DataX学习指南(二)--插件开发
DataX为什么采用插件机制?
从设计之初,DataX就把异构数据源同步作为自身的使命,为了应对不同数据源的差异、同时提供一致的同步原语和扩展能力,DataX自然而然地采用了框架 + 插件 的模式:
- 插件只需关心数据的读取或者写入本身。
- 而同步的共性问题,比如:类型转换、性能、统计,则交由框架来处理。
作为插件开发人员,则需要关注两个问题:
- 数据源本身的读写数据正确性。
- 如何与框架沟通、合理正确地使用框架。
插件是如何加载的?
框架是怎么找到插件的入口类的?框架是如何加载插件的呢?
在每个插件的项目中,都有一个plugin.json文件,这个文件定义了插件的相关信息,包括入口类。例如:
{
"name": "mysqlwriter",
"class": "com.alibaba.datax.plugin.writer.mysqlwriter.MysqlWriter",
"description": "Use Jdbc connect to database, execute insert sql.",
"developer": "alibaba"
}
name: 插件名称,大小写敏感。框架根据用户在配置文件中指定的名称来搜寻插件。 十分重要 。class: 入口类的全限定名称,框架通过反射插件入口类的实例。十分重要 。description: 描述信息。developer: 开发人员。
如何编写插件?
插件开发者不用关心太多,基本只需要关注特定系统读和写,以及自己的代码在逻辑上是怎样被执行的,哪一个方法是在什么时候被调用的。在此之前,需要明确以下概念:
Job:Job是DataX用以描述从一个源头到一个目的端的同步作业,是DataX数据同步的最小业务单元。比如:从一张mysql的表同步到odps的一个表的特定分区。Task:Task是为最大化而把Job拆分得到的最小执行单元。比如:读一张有1024个分表的mysql分库分表的Job,拆分成1024个读Task,用若干个并发执行。TaskGroup: 描述的是一组Task集合。在同一个TaskGroupContainer执行下的Task集合称之为TaskGroupJobContainer:Job执行器,负责Job全局拆分、调度、前置语句和后置语句等工作的工作单元。类似Yarn中的JobTrackerTaskGroupContainer:TaskGroup执行器,负责执行一组Task的工作单元,类似Yarn中的TaskTracker。
简而言之, Job拆分成Task,在分别在框架提供的容器中执行,插件只需要实现Job和Task两部分逻辑。(框架体系介绍见DataX学习指南(一)--基础介绍)
定制插件开发(二次开发)
在进行二次开发之前,需要到GitHub上下载源码。开发前将datax的开发插件的手册认真观看一遍,对开发有帮助的。地址:https://github.com/alibaba/DataX/blob/master/dataxPluginDev.md
下载完后,通过ideaJ打开,目录结构如下(标准的分布式包结构),然后就是漫长的导包过程。
通过上面的目录结构,每类数据源都存在一对Readere和Writer。这些是开源项目已经写好的,如我们需要二次开发,最方便的就是借鉴已有的业务逻辑,然后根据时间需求定制开发reader/writer(并非每次都得同时开发reader/writer)。
新建一个模块,比如我这叫testreader,然后从其他模块复制plugin.json和plugin_job_template.json这两个文件,并做对应修改。(我这里reader实现的是从文本读取内容)
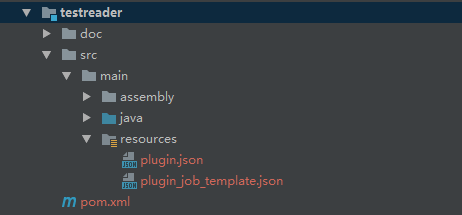

然后就是引入pom.xml文件,可以将任意一个项目的pom文件复制过来,然后根据自己的时间使用情况,修改/引入自己所需的依赖文件。最后将本模块加入到datax的父pom文件。
Reader/Job内方法的介绍在插件开发手册介绍得很详细了,这里我就不累述了,直接贴上开发的TestReader
package com.alibaba.datax.plugin.reader.testreader; import com.alibaba.datax.common.exception.DataXException; import com.alibaba.datax.common.plugin.RecordSender; import com.alibaba.datax.common.spi.Reader; import com.alibaba.datax.common.util.Configuration; import com.alibaba.datax.plugin.unstructuredstorage.reader.UnstructuredStorageReaderErrorCode; import com.alibaba.datax.plugin.unstructuredstorage.reader.UnstructuredStorageReaderUtil; import com.google.common.collect.Sets; import org.apache.commons.io.Charsets; import org.apache.commons.io.IOUtils; import org.apache.commons.lang3.BooleanUtils; import org.apache.commons.lang3.StringUtils; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.InputStream; import java.nio.charset.UnsupportedCharsetException; import java.util.ArrayList; import java.util.Arrays; import java.util.HashMap; import java.util.HashSet; import java.util.List; import java.util.Map; import java.util.Set; import java.util.regex.Pattern; /** * jackpot */ public class TestReader extends Reader { public static class Job extends Reader.Job { private static final Logger LOG = LoggerFactory.getLogger(Job.class); private Configuration originConfig = null; private List<String> path = null; private List<String> sourceFiles; private Map<String, Pattern> pattern; private Map<String, Boolean> isRegexPath; @Override public void init() { this.originConfig = this.getPluginJobConf(); this.pattern = new HashMap<String, Pattern>(); this.isRegexPath = new HashMap<String, Boolean>(); this.validateParameter(); } private void validateParameter() { // Compatible