DataX学习指南(一)--基础介绍
what IS DataX ?
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、SQL Server、Oracle、PostgreSQL、HDFS、Hive、HBase、OTS、ODPS 等各种异构数据源之间高效的数据同步功能。
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。
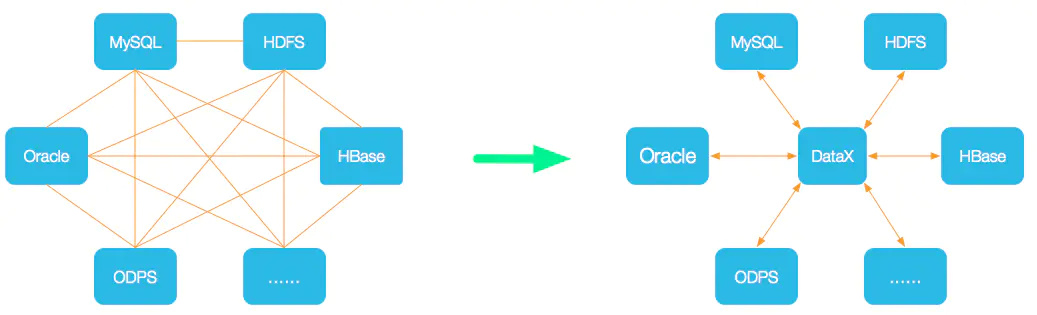
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
该项目完全开源,目前最新的开源版本为DataX 3.0。Github主页地址:https://github.com/alibaba/DataX
DataX3.0框架设计
 (图片来自GitHub)
(图片来自GitHub)
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
核心介绍:
- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。比如mysqlreader就是读取mysql数据库内的数据。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。比如hdfswriter则为将处理后的数据存入hdfs。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控(路由策略),并发,数据转换等核心技术问题。
DataX3.0核心架构

核心模块介绍:
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
DataX 3.0几大核心优势
- 简单易用
- 容错机制健壮
- 同步性能优越
- 数据转换类型丰富
- 运行效率监控精准
详细介绍可以见:DataX 3.0优势
DataX 效果展示
这里先贴一张本地运行结果的截图吧,具体如何实现下文再讲。

运行结果包含了很多内容(截图为运行成功后的最后两部分),简单介绍下这两部分的意义吧。
上面打印了系统整体CPU及GC信息,最后面打印的是整个Job的生命周期--开始、结束、总耗时、同步数据量、失败数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号