
rdtsc
LFENCE
https://blog.csdn.net/liuhhaiffeng/article/details/106493224
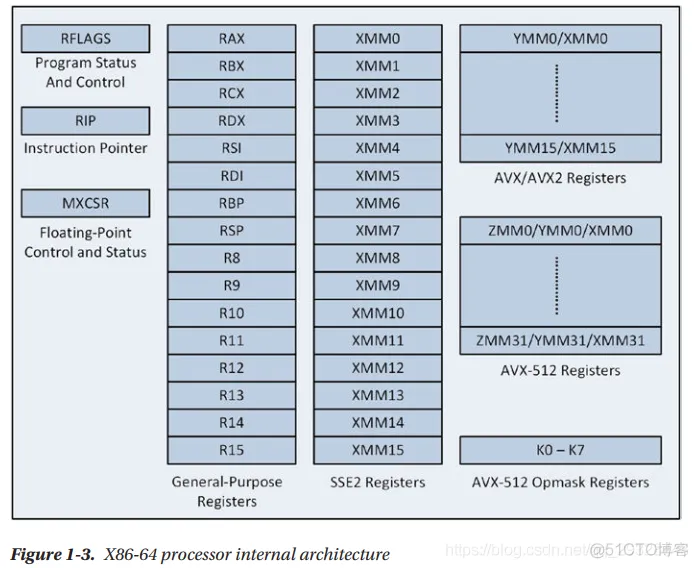
| Platform | Return Value | Parameter Registers | Additional Parameters | Stack Alignment | Scratch Registers | Preserved Registers | Call List |
|---|---|---|---|---|---|---|---|
| System V i386 | eax, edx | none | stack (right to left)1 | eax, ecx, edx | ebx, esi, edi, ebp, esp | ebp | |
| System V X86_642 | rax, rdx | rdi, rsi, rdx, rcx, r8, r9 | stack (right to left)1 | 16-byte at call3 | rax, rdi, rsi, rdx, rcx, r8, r9, r10, r11 | rbx, rsp, rbp, r12, r13, r14, r15 | rbp |
| Microsoft x64 | rax | rcx, rdx, r8, r9 | stack (right to left)1 | 16-byte at call3 | rax, rcx, rdx, r8, r9, r10, r11 | rbx, rdi, rsi, rsp, rbp, r12, r13, r14, r15 | rbp |
| ARM (32-bit) | r0, r1 | r0, r1, r2, r3 | stack | 8 byte4 | r0, r1, r2, r3, r12 | r4, r5, r6, r7, r8, r9, r10, r11, r13, r14 |

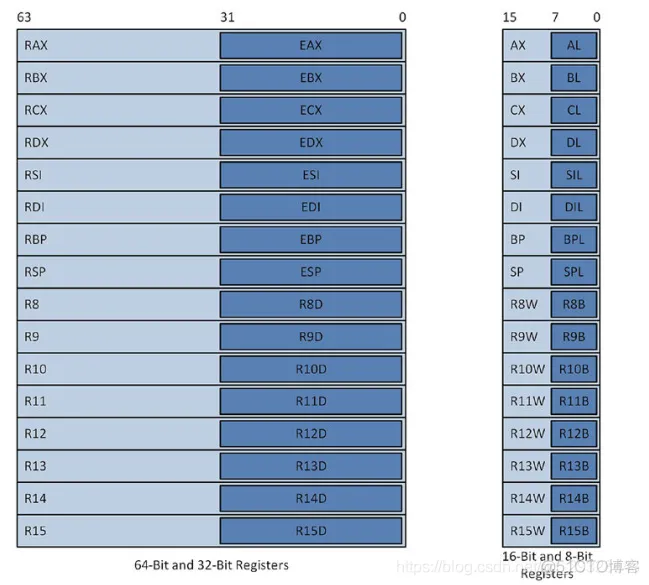
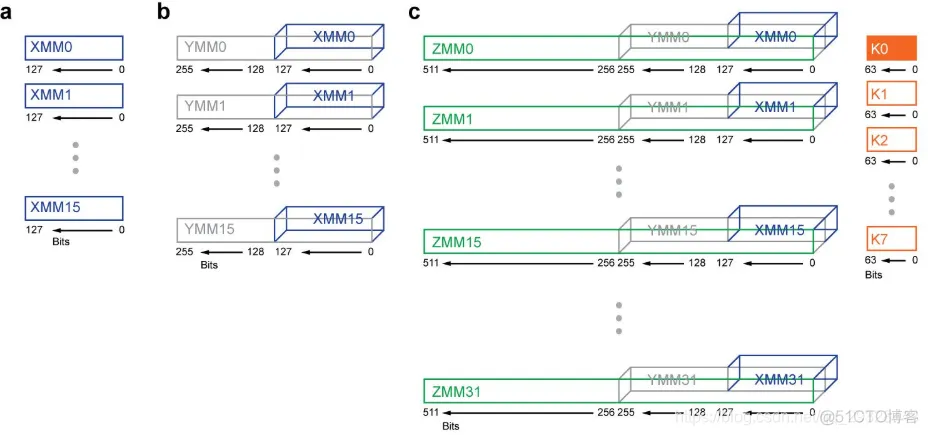
新的64位寄存器(r8-r15),在命名方式上,也从”exx”变为”rxx”,但仍保留”exx”进行32位操作,下表描述了各寄存器的命名和作用。
|
描述 |
32位 |
64位 |
|
通用寄存器组 |
eax |
rax |
|
ecx |
rcx |
|
|
edx |
rdx |
|
|
ebx |
rbx |
|
|
esp |
rsp |
|
|
ebp |
rbp |
|
|
esi |
rsi |
|
|
edi |
rdi |
|
|
- |
r8~r15 |
|
|
浮点寄存器组 |
st0~st7 |
st0~st7 |
|
XMM寄存器组 |
XMM0~XMM7 |
XMM0~XMM15 |
CC=g++
CFLAG=-c\ -O2\ -W\ -fPIC\ -g
LNK=g++
EXFLAG=-fno-pie
DLFLAG=-shared
LB=ar
LBFLAG=cqs
L=-L
l=-l
o=-o
set path=%VS120COMNTOOLS%../../vc/bin;%path%
call vcvars32.bat
set CC=cl
set CFLAG=-c -O2 -W3 -Zi -GR -EHsc -nologo -MDd
set LNK=link
set EXFLAG=-nologo
set DLFLAG=-dll -nologo -debug
set LB=lib
set LBFLAG=-nologo
set LL=-libpath:
set l=
set o=-out:
ALT+5是寄存器窗口:
ALT+6是内存地址窗口:
ALT+7是调用堆栈的窗口(在程序很大的时候通过堆栈调用窗口来看程序在哪个函数停止的,里面变量哪里是空指针等,是很有用的):
ALT+8是反汇编窗口:
dumpbin
https://learn.microsoft.com/en-us/cpp/build/x64-software-conventions?view=msvc-170
https://learn.microsoft.com/en-us/cpp/build/x64-calling-convention?view=msvc-170
| Parameter type | fifth and higher | fourth | third | second | leftmost |
|---|---|---|---|---|---|
| floating-point | stack | XMM3 | XMM2 | XMM1 | XMM0 |
| integer | stack | R9 | R8 | RDX | RCX |
Aggregates (8, 16, 32, or 64 bits) and __m64 |
stack | R9 | R8 | RDX | RCX |
| Other aggregates, as pointers | stack | R9 | R8 | RDX | RCX |