with the old version, path is a string before String pathInString = this.originConfig.getNecessaryValue(Key.PATH, TxtFileReaderErrorCode.REQUIRED_VALUE); if (StringUtils.isBlank(pathInString)) { throw DataXException.asDataXException( TxtFileReaderErrorCode.REQUIRED_VALUE, "您需要指定待读取的源目录或文件"); } if (!pathInString.startsWith("[") && !pathInString.endsWith("]")) { path = new ArrayList<String>(); path.add(pathInString); } else { path = this.originConfig.getList(Key.PATH, String.class); if (null == path || path.size() == 0) { throw DataXException.asDataXException( TxtFileReaderErrorCode.REQUIRED_VALUE, "您需要指定待读取的源目录或文件"); } } String encoding = this.originConfig .getString( com.alibaba.datax.plugin.unstructuredstorage.reader.Key.ENCODING, com.alibaba.datax.plugin.unstructuredstorage.reader.Constant.DEFAULT_ENCODING); if (StringUtils.isBlank(encoding)) { this.originConfig .set(com.alibaba.datax.plugin.unstructuredstorage.reader.Key.ENCODING, com.alibaba.datax.plugin.unstructuredstorage.reader.Constant.DEFAULT_ENCODING); } else { try { encoding = encoding.trim(); this.originConfig .set(com.alibaba.datax.plugin.unstructuredstorage.reader.Key.ENCODING, encoding); Charsets.toCharset(encoding); } catch (UnsupportedCharsetException uce) { throw DataXException.asDataXException( TxtFileReaderErrorCode.ILLEGAL_VALUE, String.format("不支持您配置的编码格式 : [%s]", encoding), uce); } catch (Exception e) { throw DataXException.asDataXException( TxtFileReaderErrorCode.CONFIG_INVALID_EXCEPTION, String.format("编码配置异常, 请联系我们: %s", e.getMessage()), e); } } // column: 1. index type 2.value type 3.when type is Date, may have // format List<Configuration> columns = this.originConfig .getListConfiguration(com.alibaba.datax.plugin.unstructuredstorage.reader.Key.COLUMN); // handle ["*"] if (null != columns && 1 == columns.size()) { String columnsInStr = columns.get(0).toString(); if ("\"*\"".equals(columnsInStr) || "'*'".equals(columnsInStr)) { this.originConfig .set(com.alibaba.datax.plugin.unstructuredstorage.reader.Key.COLUMN, null); columns = null; } } if (null != columns && columns.size() != 0) { for (Configuration eachColumnConf : columns) { eachColumnConf .getNecessaryValue( com.alibaba.datax.plugin.unstructuredstorage.reader.Key.TYPE, TxtFileReaderErrorCode.REQUIRED_VALUE); Integer columnIndex = eachColumnConf .getInt(com.alibaba.datax.plugin.unstructuredstorage.reader.Key.INDEX); String columnValue = eachColumnConf .getString(com.alibaba.datax.plugin.unstructuredstorage.reader.Key.VALUE); if (null == columnIndex && null == columnValue) { throw DataXException.asDataXException( TxtFileReaderErrorCode.NO_INDEX_VALUE, "由于您配置了type, 则至少需要配置 index 或 value"); } if (null != columnIndex && null != columnValue) { throw DataXException.asDataXException( TxtFileReaderErrorCode.MIXED_INDEX_VALUE, "您混合配置了index, value, 每一列同时仅能选择其中一种"); } if (null != columnIndex && columnIndex < 0) { throw DataXException.asDataXException( TxtFileReaderErrorCode.ILLEGAL_VALUE, String .format("index需要大于等于0, 您配置的index为[%s]", columnIndex)); } } } // only support compress types String compress = this.originConfig .getString(com.alibaba.datax.plugin.unstructuredstorage.reader.Key.COMPRESS); if (StringUtils.isBlank(compress)) { this.originConfig .set(com.alibaba.datax.plugin.unstructuredstorage.reader.Key.COMPRESS, null); } else { Set<String> supportedCompress = Sets .newHashSet("gzip", "bzip2", "zip"); compress = compress.toLowerCase().trim(); if (!supportedCompress.contains(compress)) { throw DataXException .asDataXException( TxtFileReaderErrorCode.ILLEGAL_VALUE, String.format( "仅支持 gzip, bzip2, zip 文件压缩格式 , 不支持您配置的文件压缩格式: [%s]", compress)); } this.originConfig .set(com.alibaba.datax.plugin.unstructuredstorage.reader.Key.COMPRESS, compress); } String delimiterInStr = this.originConfig .getString(com.alibaba.datax.plugin.unstructuredstorage.reader.Key.FIELD_DELIMITER); // warn: if have, length must be one if (null != delimiterInStr && 1 != delimiterInStr.length()) { throw DataXException.asDataXException( UnstructuredStorageReaderErrorCode.ILLEGAL_VALUE, String.format("仅仅支持单字符切分, 您配置的切分为 : [%s]", delimiterInStr)); } } @Override public void prepare() { LOG.debug("prepare() begin..."); // warn:make sure this regex string // warn:no need trim for (String eachPath : this.path) { String regexString = eachPath.replace("*", ".*").replace("?", ".?"); Pattern patt = Pattern.compile(regexString); this.pattern.put(eachPath, patt); this.sourceFiles = this.buildSourceTargets(); } LOG.info(String.format("您即将读取的文件数为: [%s]", this.sourceFiles.size())); } @Override public void post() { } @Override public void destroy() { } // warn: 如果源目录为空会报错,拖空目录意图=>空文件显示指定此意图 @Override public List<Configuration> split(int adviceNumber) { LOG.debug("split() begin..."); List<Configuration> readerSplitConfigs = new ArrayList<Configuration>(); // warn:每个slice拖且仅拖一个文件, // int splitNumber = adviceNumber; int splitNumber = this.sourceFiles.size(); if (0 == splitNumber) { throw DataXException.asDataXException( TxtFileReaderErrorCode.EMPTY_DIR_EXCEPTION, String .format("未能找到待读取的文件,请确认您的配置项path: %s", this.originConfig.getString(Key.PATH))); } List<List<String>> splitedSourceFiles = this.splitSourceFiles( this.sourceFiles, splitNumber); for (List<String> files : splitedSourceFiles) { Configuration splitedConfig = this.originConfig.clone(); splitedConfig.set(Constant.SOURCE_FILES, files); readerSplitConfigs.add(splitedConfig); } LOG.debug("split() ok and end..."); return readerSplitConfigs; } // validate the path, path must be a absolute path private List<String> buildSourceTargets() { // for eath path Set<String> toBeReadFiles = new HashSet<String>(); for (String eachPath : this.path) { int endMark; for (endMark = 0; endMark < eachPath.length(); endMark++) { if ('*' != eachPath.charAt(endMark) && '?' != eachPath.charAt(endMark)) { continue; } else { this.isRegexPath.put(eachPath, true); break; } } String parentDirectory; if (BooleanUtils.isTrue(this.isRegexPath.get(eachPath))) { int lastDirSeparator = eachPath.substring(0, endMark) .lastIndexOf(IOUtils.DIR_SEPARATOR); parentDirectory = eachPath.substring(0, lastDirSeparator + 1); } else { this.isRegexPath.put(eachPath, false); parentDirectory = eachPath; } this.buildSourceTargetsEathPath(eachPath, parentDirectory, toBeReadFiles); } return Arrays.asList(toBeReadFiles.toArray(new String[0])); } private void buildSourceTargetsEathPath(String regexPath, String parentDirectory, Set<String> toBeReadFiles) { // 检测目录是否存在,错误情况更明确 try { File dir = new File(parentDirectory); boolean isExists = dir.exists(); if (!isExists) { String message = String.format("您设定的目录不存在 : [%s]", parentDirectory); LOG.error(message); throw