
哈希函数,哈希表理解
学习转自:https://zhuanlan.zhihu.com/p/95156642,感谢作者,本文为个人学习记录!!!
百度百科:
散列表(Hash table,也叫哈希表),是根据键(Key)而直接访问在内存存储位置的数据结构。也就是说,它通过计算一个关于键值的函数,
将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表
哈希表是一种数据结构,它的特点是:可以根据一个key值来直接访问数据,因此查找速度快。
哈希表的本质是数组,它的底层实现是用到了数组,在数组的基础上加工加工,变得更加有特色了,然后人家就自立门户,叫哈希表。
实现hash表的可以采用的两种方法:
1、数组+链表
2、数组+二叉树
数组中一般就是存放的单一的数据,而哈希表中存放的是一个键值对,这是个区别吧
1.散列函数
例:现在给个电话本,上面记录的有姓名和对应的手机号,查找王二的手机号怎么做?
1.暴力解决:枚举查找,找到为止
2.如果这个王二是在最后几页,那前面几页都白找了,是不是可以按照人名给分个类,比如按照首字母来排序,就abcd那样的顺序,这样根据王二我就知道去找w这些,这样就快很多。
按照人名的首字母作出如下表格:
| a | ||
| b | ||
| ... | ||
| w | 王二 | 18896321123 |
以上表格中,王二用w标记,找王二不是直接找而是先去找W,这里通过人名,加工后拿到首字母,这个方法或者这个函数在哈希表中就叫散列函数,其中规定的一些操作就叫函数法则。
2.关键值key
传给散列函数加工的值就是关键值key。
index=Hash(key)
index是哈希表中,数据存放的位置。
3.哈希冲突
w后面同时有王三,王四,而w已经被王二占了。
哈希表
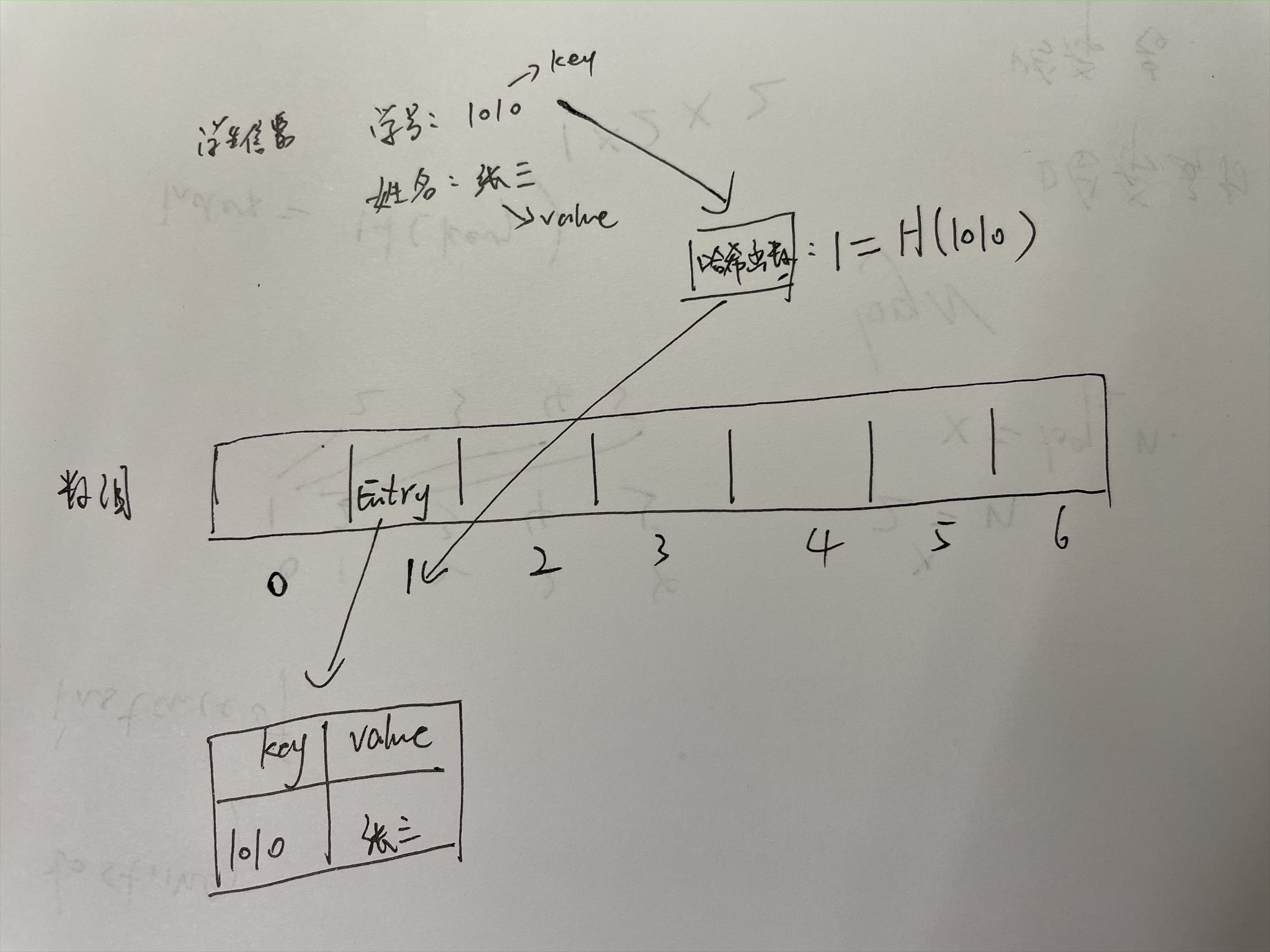
哈希表中存放的是键值对,在哈希表中,是通过哈希函数将一个值映射到另一个值的,x映射到y,x就是key,y就是x的哈希值;
在jdk中键值对,就叫Entry;
哈希表如何存数据
看上面的图,我们已经知道了哈希表本质是个数组,所以这里有个数组,长度是7,现在要做的是把学生信息存放到哈希表中,也就是这个数组中去,需要考虑怎么去存放
这里的学号是个key,哈希表就是根据key值来通过哈希函数计算得到一个值,这个值就是用来确定这个Entry要存放在哈希表中的位置的,实际上这个值就是一个下标值,来确定放在数组的哪个位置上。
比如这里的学号是1010,经过哈希函数的计算之后得到了1,这个1就是告诉我们应该把这个Entry放到数组里的确切位置的下标,也就是需要放在数组中下标为1的位置。
哈希冲突

上面李四的key经过哈希函数处理后,也得到哈希值1,但是下标1的位置已经被张三占用了,这就叫哈希冲突或哈希碰撞,然后要想办法安置李四。
处理哈希冲突
关于哈希冲突的解决办法有好几种,我学习的这片文章只介绍了两种主要的,所以我就先学习这两种,一个是开放寻址法,一个是拉链法