__m128, as a pointer |
stack | R9 | R8 | RDX | RCX |
| Register | Status | Use |
|---|---|---|
| RAX | Volatile | Return value register |
| RCX | Volatile | First integer argument |
| RDX | Volatile | Second integer argument |
| R8 | Volatile | Third integer argument |
| R9 | Volatile | Fourth integer argument |
| R10:R11 | Volatile | Must be preserved as needed by caller; used in syscall/sysret instructions |
| R12:R15 | Nonvolatile | Must be preserved by callee |
| RDI | Nonvolatile | Must be preserved by callee |
| RSI | Nonvolatile | Must be preserved by callee |
| RBX | Nonvolatile | Must be preserved by callee |
| RBP | Nonvolatile | May be used as a frame pointer; must be preserved by callee |
| RSP | Nonvolatile | Stack pointer |
| XMM0, YMM0 | Volatile | First FP argument; first vector-type argument when __vectorcall is used |
| XMM1, YMM1 | Volatile | Second FP argument; second vector-type argument when __vectorcall is used |
| XMM2, YMM2 | Volatile | Third FP argument; third vector-type argument when __vectorcall is used |
| XMM3, YMM3 | Volatile | Fourth FP argument; fourth vector-type argument when __vectorcall is used |
| XMM4, YMM4 | Volatile | Must be preserved as needed by caller; fifth vector-type argument when __vectorcall is used |
| XMM5, YMM5 | Volatile | Must be preserved as needed by caller; sixth vector-type argument when __vectorcall is used |
| XMM6:XMM15, YMM6:YMM15 | Nonvolatile (XMM), Volatile (upper half of YMM) | Must be preserved by callee. YMM registers must be preserved as needed by caller. |
整数寄存器
AArch64 体系结构支持 32 个整数寄存器:
| 注册 | 波动 | 角色 |
|---|---|---|
| x0-x8 | 易失的 | 参数/结果临时寄存器 |
| x9-x15 | 易失的 | 临时寄存器 |
| x16-x17 | 易失的 | 过程内部调用临时寄存器 |
| x18 | 不可用 | 保留的平台寄存器:在内核模式下,指向当前处理器的 KPCR;在用户模式下,指向 TEB |
| x19-x28 | 非易失性的 | 临时寄存器 |
| x29/fp | 非易失性的 | 帧指针 |
| x30/lr | 推送、请求和匿名 | 链接寄存器:被调用方函数必须保留它用于其自己的返回,但调用方的值将丢失。 |
每个寄存器可以作为完整 64 位值(通过 x0-x30)或作为 32 位值(通过 w0-w30)进行访问。 32 位操作将结果零扩展到最多 64 位。
有关参数寄存器使用的详细信息,请参阅“参数传递”一节。
与 AArch32 不同,程序计数器 (PC) 和堆栈指针 (SP) 不是索引寄存器。 它们的访问方式受到限制。 另请注意,没有 x31 寄存器。 该编码用于特殊用途。
与 ETW 和其他服务使用的快速堆栈浏览兼容需要帧指针 (x29)。 它必须指向堆栈上的前一个 {x29, x30} 对。
浮点/SIMD 寄存器
AArch64 体系结构还支持 32 个浮点/SIMD 寄存器,下面进行了总结:
| 注册 | 波动 | 角色 |
|---|---|---|
| v0-v7 | 易失的 | 参数/结果临时寄存器 |
