
openmp
mac: https://mac.r-project.org/openmp/
brew install clang-omp
clang -Xclang -fopenmp -o 1 13.c -lomp
https://github.com/OpenMP/sources
http://gcc.gnu.org/onlinedocs/libgomp/Implementing-PARALLEL-construct.html
10.10 Implementing PARALLEL construct
#pragma omp parallel
{
body;
}
becomes
void subfunction (void *data)
{
use data;
body;
}
setup data;
GOMP_parallel_start (subfunction, &data, num_threads);
subfunction (&data);
GOMP_parallel_end ();
void GOMP_parallel_start (void (*fn)(void *), void *data, unsigned num_threads)
//gcc -c -o2 7.c -std=c99 -o 7.o -fopenmp -g
#include "stdio.h"
#include <omp.h>
void test() {
}
int main() {
#define count 50000
int a[count];
int b[count];
int c[count] = { 0 };
for (int i = 0; i < count; i++) {
a[i] = i + 1;
b[i] = 10;
}
printf( "CPU number: %d\n" , omp_get_num_procs());
#pragma omp parallel
{
printf("Hello! threadID=%d thraed number:%d\n", omp_get_thread_num() , omp_get_num_threads());
}
omp_set_num_threads(4);
double start = omp_get_wtime();
/*Also can use:#pragma omp parallel for num_threads(4) */
#pragma omp parallel for
for (int i = 0; i < count; i++) {
c[i] = a[i] / b[i];
test();
}
double end = omp_get_wtime();
printf("Multi-thread Time is: %lf\n" , end - start);
double t1 = omp_get_wtime();
for (int i = 0; i < count; i++) {
c[i] = a[i] / b[i];
test();
}
double t2 = omp_get_wtime();
printf( "Single Time is: %lf\n", t2 - t1);
return 0;
}
指令:
parallel :用在一个结构块之前,表示这段代码将被多个线程并行执行;
for:用于for循环语句之前,表示将循环计算任务分配到多个线程中并行执行,以实现任务分担,必须由编程人员自己保证每次循环之间无数据相关性;
parallel for :parallel和for指令的结合,也是用在for循环语句之前,表示for循环体的代码将被多个线程并行执行,它同时具有并行域的产生和任务分担两个功能;
sections :用在可被并行执行的代码段之前,用于实现多个结构块语句的任务分担,可并行执行的代码段各自用section指令标出(注意区分sections和section);
parallel sections:parallel和sections两个语句的结合,类似于parallel for;
single:用在并行域内,表示一段只被单个线程执行的代码;
critical:用在一段代码临界区之前,保证每次只有一个OpenMP线程进入;
flush:保证各个OpenMP线程的数据影像的一致性;
barrier:用于并行域内代码的线程同步,线程执行到barrier时要停下等待,直到所有线程都执行到barrier时才继续往下执行;
atomic:用于指定一个数据操作需要原子性地完成;
master:用于指定一段代码由主线程执行;
threadprivate:用于指定一个或多个变量是线程专用,后面会解释线程专有和私有的区别。
在项目程序已经完成好的情况下不需要大幅度的修改源代码,只需要加上专用的pragma来指明自己的意图,由此编译器可以自动将程序进行并行化,并在必要之处加入同步互斥以及通信。当选择忽略这些pragma,或者编译器不支持OpenMp时,程序又可退化为通常的程序(一般为串行),代码仍然可以正常运作,只是不能利用多线程来加速程序执行。OpenMP提供的这种对于并行描述的高层抽象降低了并行编程的难度和复杂度,这样程序员可以把更多的精力投入到并行算法本身,而非其具体实现细节。对基于数据分集的多线程程序设计,OpenMP是一个很好的选择。
OpenMP支持的语言包括C/C++、Fortran;而支持OpenMP的编译器VS、gcc、clang等都行。可移植性也很好:Unix/Linux和Windows
OpenMP编程模型
内存共享模型:OpenMP是专为多处理器/核,共享内存机器所设计的。底层架构可以是UMA和NUMA。即(Uniform Memory Access和Non-Uniform Memory Access)

基于线程的并行性
- OpenMP仅通过线程来完成并行
- 一个线程的运行是可由操作系统调用的最小处理单
- 线程们存在于单个进程的资源中,没有了这个进程,线程也不存在了
- 通常,线程数与机器的处理器/核数相匹配,然而,实际使用取决与应用程序
明确的并行
- OpenMP是一种显式(非自动)编程模型,为程序员提供对并行化的完全控制
- 一方面,并行化可像执行串行程序和插入编译指令那样简单
- 另一方面,像插入子程序来设置多级并行、锁、甚至嵌套锁一样复杂
Fork-Join模型
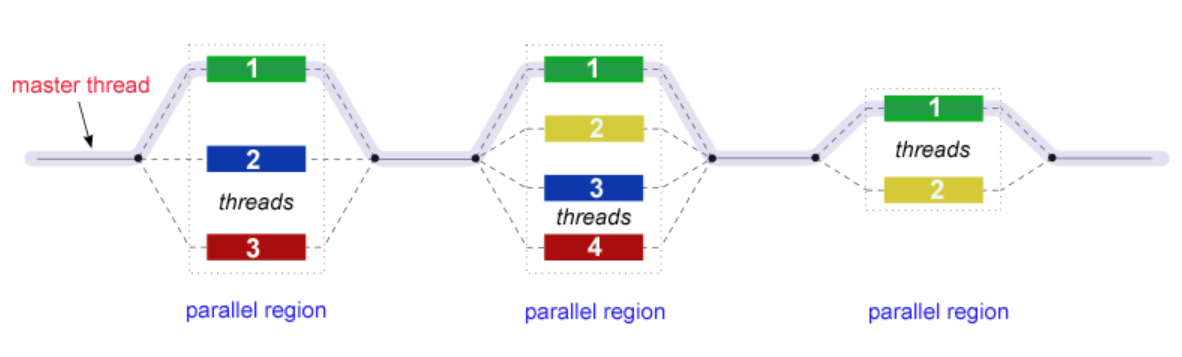
- OpenMP就是采用Fork-Join模型
- 所有的OpenML程序都以一个单个进程——master thread开始,master threads按顺序执行知道遇到第一个并行区域
- Fork:主线程创造一个并行线程组
- Join:当线程组完成并行区域的语句时,它们同步、终止,仅留下主线程
数据范围
- 由于OpenMP时是共享内存模型,默认情况下,在共享区域的大部分数据是被共享的
- 并行区域中的所有线程可以同时访问这个共享的数据
- 如果不需要默认的共享作用域,OpenMP为程序员提供一种“显示”指定数据作用域的方法
嵌套并行
- API提供在其它并行区域放置并行区域
- 实际实现也可能不支持
动态线程
- API为运行环境提供动态的改变用于执行并行区域的线程数
- 实际实现也可能不支持

 浙公网安备 33010602011771号
浙公网安备 33010602011771号