DataXException.asDataXException( TxtFileReaderErrorCode.FILE_NOT_EXISTS, message); } } catch (SecurityException se) { String message = String.format("您没有权限查看目录 : [%s]", parentDirectory); LOG.error(message); throw DataXException.asDataXException( TxtFileReaderErrorCode.SECURITY_NOT_ENOUGH, message); } directoryRover(regexPath, parentDirectory, toBeReadFiles); } private void directoryRover(String regexPath, String parentDirectory, Set<String> toBeReadFiles) { File directory = new File(parentDirectory); // is a normal file if (!directory.isDirectory()) { if (this.isTargetFile(regexPath, directory.getAbsolutePath())) { toBeReadFiles.add(parentDirectory); LOG.info(String.format( "add file [%s] as a candidate to be read.", parentDirectory)); } } else { // 是目录 try { // warn:对于没有权限的目录,listFiles 返回null,而不是抛出SecurityException File[] files = directory.listFiles(); if (null != files) { for (File subFileNames : files) { directoryRover(regexPath, subFileNames.getAbsolutePath(), toBeReadFiles); } } else { // warn: 对于没有权限的文件,是直接throw DataXException String message = String.format("您没有权限查看目录 : [%s]", directory); LOG.error(message); throw DataXException.asDataXException( TxtFileReaderErrorCode.SECURITY_NOT_ENOUGH, message); } } catch (SecurityException e) { String message = String.format("您没有权限查看目录 : [%s]", directory); LOG.error(message); throw DataXException.asDataXException( TxtFileReaderErrorCode.SECURITY_NOT_ENOUGH, message, e); } } } // 正则过滤 private boolean isTargetFile(String regexPath, String absoluteFilePath) { if (this.isRegexPath.get(regexPath)) { return this.pattern.get(regexPath).matcher(absoluteFilePath) .matches(); } else { return true; } } private <T> List<List<T>> splitSourceFiles(final List<T> sourceList, int adviceNumber) { List<List<T>> splitedList = new ArrayList<List<T>>(); int averageLength = sourceList.size() / adviceNumber; averageLength = averageLength == 0 ? 1 : averageLength; for (int begin = 0, end = 0; begin < sourceList.size(); begin = end) { end = begin + averageLength; if (end > sourceList.size()) { end = sourceList.size(); } splitedList.add(sourceList.subList(begin, end)); } return splitedList; } } public static class Task extends Reader.Task { private static Logger LOG = LoggerFactory.getLogger(Task.class); private Configuration readerSliceConfig; private List<String> sourceFiles; @Override public void init() { this.readerSliceConfig = this.getPluginJobConf(); this.sourceFiles = this.readerSliceConfig.getList( Constant.SOURCE_FILES, String.class); } @Override public void prepare() { } @Override public void post() { } @Override public void destroy() { } @Override public void startRead(RecordSender recordSender) { LOG.debug("start read source files..."); for (String fileName : this.sourceFiles) { LOG.info(String.format("reading file : [%s]", fileName)); InputStream inputStream; try { inputStream = new FileInputStream(fileName); UnstructuredStorageReaderUtil.readFromStream(inputStream, fileName, this.readerSliceConfig, recordSender, this.getTaskPluginCollector()); recordSender.flush(); } catch (FileNotFoundException e) { // warn: sock 文件无法read,能影响所有文件的传输,需要用户自己保证 String message = String .format("找不到待读取的文件 : [%s]", fileName); LOG.error(message); throw DataXException.asDataXException( TxtFileReaderErrorCode.OPEN_FILE_ERROR, message); } } LOG.debug("end read source files..."); } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号