
个人项目:论文查重
|作业所属课程|https://edu.cnblogs.com/campus/gdgy/Networkengineering1834|
|---|---|---|
|作业要求|https://edu.cnblogs.com/campus/gdgy/Networkengineering1834/homework/11146|
|作业目标|实现一个论文查重小程序,并运用软件工程的思维分析和开发|
一、github仓库
https://github.com/Jammillk/sorewareEngineer
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 25 |
| Estimate | 估计这个任务需要多少时间 | 5 | 5 |
| Development | 开发 | 380 | 420 |
| Analysis | 需求分析 (包括学习新技术) | 40 | 60 |
| Design Spec | 生成设计文档 | 10 | 20 |
| Design Review | 设计复审 | 10 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| Design | 具体设计 | 30 | 30 |
| Coding | 具体编码 | 150 | 200 |
| Code Review | 代码复审 | 30 | 20 |
| Test | 测试(自我测试,修改代码,提交修改) | 20 | 35 |
| Reporting | 报告 | 60 | 90 |
| Test Repor | 测试报告 | 15 | 15 |
| Size Measurement | 计算工作量 | 5 | 5 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 30 |
| 合计 | 815 | 985 |
三、计算模块接口的设计与实现过程
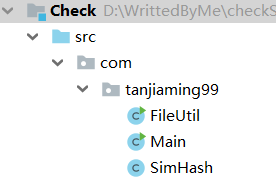
本程序一共有三个类,包含了运行的主入口Main,读写文件的工具类FileUtil,还有查重算法的核心类SimHash。类图结构如下:
核心的SimHash算法来自于GoogleMoses Charikar发表的一篇论文“detecting near-duplicates for web crawling”,它专门用来解决亿万级别的网页的去重任务。
simhash作为locality sensitive hash(局部敏感哈希)的一种:其主要思想是降维,将高维的特征向量映射成低维的特征向量,通过两个向量的Hamming Distance来确定文章是否重复或者高度近似。
其中,Hamming Distance,又称汉明距离,在信息论中,两个等长字符串之间的汉明距离是两个字符串对应位置的不同字符的个数。也就是说,它就是将一个字符串变换成另外一个字符串所需要替换的字符个数。例如:1011101 与 1001001 之间的汉明距离是 2。至于我们常说的字符串编辑距离则是一般形式的汉明距离。
通过比较多个文档的simHash值的汉明距离,可以获取它们的相似度。
四、计算模块接口部分的性能改进。
下面是用JProfile测试得到的结果图。
五、测试相关
程序总量不大,直接采用main方法进行各部分的测试。
FileUtil中,测试写入写出文件。
public static void main(String[] args) {
StringBuffer sb = FileUtil.readTxt("D:\\WrittedByMe\\checkSameProgram\\cheak\\Check\\txtFile\\orig.txt");
System.out.println(sb.toString());
}
结果,成功读出文件。

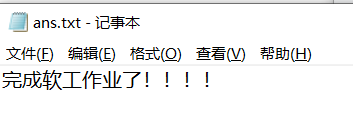
public static void main(String[] args) {
String txtPath = "D:\\ans.txt";
String content = "完成软工作业了!!!!";
writeTxt(txtPath, content);
}
查看D盘的ans.txt文件,可知写入成功。
对于异常处理,可try-catch捕获处理,比如下面例出来的是Main类中对Scanner类的异常处理。
例如文件读写等类,也有类似的操作,不在此一一列举。
try(Scanner scanner = new Scanner(System.in)){
...
}catch (NullPointerException e1) {
System.out.println("输入路径错误或者文件不存在!");
e1.printStackTrace();
} catch (Exception e) {
System.out.println("输入错误导致程序出错!");
e.printStackTrace();
}
六、测试结果
下面对给定文章进行查重处理。
Main中采用的是输入两文章的目录,然后程序就会自动比较,并得出结果。
控制台会输出结果,同时也会出现在硬盘中,我设置的路径是D盘的ans.txt文件。
下面测试orig.txt和orig2.txt的比较。
请输入待检验文章的绝对路径:D:\WrittedByMe\checkSameProgram\cheak\Check\txtFile\orig2.txt
请输入论文原文的绝对路径:D:\WrittedByMe\checkSameProgram\cheak\Check\txtFile\orig.txt
hash1和hash2的相似率:1.00
可以看到文件ans.txt中正常输出了结果。

下面测试orig.txt和orig_0.8_add.txt的比较。
请输入待检验文章的绝对路径:D:\WrittedByMe\checkSameProgram\cheak\Check\txtFile\orig_0.8_add.txt
请输入论文原文的绝对路径:D:\WrittedByMe\checkSameProgram\cheak\Check\txtFile\orig.txt
hash1和hash2的相似率:0.88
下面测试orig_0.8_dis_1.txt和orig_0.8_dis_10.txt的比较。
请输入待检验文章的绝对路径:D:\WrittedByMe\checkSameProgram\cheak\Check\txtFile\orig_0.8_dis_10.txt
请输入论文原文的绝对路径:D:\WrittedByMe\checkSameProgram\cheak\Check\txtFile\orig_0.8_dis_1.txt
hash1和hash2的相似率:0.75
七、结论
总的来说,这个论文查重小软件的准确率还是很高的,既利益于SimHash算法的准确,也有软件正确开发的结果。
这次作业学习到了很多,希望以后还能继续学习。
