Mysql索引之全文检索FullText
背景介绍
上一篇文章<Mysql为什么使用B+树做索引>中有介绍Mysql中的所有索引类型,当时简单说了一下FullText index,因本人实际开发未用到且水平有限,当时就没有过多介绍。
最近有一个需求,从一段文本中查询是否包含某字段及该字段出现的次数。
我的思路如下:查询是否存在某个字段那就需要模糊查询了,匹配到就表示该文本包含指定字段,否则就不存在;如何实现统计该字段出现的次数呢?借鉴<在 SQL 中计算字符串出现次数>的思想--将文本中匹配到的字段转换成“”,然后(原文本长度-替换后的文本长度)/匹配字段长度这样就得到该字符串出现的次数。
方案确定后就该进行验证了,整体的SQL几存储过程写起来没什么问题,首先插入100条数据,查询效率还可以。通过explain可以很明显知道“%***%”压根就没走索引,直接全文检索了。
然后又往数据库插入了9900条数据,这一次查询效率明显慢了。当我将数据量加到20W条时吓我一跳,查询居然花了20S+,这可不行喏。要是用这种方式去实现,一上线不得被辞退啊。于是转移目标,全文检索热搜榜一哥不是大名鼎鼎的ES(elasticsearch)吗?网上各类文档一搜一大堆,表示目前技术已经非常成熟,社区也比较活跃。一拍脑袋准备用它了,但是刚准备开始coding,被领导叫停了,理由是:就一个简单的需求,引入这么一个中间件,开发时间成本加大了;后期维护的员工不一定知道ES相关知识。我给领导解释了一通ES在全文检索方面的优势,可领导仍旧坚持,我可奈何只能放弃这条路,所以只能将目标放到sql索引/函数上了。
索引??前段时间写博客不久介绍过嘛?FullText(全文检索索引),但是我还说实际开发用到很少,现阶段全文检索方案太多了,谁还想用SQL自带的全文检索索引。这一下打脸来的不要太快。个人觉得当前也只有这一条路能走了,说lucene的同学请出门右转。
全文搜索
全文搜索(Full-Text Search)是将存储于数据库中的整本书或整篇文章中的任意信息查找出来的技术。它可以根据需要获得全文中有关章、节、段、句、词等信息,也可以进行各种统计和分析。在早期的 MySQL 中,InnoDB 并不支持全文检索技术,从 MySQL 5.6 开始,InnoDB 开始支持全文检索。它们的索引建立都是根据倒排索引的方式生成索引
倒排索引
倒排索引(英语:Inverted index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构,通常利用关联数组实现,拥有两种表现形式:
- inverted file index:{单词,单词所在文档的id}
- full inverted index:{单词,(单词所在文档的id,再具体文档中的位置)}
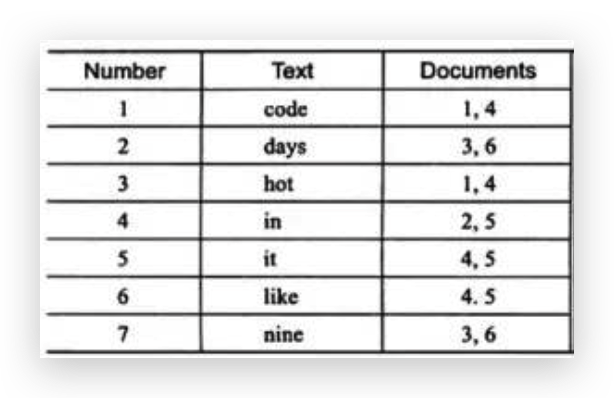
inverted file index
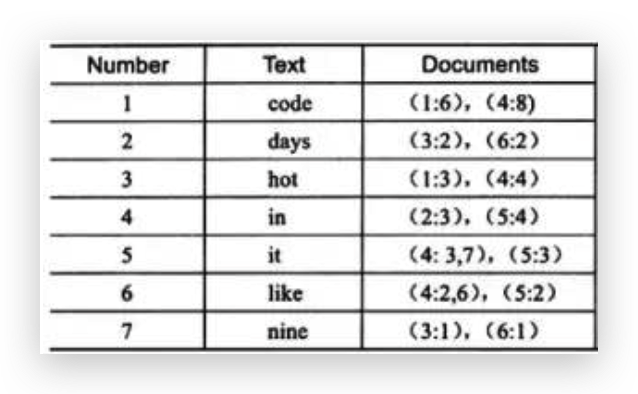
full inverted index
inverted file index 图中可以看到其中单词"code"存在于文档1,4中,这样存储再进行全文查询就简单了,可以直接根据 Documents 得到包含查询关键字的文档;
而 full inverted index 存储的是对,即(DocumentId,Position),如关键字"code"存在于文档1的第6个单词和文档4的第8个单词。相比之下,full inverted index 占用了更多的空间,但是能更好的定位数据,并扩充一些其他搜索特性。
创建全文索引
1、创建表时创建全文索引语法如下:
CREATE TABLE table_name ( id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY, author VARCHAR(200), title VARCHAR(200), content TEXT(500), FULLTEXT full_index_name (col_name) ) ENGINE=InnoDB;
2、在已创建的表上创建全文索引语法如下:
CREATE FULLTEXT INDEX full_index_name ON table_name(col_name);
输入查询语句:
SELECT table_id, name, space from INFORMATION_SCHEMA.INNODB_TABLES WHERE name LIKE 'test/%';
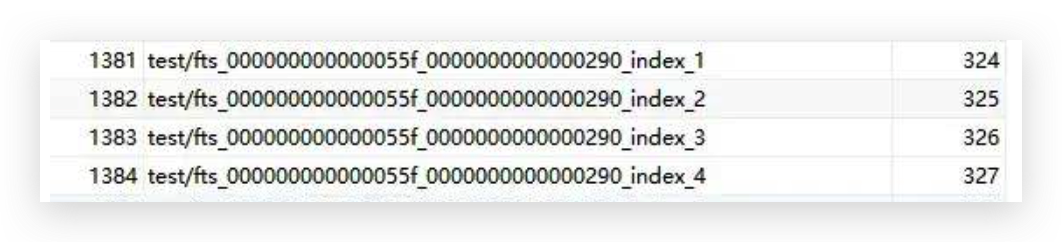
上述四个索引表构成倒排索引,称为辅助索引表。当传入的文档被标记化时,单个词与位置信息和关联的DOC_ID,根据单词的第一个字符的字符集排序权重,在六个索引表中对单词进行完全排序和分区。
使用全文索引
MySQL 数据库支持全文检索的查询,全文索引只能在 InnoDB 或 MyISAM 的表上使用,并且只能用于创建 char,varchar,text 类型的列。其语法如下:
MATCH(col1,col2,...) AGAINST(expr[search_modifier]) search_modifier: { IN NATURAL LANGUAGE MODE | IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION | IN BOOLEAN MODE | WITH QUERY EXPANSION }
全文搜索使用?`MATCH() AGAINST()`语法进行,其中,MATCH() 采用逗号分隔的列表,命名要搜索的列。AGAINST()接收一个要搜索的字符串,以及一个要执行的搜索类型的可选修饰符。全文检索分为三种类型:自然语言搜索、布尔搜索、查询扩展搜索。详情请参考:MySQL模糊查询再也不用like+%了。
总结
有了以上的理论知识,要实现上面说的统计文本中是否存在某一字断及字段出现的次数就方便很多了。
SELECT count(IF(MATCH ( title, body ) against ( 'MySQL' ), 1, NULL )) AS count FROM `fts_articles`;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号