点乘计算相似度(类似于余弦距离,点乘也可以计算两个向量的相似性,且更容易操作),通过指数映射放大差异。
- 在嵌入空间中计算高斯距离,值得注意的是,这个公式加上 C ( x ) C(x) C(x)的就是使用 s o f t m a x softmax softmax函数进行归一化,而 y = s o f t m a x ( x T W θ T W φ x ) g ( x ) y = softmax(x^TW^T_θW_φx)g(x) y=softmax(xTWθTWφx)g(x)实际上就是语言处理领域自注意力机制的通用表达。
- 变换后点乘
- concat后进行非线性变化
后面作者实验证明这几种方法的性能差不多。
变换函数:
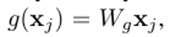
W
g
W_g
Wg会学习如何更好地提取特征,嵌入空间
模块化:
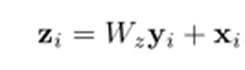
z
i
z_i
zi是通过非局部模块后的feature,通过跳跃连接进行模块的连接,使得非局部算子可以通过迁移学习用于其他预训练模型。下面是模块使用第二种相似度度量方法的一个示例:

以处理(256,256)的图片为例,T=1,H=W=256,通道数是1024
f
(
x
i
,
x
j
)
f(x_i, x_j)
f(xi,xj) 会计算出图片上任一
i
i
i位置与其他j位置的相似度,并且通过softmax归一化到【0,1】之间,表示为
o
u
t
1
out1
out1。
g
g
g 操作先会学习如何更好地提取特征,然后与
o
u
t
1
out1
out1 进行乘法。通过乘法,每个位置
i
i
i 利用
o
u
t
1
out1
out1 的权值信息,结合
g
g
g 的feature信息,得到其他位置
j
j
j 对于此位置的贡献和,并应用到所有通道中。最后通过跳跃连接组成非局部模块。
Experiments
性能实验
进行了视频与图像不同维度,不同数据集的测试,验证了非局部模块的效果:
Kinetics (video for human action categories classification task)
- 2D ConvNet baseline (C2D)
- ResNet-50 C2D
- Inflated 3D ConvNet (I3D)
Charades (video for multi-label classification task)
COCO (images)
- non-local block in Mask R-CNN for object detection/segmentation and
keypoint detection
烧蚀实验
从如何初始化非局部算子,在网络哪些结构处使用,使用的数量,分别在时间、空间、时空维度的影响都做了详细的对比。
- Instantiations
- Which stage to add non-local blocks
- Going deeper with non-local blocks
- Non-local in spacetime
- Non-local net vs. 3D ConvNet
- …
Discussion
文章将注意力机制应用于了图像处理领域,并考虑了泛化与适用性,实验工作十分详实,对后面的工作有十分强的启发效果。
值得思考的是:
- 模型复杂度问题,矩阵乘法将消耗大量的缓存资源。原因在于需要计算位置与其他所有位置的关系,现在此方面的一些研究包括直接学习注意力参数Synthesizer: Rethinking Self-Attention in Transformer Models、矩阵分解Rethinking Attention with Performers等。
- 本文着重于考虑空间注意力的问题,后续的文章中有不少研究通道间的相关关系,以及同时考虑空间与通道的关系。
References
Wang, X., Girshick, R., Gupta, A., & He, K. (2018). Non-local Neural Networks. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 7794–7803. https://doi.org/10.1109/CVPR.2018.00813
https://zhuanlan.zhihu.com/p/53010734
https://zhuanlan.zhihu.com/p/165007930
https://zhuanlan.zhihu.com/p/280864164