| v8-v15 | 推送、请求和匿名 | 低 64 位是非易失性的。 高 64 位是易失性的。 |
| v16-v31 | 易失的 | 临时寄存器 |
每个寄存器可以作为完整 128 位值(通过 v0-v31 或 q0-q31)进行访问。 它可以作为 64 位值(通过 d0-d31)、作为 32 位值(通过 s0-s31)、作为 16 位值(通过 h0-h31)或作为 8 位值(通过 b0-b31)进行访问。 小于 128 位的访问仅访问完整 128 位寄存器的较低位。 除非另外指定,否则它们使其余位保持不变。 (AArch64 与 AArch32 不同,其中较小寄存器在较大寄存器顶部打包。)
浮点控制寄存器 (FPCR) 对其中的各个位域具有特定要求:
| Bits | 含义 | 波动 | 角色 |
|---|---|---|---|
| 26 | AHP | 非易失性 | 备选半精度控制。 |
| 25 | DN | 非易失性 | 默认 NaN 模式控制。 |
| 24 | FZ | 非易失性的 | 清零模式控制。 |
| 23-22 | RMode | 非易失性的 | 舍入模式控制。 |
| 15、12-8 | IDE/IXE/等 | 非易失性 | 异常捕获启用位,必须始终为 0。 |
系统寄存器
与 AArch32 一样,AArch64 规范提供三个系统控制的“线程 ID”寄存器:
| 注册 | 角色 |
|---|---|
| TPIDR_EL0 | 保留。 |
| TPIDRRO_EL0 | 包含当前处理器的 CPU 编号。 |
| TPIDR_EL1 | 包含当前处理器的 KPCR 结构。 |
在服务性能优化的时候,第一步就是定位瓶颈出现在哪里,然后进行针对性的优化。对于非线上的服务,可以perf + 压测,找到相应的热点;对于线上服务,不太方便在生产环境挂上perf或者其他性能排查工具。一般都是预埋log,对可能的热点函数或者大循环的函数的执行时间进行日志监控。
1. 使用cpu周期作为记录时间的基准
Linux提供的API—gettimeofday()可以获取微秒级的精度。但是,首先它不能提供纳秒级精度,其次,他是一个库函数(可能不是系统调用),自身就有一定的开销,当我需要纳秒级精度时,误差会很大。
而且,测定函数的性能以时钟周期为单位比纳秒更加合理。当不同型号的CPU的频率不同时,运行时间可能差很多,但是时钟周期应该差不了多少(如果指令集一样的话)。
那么怎么测定时钟周期呢?x86处理器为我们提供了rdtsc指令。从pentium开始,很多x86处理器都引入了TSC(Time Stamp Counter),一个64位的寄存器,每个CPU时钟周期其值加一。它记录了CPU从上电开始总共经历的时钟周期数。一个2.5GHz的CPU如果全速运行的话,那么其TSC就会在一秒内增加2,500,000,000。 (1GHz = 10^9 Hz)
rdtsc指令把TSC的低32位存放在EAX寄存器中,把TSC的高32位存放在EDX寄存器中。该指令可以在用户态执行。可以使用GCC内嵌汇编实现在用户态获取时钟周期:
uint64_t current_cycles()
{
uint32_t low, high;
asm volatile("rdtsc" : "=a"(low), "=d"(high));
return ((uint64_t)low) | ((uint64_t)high << 32);
}
int main()
{
uint64_t tick,tick1,time;
tick = current_cycles();
sleep(1);
tick1 = current_cycles();
time = (unsigned)((tick1-tick));
printf("\ntime in %lu\n",time);
return 0;
}
$ lscpu
Architecture: x86_64
CPU MHz: 2494.140
$ ./a.out
time in 2494289636 // 1秒钟 在2.4Ghz的cpu上面,1秒钟会产生24亿tick数
可以简单的对比一下,使用rdtsc获得时间会比gettimeofday的方式开销小的多,我就不在这里列举了。

2. 利用guard机制统计函数的执行时间
利用创建对象的生命周期去统计函数的执行时间
class CYCLE_PROFILER
{
public:
CYCLE_PROFILER(int id):_id(id)
{
rdtscll(_tsc_begin);
}
~CYCLE_PROFILER()
{
rdtscll(_tsc_end);
unsigned long int time = _tsc_end - _tsc_begin;
printf("func id : %s, begin %lu, end %lu, use cpu tsc %lu \n"
, stat_type_str[_id], _tsc_begin, _tsc_end, time);
}
private:
int _id;
unsigned long int _tsc_begin;
unsigned long int _tsc_end;
};
int test_func()
