
aot
https://devblogs.microsoft.com/java/aot-compilation-in-hotspot-introduction/
Introduction
In this blog post, we are going to focus on the Ahead-Of-Time (AOT) Compilation that was introduced in Java 9 (https://openjdk.java.net/jeps/295) with the addition of the jaotc command-line utility. This AOT compiler is based on the work done in Graal JIT.
We are going to explore some of the tradeoffs that the AOT compiler needs to take, and how the generated code fits in the Tiered Compilation (TC) pipeline. Then, we will go through a simple example, showing how to use the jaotc command-line utility. Finally, we are going to explore some alternatives to the AOT compiler like JIT at Startup, JIT caching, and Distributed JIT.
AOT Compilation in HotSpot
An AOT compiler’s primary capability is to generate machine code for an application without having to run the application, allowing a future run of the application to pick the generated code. Similarly, to C1 and C2, jaotc compiles Java bytecode to native code.
The primary motivator behind using AOT in Java is to bypass the interpreter. It is generally faster for the machine to execute machine code than it is to execute the code via the bytecode interpreter. In many cases, it is a definite advantage, especially for code that needs to be executed even just a few times.
Tradeoffs of generated code
An AOT compiler cannot make the same class of assumptions as a JIT compiler. The AOT compiler doesn’t have access to as much information as the JIT compiler does because the process generating and executing the application are not the same.
For example, AOT compilers are required to generate Position Independent Code (PIC) to produce shared libraries. That is because there is no way to know ahead of execution where in memory the code is loaded, blocking any assumption the AOT compiler can make on the location (relative or absolute) of a symbol; this prevents the AOT compiler from referencing the address of any symbol directly. So, whenever a symbol (such as functions and constants) is accessed, it requires the AOT compiler to generate an indirection, with the resolution happening on first access to the symbol.
On the other hand, a JIT compiler can take the address in memory of a symbol and embed it directly in the code. It works because the JIT compiler can assume the code to have a shorter lifetime than the symbol: the code generation happens after the symbol initialization (or at least the code generation initializes the symbol), and the shutdown of the process triggers the destruction of both the code and the symbol.
Another example is final static variables. A JIT compiler can make certain assumptions allowing it to generate code based on the value of the variable. But because an AOT compiler cannot know the value of the variable before the initialization of the variable – which only happens at the execution of the code – it can’t make the same assumptions. That can lead to missed optimizations opportunities like dead-code elimination or inlining.
Finally, the OS and architecture on which you execute the code and on which you generate the code are required to be the same. For example, if you want to execute the code on Windows, you cannot generate the code on Linux or macOS but only on Windows. That is because the jaotc does not support cross-compilation.
Integration with the Tiered Compilation pipeline
Introduced in Java 7, Tiered Compilation (TC) goal is to have fast startup time and fast steady-state throughput. The implementation consists of a pipeline of multiple tiers of code generation. The three main components of this pipeline are the interpreter, the C1 compiler, and the C2 compiler. It replaced the -client and -server command-line parameters available in previous versions of Java.
As the method goes through the different tiers, each tier gathers information about the method execution. This information is called Profiling Data (PD). The C2 compiler uses this PD to make certain assumptions such as what code paths are cold/warm/hot, and what types are used at any call sites. It can then generate code better suited for the specific context that it is currently executing in.
The five tiers of code generation are:
- none (0): Interpreter gathering full PD
- simple (1): C1 compiler with no profiling
- limited profile (2): C1 compiler with light profiling gathering some PD
- full profile (3): C1 compiler with full profiling gathering full PD
- full optimization (4): C2 compiler with no profiling
With jaotc, you have the option to generate code with or without support for TC. Enabling TC generates slightly slower code due to the profiling overhead. Disabling TC blocks the use of the TC pipeline leading to slower steady-state throughput.
Figure 1 and Figure 2 show the flow in the TC pipeline if you use AOT or not.