开发寻址法:这里所说的开放寻址法其实简单来说就是,既然位置被占了,那就另外再找个位置不就得了,怎么找其他的位置呢?这里其实也有很多的实现,我们说个最基本的就是既然当前位置被占用了,我们就看看该位置的后一个位置是否可用,也就是1的位置被占用了,我们就看看2的位置,如果没有被占用,那就放到这里呗,当然,也有可能2的位置也被占用了,那咱就继续往下找,看看3的位置,一次类推,直到找到空位置。
不会一直找不到地址,占满的话,会扩容。
拉链法:
拉链法也是比较常用的,HashMap就是使用了这种方法

拉链法还是在该位置,这里采用的是链表,就像图中所示,现在张三和李四都要放在1找个位置上,但是张三先来的,已经占了这个位置,待在了这个位置上了,那李四呢?解决办法就是链表,这时候这个1的位置存放的不单单是之前的那个Entry了,此时的Entry还额外的保存了一个next指针,这个指针指向数组外的另外一个位置,将李四安排在这里,然后张三那个Entry中的next指针就指向李四的这个位置,也就是保存的这个位置的内存地址,如果还有冲突,那就把又冲突的那个Entry放在一个新位置上,然后李四的Entry中的next指向它,这样就形成了一个链表。
如果冲突很多,链表很长,链表会转换结构比如,java集合类中的HashMap,如果这里的链表长度大于等于8的话,链表就会转换成树结构,当然如果长度小于等于6的话,就会还原链表。以此来解决链表过长导致的性能。
哈希表扩容
有一个很重要的原因就是当哈希表被占的位置比较多的时候,出现哈希冲突的概率也就变高了,所以很有必要进行扩容。
那么这个扩容是怎么扩的呢?这里一般会有一个增长因子的概念,也叫作负载因子,简单点说就是已经被占的位置与总位置的一个百分比,比如一共十个位置,现在已经占了七个位置,就触发了扩容机制,因为它的增长因子是0.7,也就是达到了总位置的百分之七十就需要扩容。
而且这个扩容也不是简单的把数组扩大,而是新创建一个数组是原来的2倍,然后把原数组的所有Entry都重新Hash一遍放到新的数组。因为数组扩大了,所以一般哈希函数也会有变化,这里的Hash也就是把之前的数据通过新的哈希函数计算出新的位置来存放。
哈希表如何读取数据
比如我们现在要通过学号1011来查找学生的姓名,怎么操作呢?我们首先通过学号利用哈希函数得出位置1,然后我们就去位置1拿数据啊,拿到这个Entry之后我们得看看这个Entry的key是不是我们的学号1011,一看是1010,什么鬼,一边去,这不是我们要的key啊,然后根据这个Entry的next知道下一给位置,在比较key,好成功找到李四。
哈希函数是核心
在哈希表中,哈希函数的设计很重要,一个好的哈希函数可以极大的提升性能,而且如果你的哈希函数设计的比较简单粗陋,那很容易被那些不怀好意的人捣乱,比如知道了你哈希函数的规则,故意制造容易冲突的key值,那就有意思了,你的哈希表就会一直撞啊,一直撞啊
设计哈希函数的方法:直接定址法,数字分析法,折叠法,随机数法和除留余数法等等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号