{
CYCLE_PROFILER guard;
// do-something
return 0;
}
3. 将每次函数执行的时间进行收集和汇总,周期性的输出统计的相应函数执行的时间。对于被统计函数,执行插入一行宏就可以。
int test_func()
{
CYCLE_PROFILER((int)_type_test_func);
int times = 1000000;
while (times > 0)
{
int value = times * times;
times--;
};
return 0;
}
简单的包装了一下:
https://github.com/zhaozhengcoder/CoderNoteBook/tree/master/example_code/perd_record
4. 一种获得函数调用时间的全链路追踪方案
在gcc和g++编译的时候,可以开启一个选择finstrument-functions编译选项,这样对每个函数在进入和离开的时候,会触发一个系统的回调。
__cyg_profile_func_enter(void *callee, void *caller);
__cyg_profile_func_exit(void *callee, void *caller);
那原理就很简单了,在每个函数进入的时候,插入一段逻辑,获得程序在这个函数中的执行时间和caller。
#define DUMP(func, call) \
printf("%s: func = %p, called by = %p\n", __FUNCTION__, func, call)
void __attribute__((no_instrument_function))
__cyg_profile_func_enter(void *this_func, void *call_site)
{
DUMP(this_func, call_site);
}
void __attribute__((no_instrument_function))
__cyg_profile_func_exit(void *this_func, void *call_site)
{
DUMP(this_func, call_site);
}
int do_multi(int a, int b)
{
return a * b;
}
int do_calc(int a, int b)
{
return do_multi(a, b);
}
int main()
{
int a = 4, b = 5;
printf("result: %d\n", do_calc(a, b));
return 0;
}
// gcc -finstrument-functions instrfunc.c -o instrfunc
./instrfunc
__cyg_profile_func_enter: func = 0x400693, called by = 0x7ffff7829555
__cyg_profile_func_enter: func = 0x400648, called by = 0x4006ca
__cyg_profile_func_enter: func = 0x400605, called by = 0x400677
__cyg_profile_func_exit: func = 0x400605, called by = 0x400677
__cyg_profile_func_exit: func = 0x400648, called by = 0x4006ca
result: 300
__cyg_profile_func_exit: func = 0x400693, called by = 0x7ffff7829555
gprof获得性能热点就类似于这种原理,给程序的所有入口函数插入代码。获得执行时间和调用堆栈。类似的,这个开源的日志追踪库也是这个原理:https://github.com/TomaszAugustyn/call-stack-logger。
5. rdtsc可能的问题
陈硕 —— 多核时代不宜再用 x86 的 RDTSC 指令测试指令周期和时间
https://blog.csdn.net/Solstice/article/details/5196544
- cpu的是频率是可以变化的,频率变化之后,tick是不准确的,要怎么办?
- 不同核心的tick是同步的么,如果不同步怎么办?
- cpu执行的指令有可能是乱序的,可能是测量的不准确
对于问题1,2,可以查看cpu是否支持const tsc。支持这个特性的cpu,它的tsc是按照其标称频率流逝的,与CPU的实际工作频率与状态无关。
问题3,除了 TSC 要准,还要顾及 CPU 的乱序执行,尤其是如果被测的代码段较小,乱序执行可能让你的测试变得完全没意义。解决这个一般是“先同步,后计时”,在 wikipedia 上的一段代码就用 cpuid 指令来同步 (http://en.wikipedia.org/wiki/Time_Stamp_Counter)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号