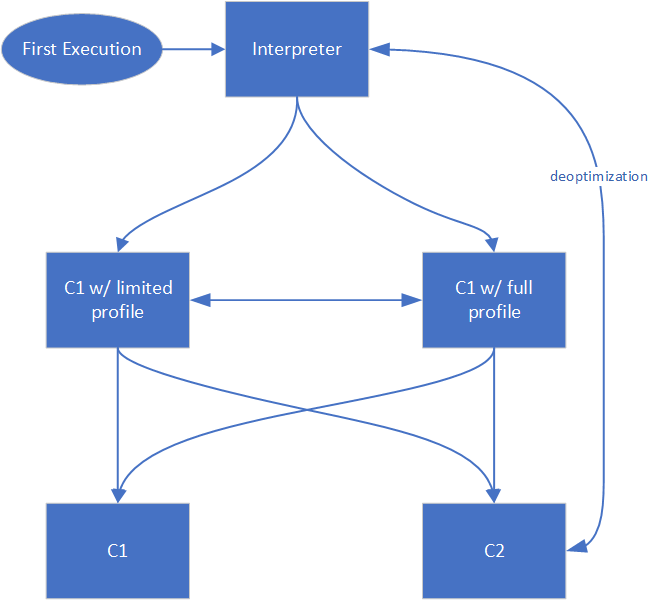 Figure 1: Tiered Compilation pipeline without AOT
Figure 1: Tiered Compilation pipeline without AOT
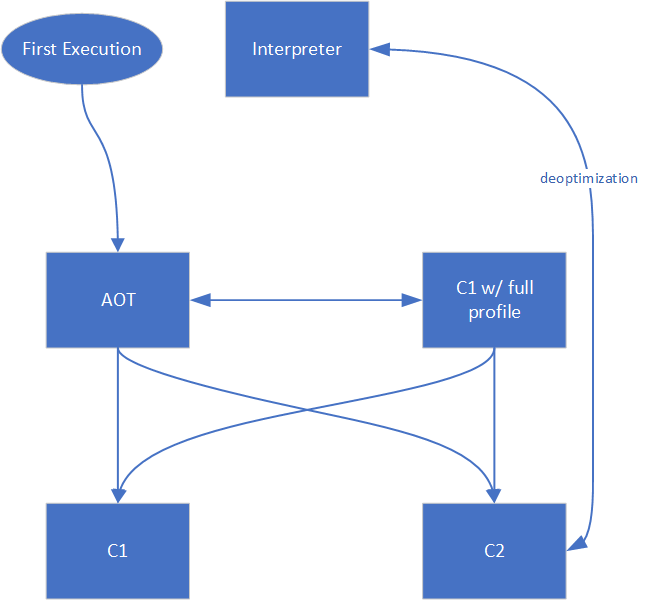 Figure 2: Tiered Compilation pipeline with AOT
Figure 2: Tiered Compilation pipeline with AOT
The difference in generated code by the AOT compiler with and without support for TC is trivial. For the TC pipeline to decide whether to compile the method at a particular tier, the generated code updates a set of counters (invocation counters, backedge counters) when executing, and whenever any of these counters overflow a given threshold, the instrumented code calls back into the runtime. This call contains all the information needed by the runtime to figure out which method has reached the threshold. It allows the runtime to decide whether to compile the method at the next tier of the TC pipeline. Given that, if you generate code that does not have support for TC, then the counters are never updated, thus never overflowed, and it never calls back into the runtime to request compilation at the next tier of the TC pipeline.
In case the code has been generated with support for TC, AOT code fits in the TC pipeline at roughly the same tier as the limited profile (2) tier. The threshold value differs, with, for example, the execution threshold to go from Tier 0 or Tier 2 to Tier 3: the default value without AOT is Tier3InvocationThreshold=200, and the default value with AOT is Tier3AOTInvocationThreshold=10000.
Usage
For the AOT compiler to successfully generate code, the same environment than for the JIT compiler need to be available. That means that all dependencies (jars, jmods) must be present and accessible to the AOT compiler.
The example below is assuming you are using Java 11 or later.
Let’s take a simple example, HelloWorld.
class HelloWorld {
public static void main(String args[]) {
System.out.println("Hello, World");
}
}
To compile it to Java bytecode, run the usual:
$> javac HelloWorld.java
If you want to run without AOT, you simply run:
$> java HelloWorld
Hello, World
If you want to run with AOT, you first need to run the AOT compiler:
$> jaotc --compile-for-tiered --output libHelloWorld.so --verbose HelloWorld
Compiling libHelloWorld.so...
1 classes found (25 ms)
Scanning HelloWorld
added <init>()V
added main([Ljava/lang/String;)V
2 methods total, 2 methods to compile (4 ms)
Freeing memory [used: 4.0 MB , comm: 12.0 MB, freeRatio ~= 66.7%] (44 ms)
Compiling with 12 threads
.
2 methods compiled, 0 methods failed (363 ms)
Freeing memory [used: 5.4 MB , comm: 18.0 MB, freeRatio ~= 70.0%] (17 ms)
Parsing compiled code (2 ms)
Freeing memory [used: 5.8 MB , comm: 24.0 MB, freeRatio ~= 75.9%] (18 ms)
Processing metadata (10 ms)
Freeing memory [used: 5.7 MB , comm: 24.0 MB, freeRatio ~= 76.2%] (18 ms)
Preparing stubs binary (0 ms)
Preparing compiled binary (0 ms)
.header: 63 bytes
.config: 43 bytes
.kls.offsets: 336 bytes
.meth.offsets: 52 bytes
.kls.dependencies: 76 bytes
.